







 本文深入介绍了YOLOv5中GAM、CBAM、CA和ECA四种注意力机制,包括它们的核心代码和在模型中的应用方法。通过这些机制,可以提升模型的表示能力和性能,尤其在通道和空间注意力方面。此外,还详细讲解了如何将这些机制添加到YOLOv5模型中,提供yaml文件配置示例,适合开发者参考实践。
本文深入介绍了YOLOv5中GAM、CBAM、CA和ECA四种注意力机制,包括它们的核心代码和在模型中的应用方法。通过这些机制,可以提升模型的表示能力和性能,尤其在通道和空间注意力方面。此外,还详细讲解了如何将这些机制添加到YOLOv5模型中,提供yaml文件配置示例,适合开发者参考实践。
一、本文介绍
这篇文章给大家带来的改进机制是一个汇总篇,包含一些简单的注意力机制,本来一直不想发这些内容的(网上教程太多了,发出来增加文章数量也没什么意义),但是群内的读者很多都问我这些机制所以单独出一期视频来汇总一些比较简单的注意力机制添加的方法和使用教程,本文的内容不会过度的去解释原理,更多的是从从代码的使用上和实用的角度出发去写这篇教程。
欢迎大家订阅我的专栏一起学习YOLO!
目录
二、GAM
2.1 GAM的介绍
 官方论文地址: 官方论文地址点击此处即可跳转
官方论文地址: 官方论文地址点击此处即可跳转
官方代码地址: 官方代码地址点击此处即可跳转

简单介绍:GAM旨在通过设计一种机制,减少信息损失并放大全局维度互动特征,从而解决传统注意力机制在通道和空间两个维度上保留信息不足的问题。GAM采用了顺序的通道-空间注意力机制,并对子模块进行了重新设计。具体来说,通道注意力子模块使用3D排列来跨三个维度保留信息,并通过一个两层的MLP增强跨维度的通道-空间依赖性。在空间注意力子模块中,为了更好地关注空间信息,采用了两个卷积层进行空间信息融合,同时去除了可能导致信息减少的最大池化操作,通过使用分组卷积和通道混洗在ResNet50中避免参数数量显著增加。GAM在不同的神经网络架构上稳定提升性能,特别是对于ResNet18,GAM以更少的参数和更好的效率超过了ABN,其简单原理结构图如下所示。
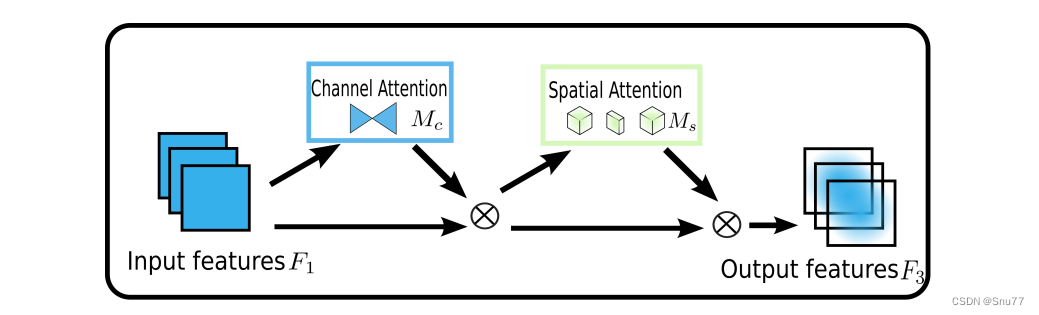
2.2 GAM的核心代码
import torch
import torch.nn as nn
'''
https://arxiv.org/abs/2112.05561
'''
class GAM(nn.Module):
def __init__(self, in_channels, rate=4):
super().__init__()
out_channels = in_channels
in_channels = int(in_channels)
out_channels = int(out_channels)
inchannel_rate = int(in_channels/rate)
self.linear1 = nn.Linear(in_channels, inchannel_rate)
self.relu = nn.ReLU(inplace=True)
self.linear2 = nn.Linear(inchannel_rate, in_channels)
self.conv1=nn.Conv2d(in_channels, inchannel_rate,kernel_size=7,padding=3,padding_mode='replicate')
self.conv2=nn.Conv2d(inchannel_rate, out_channels,kernel_size=7,padding=3,padding_mode='replicate')
self.norm1 = nn.BatchNorm2d(inchannel_rate)
self.norm2 = nn.BatchNorm2d(out_channels)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
b, c, h, w = x.shape
# B,C,H,W ==> B,H*W,C
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
# B,H*W,C ==> B,H,W,C
x_att_permute = self.linear2(self.relu(self.linear1(x_permute))).view(b, h, w, c)
# B,H,W,C ==> B,C,H,W
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.relu(self.norm1(self.conv1(x)))
x_spatial_att = self.sigmoid(self.norm2(self.conv2(x_spatial_att)))
out = x * x_spatial_att
return out
if __name__ == '__main__':
img = torch.rand(1,64,32,48)
b, c, h, w = img.shape
net = GAM(in_channels=c, out_channels=c)
output = net(img)
print(output.shape)三、CBAM
3.1 CBAM的介绍

官方论文地址:官方论文地址点击此处即可跳转
官方代码地址:官方代码地址点击此处即可跳转

简单介绍:CBAM的主要思想是通过关注重要的特征并抑制不必要的特征来增强网络的表示能力。模块首先应用通道注意力,关注"重要的"特征,然后应用空间注意力,关注这些特征的"重要位置"。通过这种方式,CBAM有效地帮助网络聚焦于图像中的关键信息,提高了特征的表示力度,下图为其简单原理结构图。
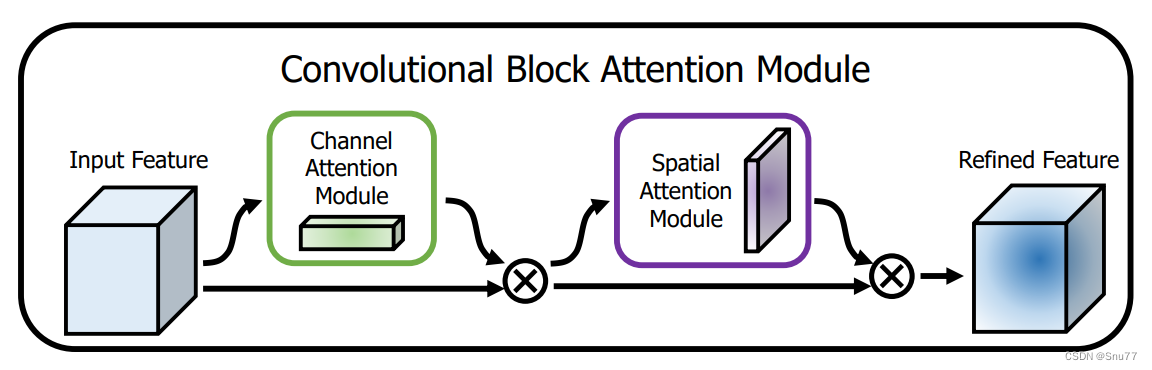
3.2 CBAM核心代码
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
"""Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet."""
def __init__(self, channels: int) -> None:
"""Initializes the class and sets the basic configurations and instance variables required."""
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Applies forward pass using activation on convolutions of the input, optionally using batch normalization."""
return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
"""Spatial-attention module."""
def __init__(self, kernel_size=7):
"""Initialize Spatial-attention module with kernel size argument."""
super().__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
"""Apply channel and spatial attention on input for feature recalibration."""
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
"""Convolutional Block Attention Module."""
def __init__(self, c1, kernel_size=7):
"""Initialize CBAM with given input channel (c1) and kernel size."""
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
"""Applies the forward pass through C1 module."""
return self.spatial_attention(self.channel_attention(x))四、CA
4.1 CA的介绍

官方论文地址:官方论文地址点击此处即可跳转
官方代码地址: 官方代码地址点击此处即可跳转

简单介绍: 坐标注意力是一种结合了通道注意力和位置信息的注意力机制,旨在提升移动网络的性能。它通过将特征张量沿两个空间方向进行1D全局池化,分别捕获沿垂直和水平方向的特征,保留了精确的位置信息并捕获了长距离依赖性。这两个方向的特征图被单独编码成方向感知和位置敏感的注意力图,然后这些注意力图通过乘法作用于输入特征图,以突出感兴趣的对象表示。坐标注意力的引入,使得模型能够更准确地定位和识别感兴趣的对象,同时由于其轻量级和灵活性,它可以轻松集成到现有的移动网络架构中,几乎不会增加计算开销。
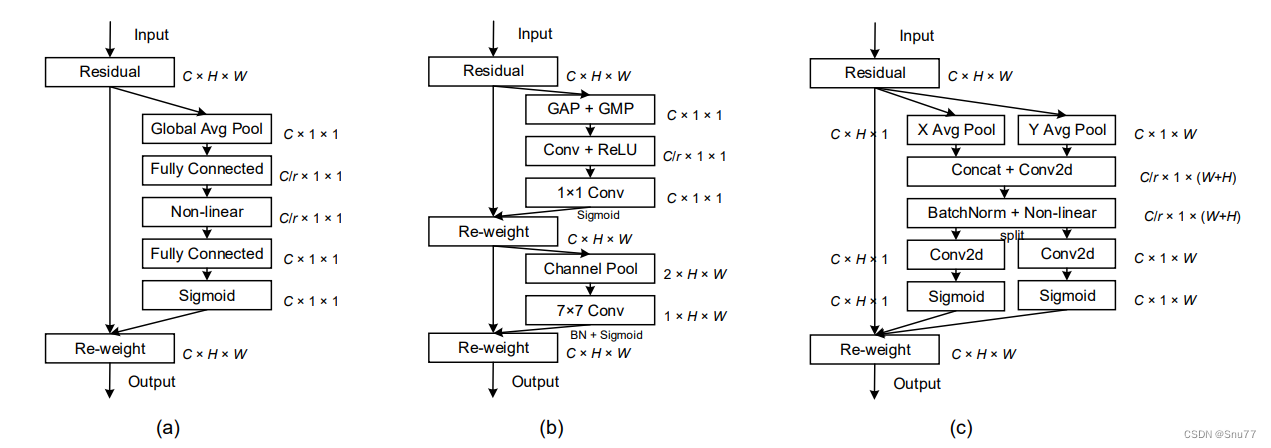
4.2 CA核心代码
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, reduction=32):
super(CoordAtt, self).__init__()
oup = inp
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out五、ECA
5.1 ECA的介绍

官方论文地址:官方论文地址点击此处即可跳转
官方代码地址:官方代码地址点击此处即可跳转

简单介绍:ECA(Efficient Channel Attention)注意力机制的原理可以总结为:避免通道注意力模块中的降维操作,通过采用局部跨通道交互策略,利用1D卷积实现高效的通道注意力计算。这种方法保持了性能的同时显著减少了模型的复杂性,通过自适应选择卷积核大小,确定了局部跨通道交互的覆盖范围。 ECA模块通过少量参数和低计算成本,实现了在ResNets和MobileNetV2等主干网络上的显著性能提升,且相对于其他注意力模块具有更高的效率和更好的性能。
5.2 ECA核心代码
import torch
from torch import nn
from torch.nn.parameter import Parameter
class ECA(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel, k_size=3):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
六、注意力机制的添加方法
6.1 修改一
第一还是建立文件,我们找到如下yolov5-master/models文件夹下建立一个目录名字呢就是'modules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

6.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
6.3 修改三
第三步我门中到如下文件'yolov5-master/models/yolo.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
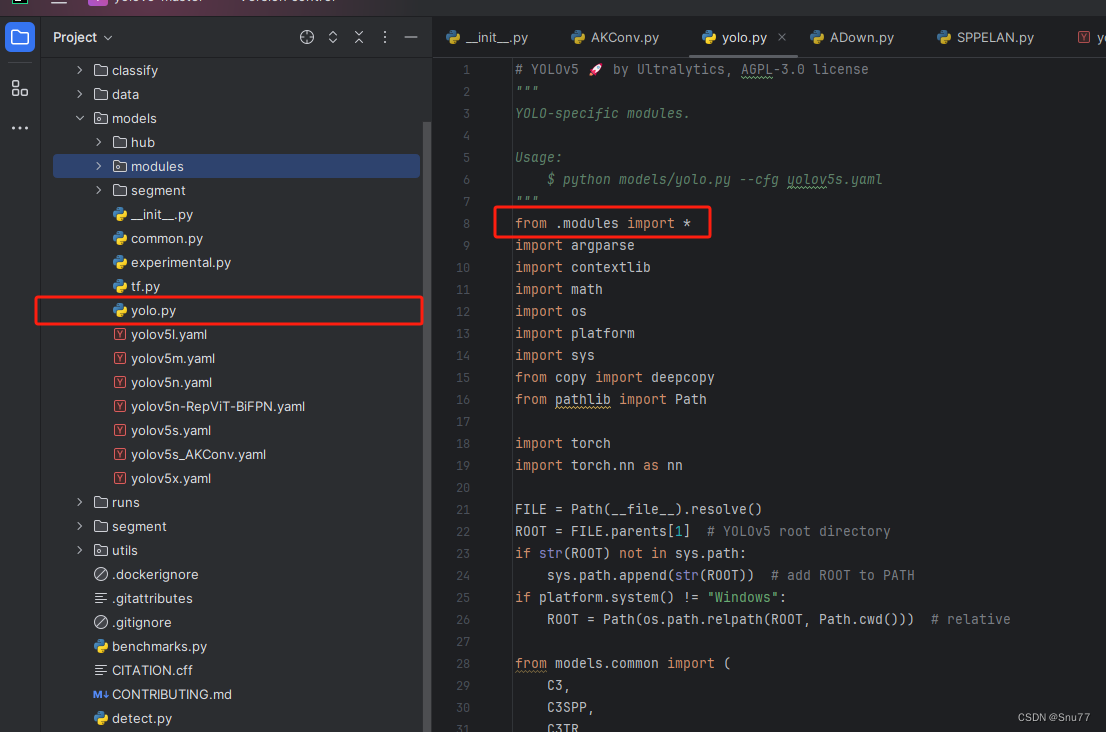
6.4 修改四
按照我的添加在parse_model里添加即可。
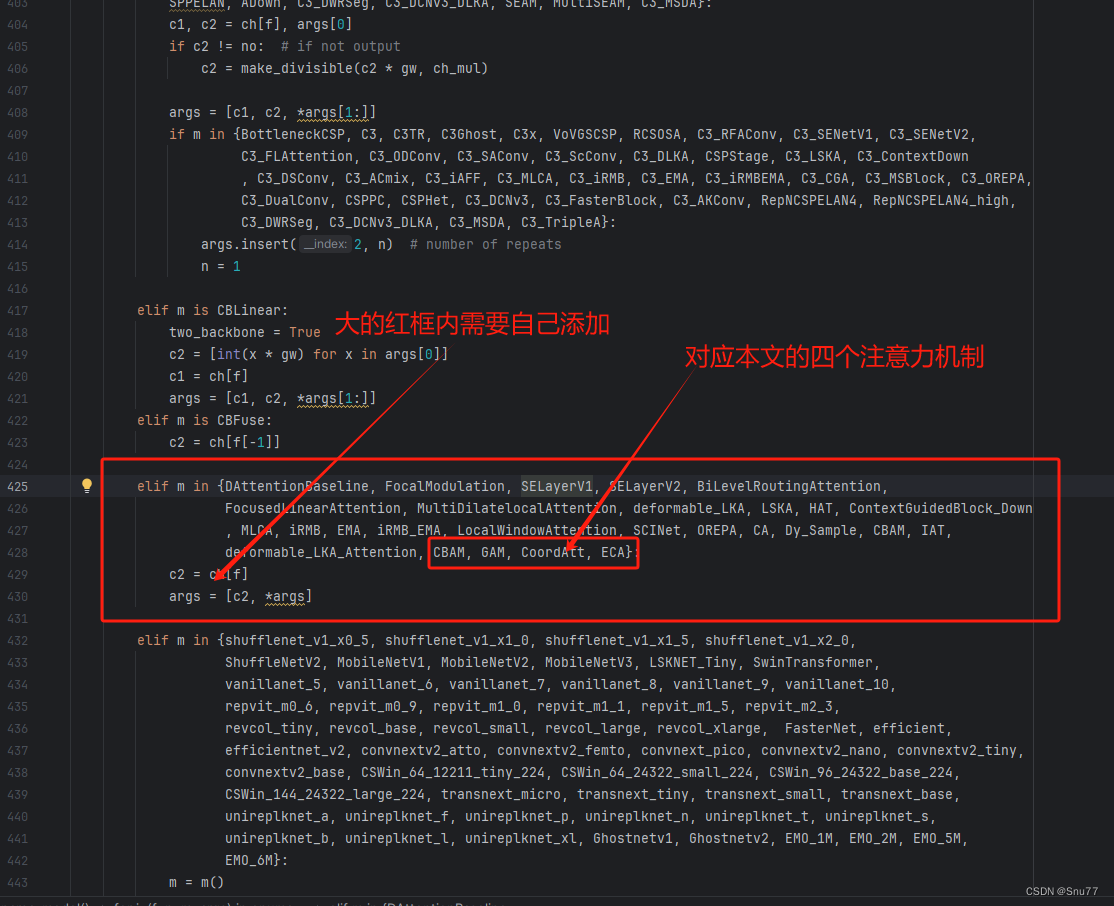
到此就修改完成了,大家可以复制下面的yaml文件运行。
七、yaml文件
7.1 添加位置1
下面的文件是配置好的yaml文件,其中包含了四个注意力机制,其中默认先用的CBAM大家使用那个只需要把其他的注释掉即可
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, CBAM, []], # 24 这里默认先用的CBAM大家使用那个只需要把其他的注释掉即可
# [-1, 1, ECA, []],
# [-1, 1, CoordAtt, []],
# [-1, 1, GAM, []],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
7.1 添加位置2
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[
[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[ -1, 1, CBAM, [ ] ], # 9 这里默认先用的CBAM大家使用那个只需要把其他的注释掉即可
# [-1, 1, ECA, []],
# [-1, 1, CoordAtt, []],
# [-1, 1, GAM, []],
[-1, 1, SPPF, [1024, 5]], # 10
]
# YOLOv5 v6.0 head
head: [
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 14
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, "nearest"]],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 18 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 15], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 21 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 24 (P5/32-large)
[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
使用方法同上!
想要学习添加更多添加位置更多机制欢迎大家订阅专栏~
八、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分96分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~


















 434
434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











