### 可变形交叉注意力机制概述
可变形交叉注意力机制是一种结合了可变形卷积和交叉注意力的思想,旨在提高模型对不同尺度特征的捕捉能力以及降低计算复杂度的方法。它通常被应用于计算机视觉中的目标检测、语义分割等领域,同时也可能扩展到自然语言处理领域。
#### 基本原理
可变形交叉注意力机制的核心在于利用可变形卷积动态调整采样位置的能力,从而增强模型的空间自适应性[^1]。这种机制允许模型根据不同输入区域的重要性分配权重,并通过交叉注意力建立全局上下文关联。相比于传统的固定采样方式,这种方法能更有效地提取复杂的几何变换信息。
在具体实现方面,该方法首先定义一组偏移向量来控制采样的空间位置变化;其次,在这些位置上应用加权求和操作完成特征聚合过程。这一设计不仅保留了标准注意力机制的优点——即建模远程依赖关系的能力,还引入了一定程度上的灵活性以应对实际场景下的多样性需求。
以下是基于 PyTorch 的简单代码示例展示如何构建这样一个模块:
```python
import torch
from torch import nn
class DeformableCrossAttention(nn.Module):
def __init__(self, dim_in=256, num_heads=8, kernel_size=3):
super(DeformableCrossAttention, self).__init__()
self.num_heads = num_heads
head_dim = dim_in // num_heads
self.scale = head_dim ** -0.5
self.qkv_proj = nn.Linear(dim_in, 3 * dim_in)
self.out_proj = nn.Linear(dim_in, dim_in)
# Offset generation network for deformable convolution.
self.offset_net = nn.Conv2d(
in_channels=dim_in,
out_channels=num_heads*kernel_size**2*2, # Two coordinates per point.
kernel_size=kernel_size,
padding="same"
)
def forward(self, x, context=None):
B, N, C = x.shape
qkv = self.qkv_proj(x).reshape(B, N, 3, self.num_heads, C//self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
attn_weights = (q @ k.transpose(-2,-1)) * self.scale
attn_probs = attn_weights.softmax(dim=-1)
offset = self.offset_net(context.permute(0, 2, 1)).view(
B*self.num_heads, -1, *(context.size()[1:])
)
sampled_v = F.grid_sample(v.view(B*self.num_heads, -1, H, W), grid=offset)
output = (attn_probs @ sampled_v.reshape(*sampled_v.shape[:2],-1)).transpose(1,2).contiguous().view(B,N,C)
return self.out_proj(output)
```
此段代码展示了如何创建一个简单的 `Deformable Cross Attention` 层。其中包含了查询键值投影(`qkv`)、偏置生成网络(offset generator),并通过调用Pytorch内置函数实现了核心功能部分。
#### 关于论文与资源链接
目前关于此类特定组合的研究成果较少公开发布完整版PDF文档下载地址。不过可以从以下几篇经典工作中找到灵感:
- [Dai et al., 2017](https://arxiv.org/abs/1703.06211): 提出了原始版本的可变形式卷积概念。
- [Huang et al., 2019](https://paperswithcode.com/paper/criss-cross-attention-for-scene-segmentation): 描述了Criss-Cross Attention结构及其应用场景。
如果希望深入研究或者寻找更多参考资料,则建议访问Papers With Code网站搜索关键词“deformable cross attention”,那里会提供最新进展及相关开源项目链接。








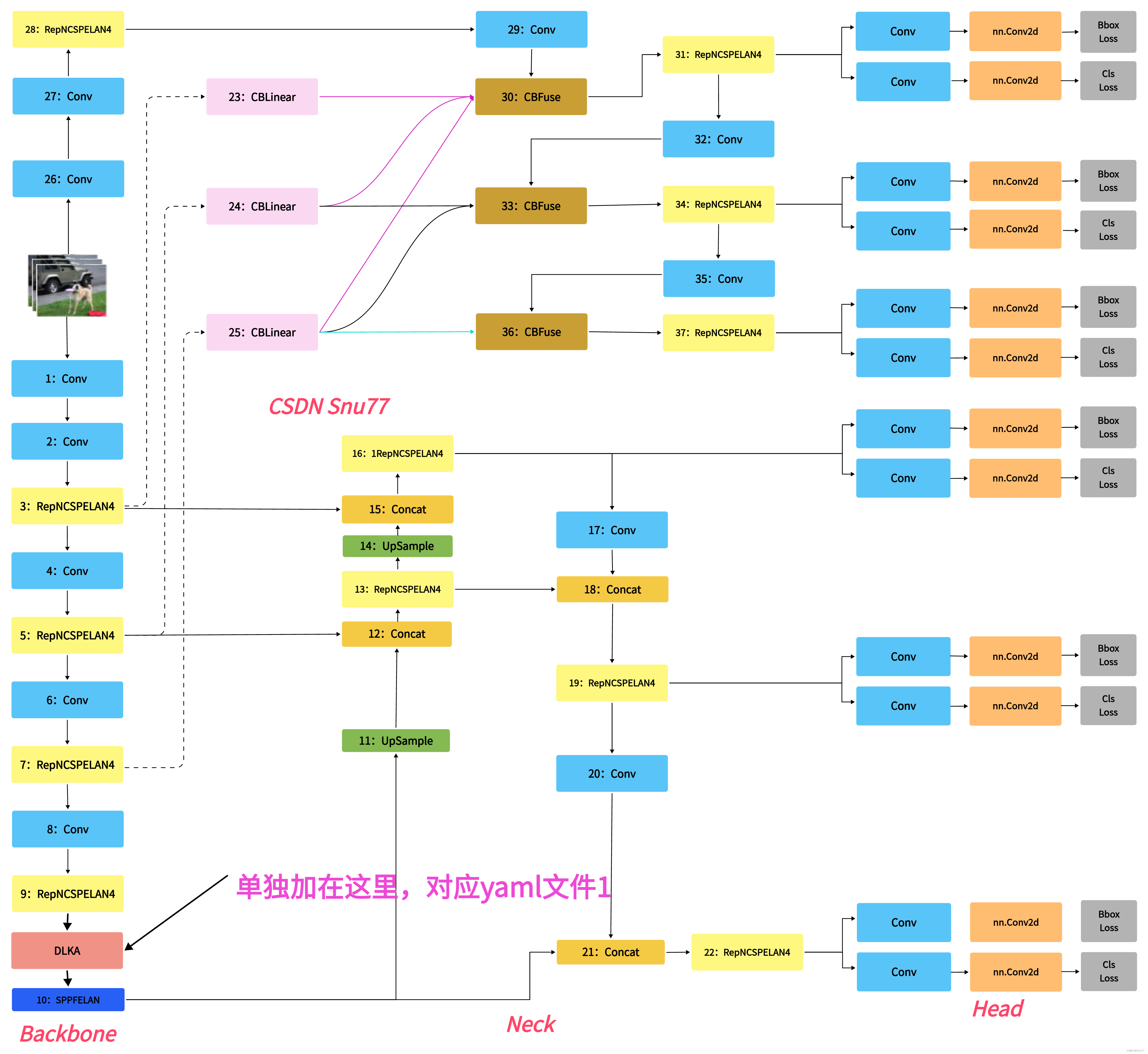
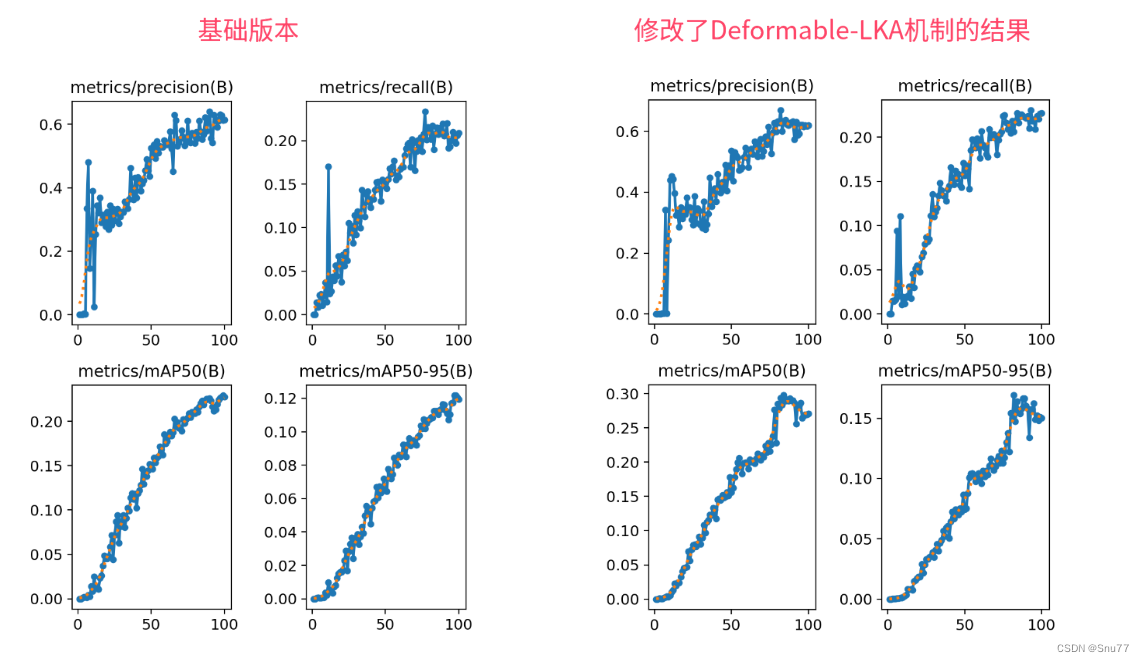
 本文详细介绍了YOLOv9中引入的Deformable-LKA(可变形大核注意力)机制,通过结合大卷积核和可变形卷积,提升了对复杂视觉信息的处理能力,特别是对小目标和不规则形状目标的检测。通过在YOLOv9中添加D-LKA,实验表明模型的mAP提高了约0.8。文中还手把手教读者如何添加D-LKA,提供了核心代码和训练配置文件。
本文详细介绍了YOLOv9中引入的Deformable-LKA(可变形大核注意力)机制,通过结合大卷积核和可变形卷积,提升了对复杂视觉信息的处理能力,特别是对小目标和不规则形状目标的检测。通过在YOLOv9中添加D-LKA,实验表明模型的mAP提高了约0.8。文中还手把手教读者如何添加D-LKA,提供了核心代码和训练配置文件。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











