







 该专栏为热销专栏榜 第14名
该专栏为热销专栏榜 第14名 本文介绍了华为最新发布的VanillaNet,一种追求简洁和效率的神经网络架构,用于替换YOLOv8的Backbone。VanillaNet通过深度训练策略和串联激活函数提高性能,实现在大目标和小目标检测上的性能提升。文章详细阐述了VanillaNet的原理,提供核心代码,并指导读者如何将其添加到YOLOv8网络中,包括多个修改步骤。
本文介绍了华为最新发布的VanillaNet,一种追求简洁和效率的神经网络架构,用于替换YOLOv8的Backbone。VanillaNet通过深度训练策略和串联激活函数提高性能,实现在大目标和小目标检测上的性能提升。文章详细阐述了VanillaNet的原理,提供核心代码,并指导读者如何将其添加到YOLOv8网络中,包括多个修改步骤。
一、本文介绍
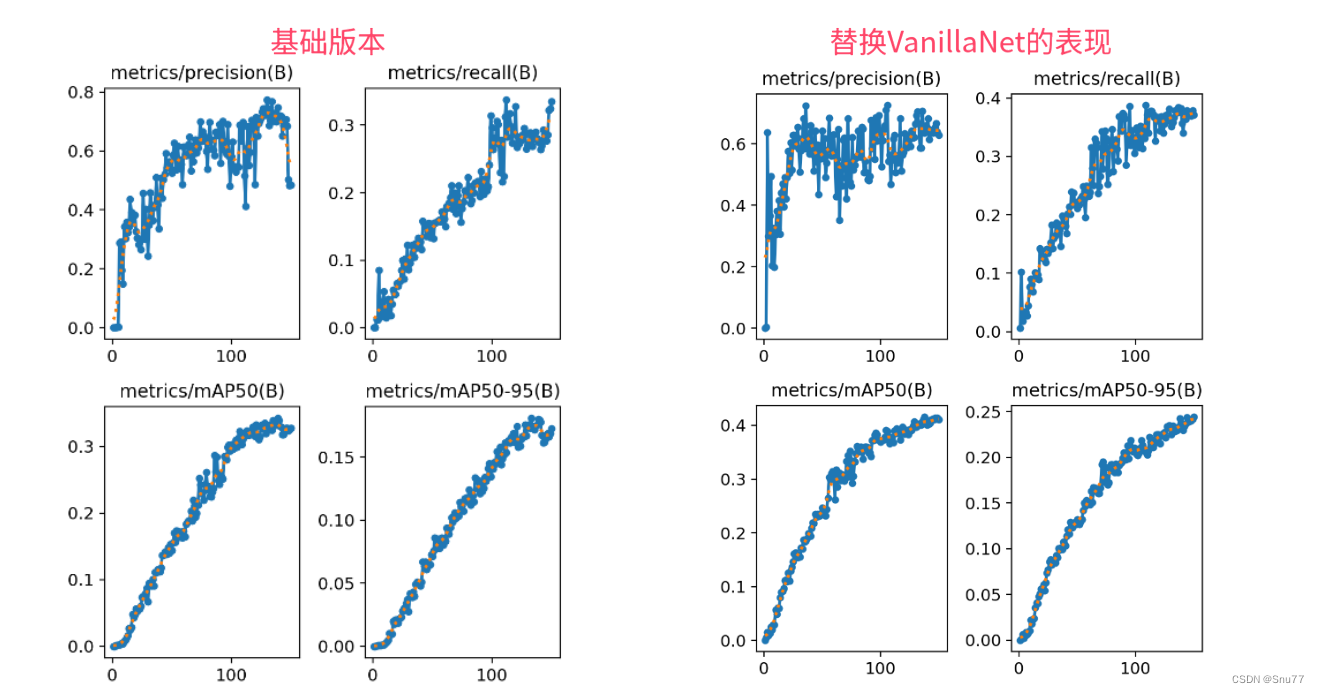
本文给大家来的改进机制是华为最新VanillaNet网络,其是今年最新推出的主干网络,VanillaNet是一种注重极简主义和效率的神经网络架构。它的设计简单,层数较少,避免了像深度架构和自注意力这样的复杂操作(需要注意的是该网络结构的通道数会被放大,GFLOPs的量会很高)。我将其替换整个YOLOv8的Backbone,在一些大目标和小目标检测上均有涨点,效果比上一篇RepViT的效果要好。我的实验数据集是一个包含1000张图片包含大中小的检测目标的数据集上(共有20+类别),下面我会附上基础版本和修改版本的训练对比图,同时我会手把手教你添加该网络结构。
推荐指数:⭐⭐⭐⭐⭐
目录

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











