







word2vec入门篇应该是这个:http://blog.csdn.net/itplus/article/details/37969519
根据第一个链接,word2vec有三种模型,所有的模型都是在这个的基础上求解的:
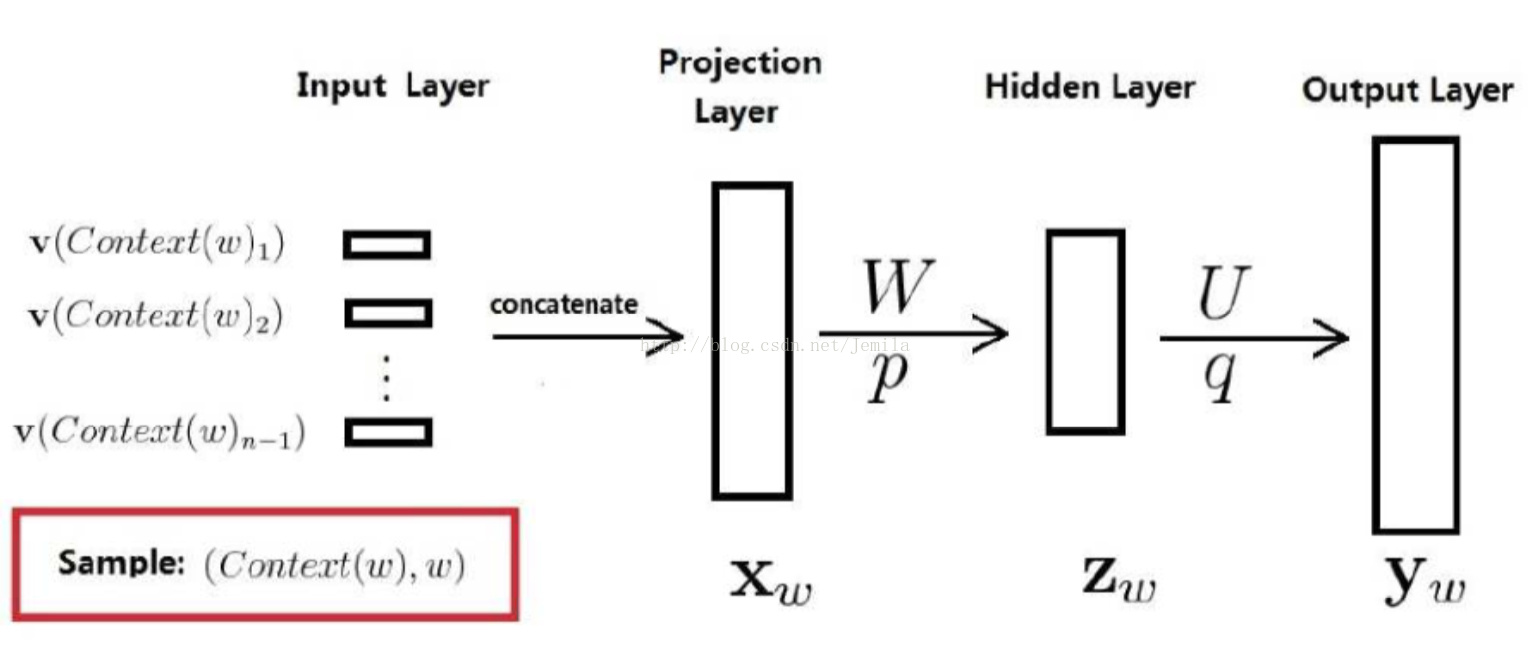
第一种是带隐藏层的,其激活函数为tanh,然而由于隐藏层到output_layer的参数太多,毕竟output_layer的参数为vocabulary_size,动辄成千上万,所以第一种被去掉了;
第二种是采用huffuman tree和hierarchical softmax;
第三种是负样本采样 nagetive sampling,相比第二种的计算速度更快。
关于第二种和第三种,这里的这篇文章讲的挺好:http://www.cnblogs.com/Determined22/p/5807362.html
cbow和skip-gram的区别在于:一个是通过上下文预测中心词,一个是通过中心词预测上下文,这点非常重要,输入和输出是不一样的,但是中间过程十分相似。
这里主要讲负样本采样的skip-gram模型,目标是通过中心词预测上下文,参考这篇文章:http://qiancy.com/2016/08/24/word2vec-negative-sampling/
负样本采样的思想为:增大取到上下文词的概率,减小取到其他词(除了中心词和上下文)的概率,其损失函数是在此基础上进行取对数,之后进行参数和词向量的更新。负样本的采样方法是按照词频排序之后选取和中心词接近词频的一部分词,如果取到正样本则舍弃。
一般将其理解为:
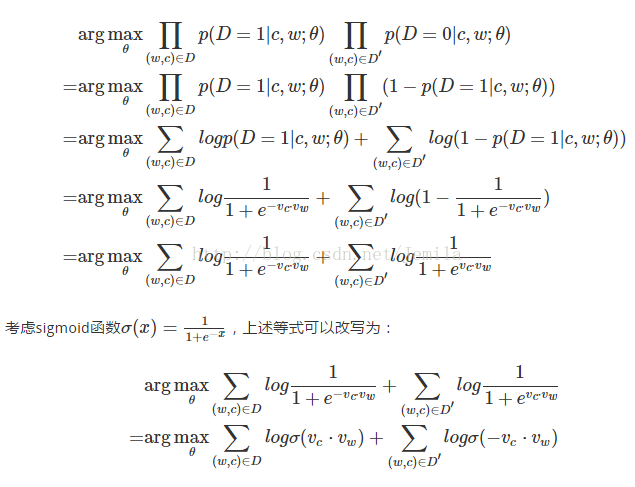
我自己理解为:
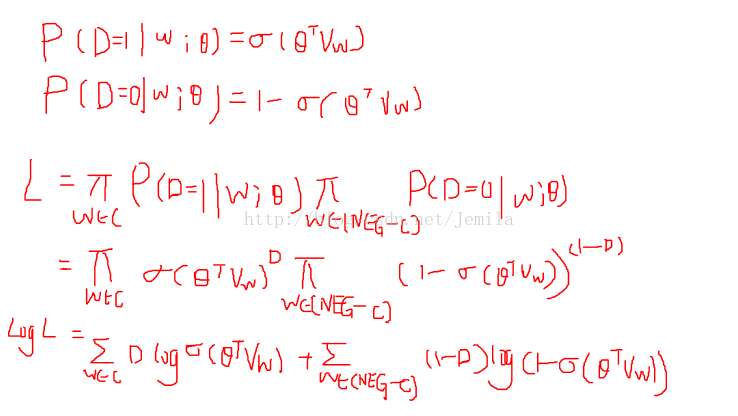
完整代码来自udacity:http://pan.baidu.com/s/1eRUaxhS
过程解释:
定义:count::高频词以及对应词频,低频词为UNK(UNKOWN)以及对应词频;dictionary:词以及其对应编码;reserve_dictionary:编码以及其对应词;data:原文本中所有单词组成的编码;
定义:num_skips:上下文取得词的个数,譬如num_skips=1,则中心词左右任选一个;skip_window:每次移动的窗口大小,一般情况下skip_window=num_skip/2;span:span=skip_window*2+1,即[ skip_window target skip_window ];buffer:它是通过data_index增加来不断调整list的元素,本身为一个collections.deque(maxlen=span),即每次append一个新的元素,第一个旧的元素会被新词挤出。输入batch为中心词(对应的编码,1*D维向量),输出label为上下文(对应的编码,D维*1向量)
运行一下就会发现:
data: ['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first']
with num_skips = 2 and skip_window = 1:
batch: ['originated', 'originated', 'as', 'as', 'a', 'a', 'term', 'term']
labels: ['as', 'anarchism', 'originated', 'a', 'as', 'term', 'a', 'of']
with num_skips = 4 and skip_window = 2:
batch: ['as', 'as', 'as', 'as', 'a', 'a', 'a', 'a']
labels: ['originated', 'a', 'anarchism', 'term', 'of', 'originated', 'term', 'as']
当skip_window=1,它跳过了开头第一个单词,而当=2,则跳过了开头前两个单词。
batch_size:每次批量输入的词的个数,embedding_size:词向量的大小;但是最终输入的是embed:注意这个函数:tf.nn.embedding_lookup(embeddings, train_dataset),是在embeddings中寻找train_dataset对应的行和列,这里有个参考:http://blog.csdn.net/u013713117/article/details/55048040。此时在最终的loss计算当中:
loss = tf.reduce_mean(
tf.nn.sampled_softmax_loss(weights=softmax_weights, biases=softmax_biases, inputs=embed,
labels=train_labels, num_sampled=num_sampled, num_classes=vocabulary_size))weights的大小为50000*128,biases的大小为50000*1,embed的大小为128*128,num_sampled为负样本的个数,num_classes为总的类别,即vocabulary_size。valid_size = 16,表示求相似度的16个目标向量。接下来可以试着计算这些词向量与其他词向量的相似度,采用余弦定理如下,先对两个矩阵进行标准化,再求矩阵相乘,取top_k即为相似度最大的前k个值,:
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))#50000,对第二维度求和
normalized_embeddings = embeddings / norm#标准化,50000*128
valid_embeddings = tf.nn.embedding_lookup(
normalized_embeddings, valid_dataset)#16*128
similarity = tf.matmul(valid_embeddings, tf.transpose(normalized_embeddings))#16*50000取法如下,此时中心词为valid_word,接近词的编码为nearest,之后按照reserve_dictionary找回原来的单词即可:
sim = similarity.eval()#16*50000
#sim是一个大小为[valid_size,vocabulary]的数组。sim[i,:]是valid_dataset[i]和其它元素的相似程度。
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 8 # number of nearest neighbors
nearest = (-sim[i, :]).argsort()[1:top_k+1]#第i行所有列排序后原来的编码,从1开始是因为第0个是词向量与本身的相似度关于CBOW的负样本采样代码:http://www.hankcs.com/ml/cbow-word2vec.html
其中注意的是,train_dataset是一个128*4的矩阵,经过tf.nn.emdedding_lookup之后变成一个128*4*128,即128个词的4个128维词向量,之后经过tf.reduce_sum()将第二维求和,即将4个编码求和,与第一个链接所述的上下文的词向量相加一致。
另:关于Word2vec中使用到的技巧算法:http://kexue.fm/usr/uploads/2017/04/146269300.pdf















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









