







实例分割属于比较challenging的任务,他相当于是object detection和semantic segmentation的结合体。在SOLO出现之前,有两种常用的paradigm:(1)top-down:先进行目标检测,再对检测框做分割,经典的方法有Mask RCNN、PANet、TensorMask等;(2)bottom-up:让每一个像素学习到一个embedding,拉近相同instance像素之间的embedding的距离,推远不同instance像素之间embedding的距离,最后根据embedding之间的距离进行cluster。
而这两种范式都显得indirect,前者需要较高的检测精度,后者需要有较好的embedding的学习,这都稍都影响了实例分割的效果。因此本文提出的SOLO可谓打破陈规之举,因为他实现了之间端到端预测instance mask的功能。也就是说,输入是一张image,直接输出instance mask以及对应的类别,整个过程属于box-free和grouping-free的范式。
作者在研究SOLO时对instance之间的差别进行了rethinking。通过对所有的annotation统计发现:98.3%的instance质心相隔超过30个pixel,而剩下的1.7%中,大小比例超过1.5的占据了40.5%。也就是说,instance的不同完全可以归结于两个因素:(1)Location;(2)Size。
(1)对于Location的考虑:把image分成 S ∗ S S*S S∗S 个cell,每一个cell负责预测1个instance。当一个实例落入某个cell,则该cell负责预测该instance;(2)对于Size的考虑:采用FPN结构来适用于不同尺度的instance。
下图是整个SOLO网络结构示意图:
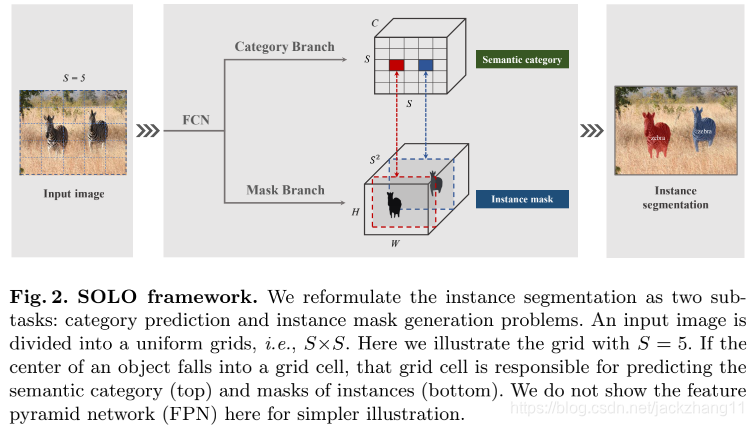
输入为一张image,通过FCN进行多尺度的特征提取,得到多尺度的feature map。随后接入两个分支:(1)分类分支:最后的输出是 S ∗ S ∗ C S*S*C S∗S∗C 维度的矩阵,这里 C 表示总类别数,表示着总共 S ∗ S S*S S∗<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









