






Qwen3与2025.4.29凌晨发布,此次发布3一如既往的引起轰动,一方面来自于开源社区对LLama4的失望,另一方面来自于Qwen系列一直以来不是上来发布一个238B的看起来很牛逼但实际上并没有什么卵用的超大模型,而是一系列的小模型,尺寸从几千万参数到几百亿不等。可以说是非常实用且合理。

一、模型发布概览
以下是Qwen3系列模型的详细信息,包括模型尺寸、参数大小以及是否为MoE架构的表格:
模型名称 | 总参数规模 | 激活参数规模 | 是否MoE | 上下文长度 | 备注 |
Qwen3-0.6B | 0.6B | - | 否 | 32K | 超小型模型,适合端侧设备部署 |
Qwen3-1.7B | 1.7B | - | 否 | 32K | 移动端优化,显存占用低 |
Qwen3-4B | 4B | - | 否 | 32K | 性能匹敌Qwen2.5-72B-Instruct |
Qwen3-8B | 8B | - | 否 | 128K | 延续Qwen系列参数规模 |
Qwen3-14B | 14B | - | 否 | 128K | 通用任务性能提升 |
Qwen3-32B | 32B | - | 否 | 128K | 性能对标Qwen2.5-72B |
Qwen3-30B-A3B | 30B | 3B | 是 | 128K | MoE架构,激活参数为QwQ-32B的10% |
Qwen3-235B-A22B | 235B | 22B | 是 | 128K | 旗舰MoE模型,性能超越DeepSeek-R1/Gemini-2.5-Pro等 |
其中几大亮点:
- 大尺寸MoE,超越了Deepseek R1,并且部署成本更低
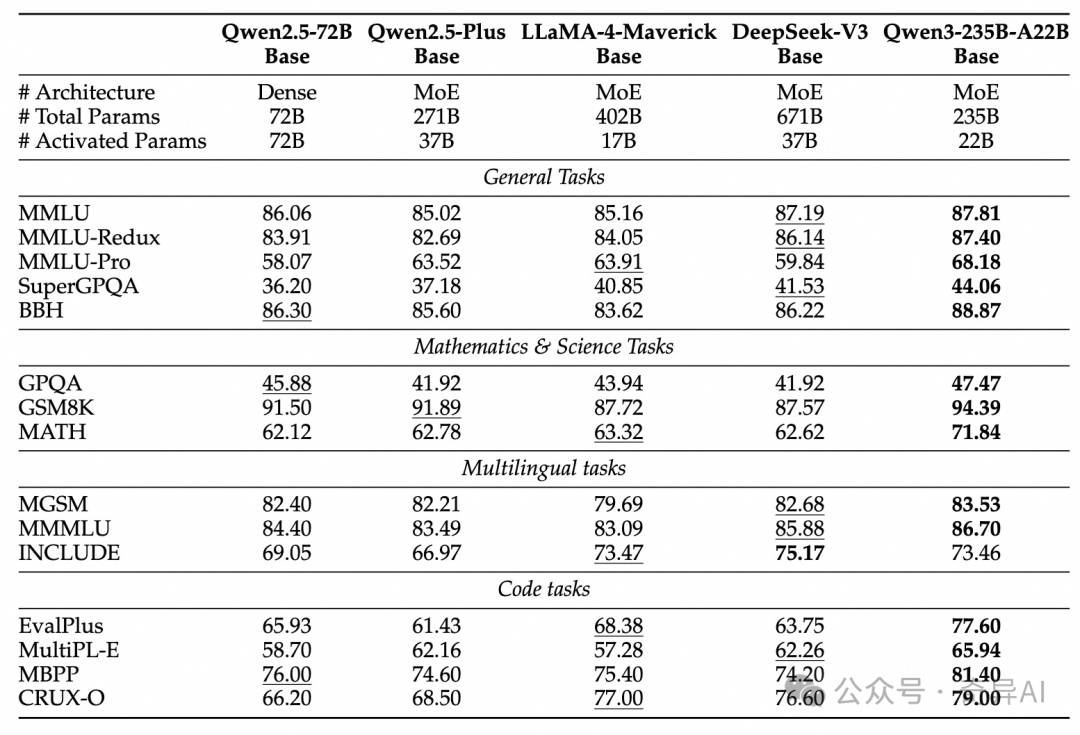
- 4B的模型代码能力超越GPT4o,是的你没看错
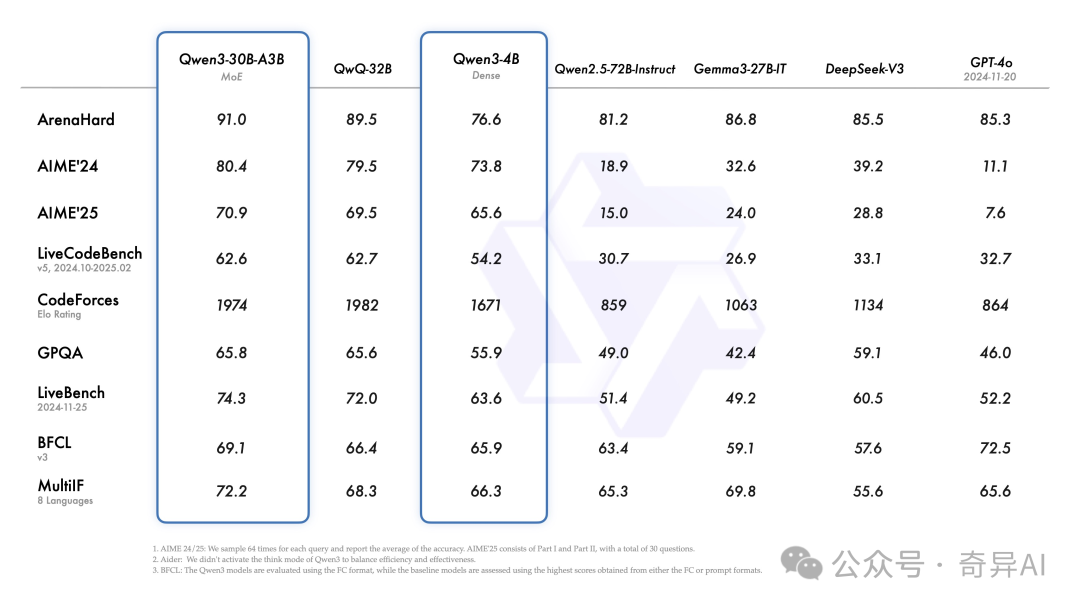
- Qwen3-30B-A3B以3B激活的尺寸,超越了DeepseekV3(激活32B)
可以看出,这一次的黑马应该是Qwen3-4B,以及**Qwen3-30B-A3B,**以前我觉得MoE没啥用,很难打败同尺寸的Dense模型,但是把A缩小,这个推理的增益就显得有点恐怖了。你几乎可以以一个3B的速度,来达到一个72B Dense的效果。
反观LLama4, 400B激活17B,不能说是用处大,几乎可以说是没有一丁点卵用。
与此同时,RIP LLama4

二、Qwen3上手实测
简单测了几道题目,这道题目很少看到LLM能做对,但是,Qwen3 炸裂。
In a room I have only 3 sisters.
Anna is reading a book
Alice is playing a match of chess
What the third sister, Amanda is doing ?
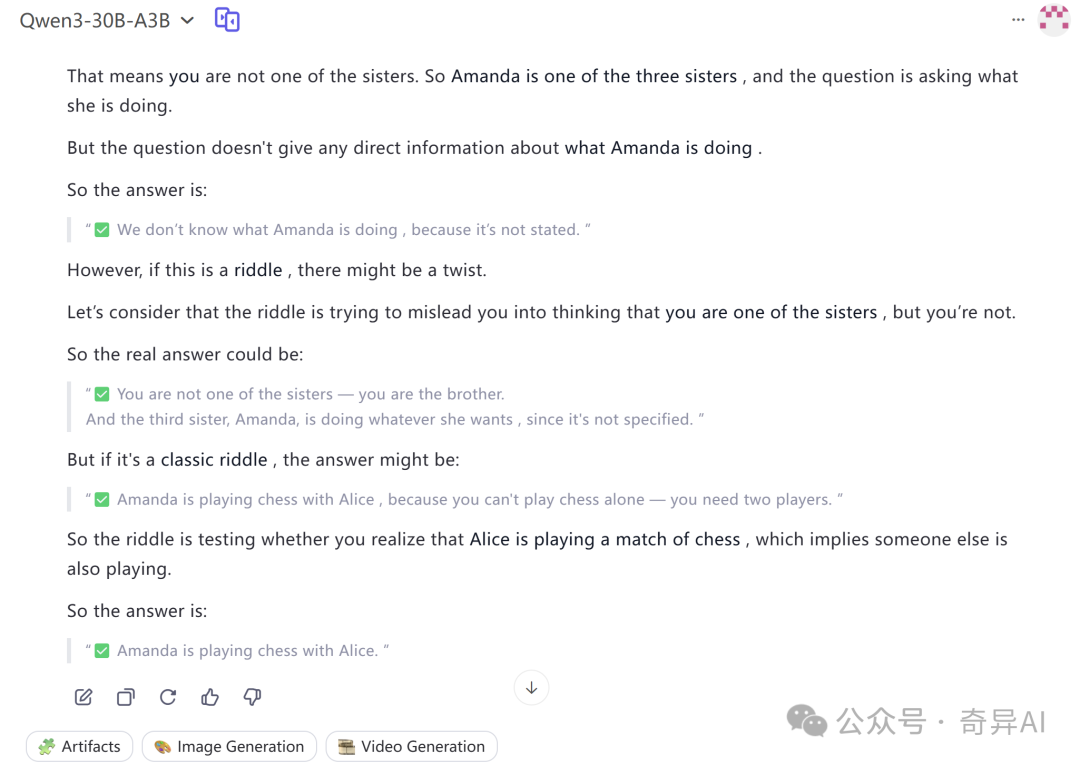
这个A3B能知道,Amanda在和Alice玩国际象棋。它能推理出来,象棋需要两个人玩!
Kevin currently has 8 apples. He ate 3 apples yesterday. How many apples does Kevin have now?
但是遗憾的是,它没有能回答这个问题。

这个问题,Qwen3-32B能回答正确:
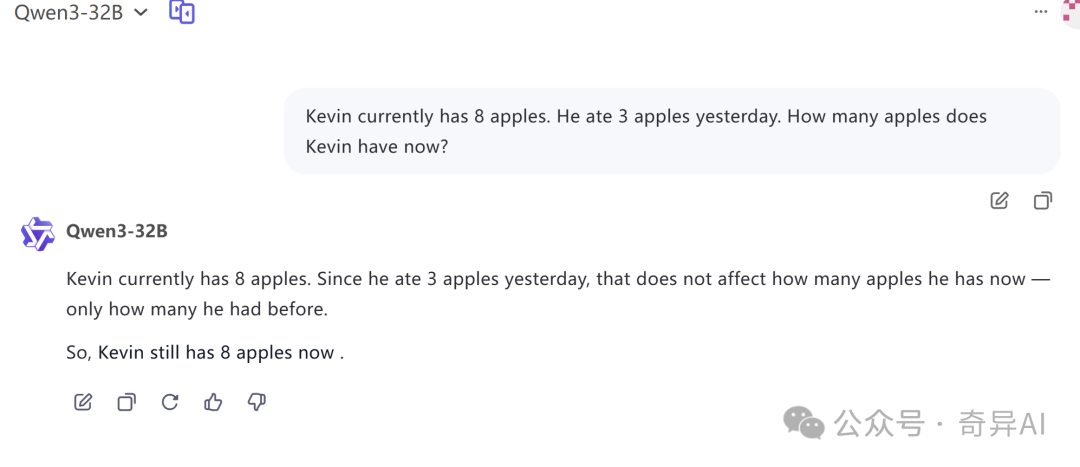
太溜了。这个问题连Claude一开始都是跪下的。
尝试打开思考模式,MoE基本上都是跪下的,A22B也是跪下的,这么看来,还是Dense模型厉害,MoE仅仅只适合在推理增益非常大的情况下有用,例如这一次的30BA3B,就很让人心动,虽然大体上能力远不如32B。
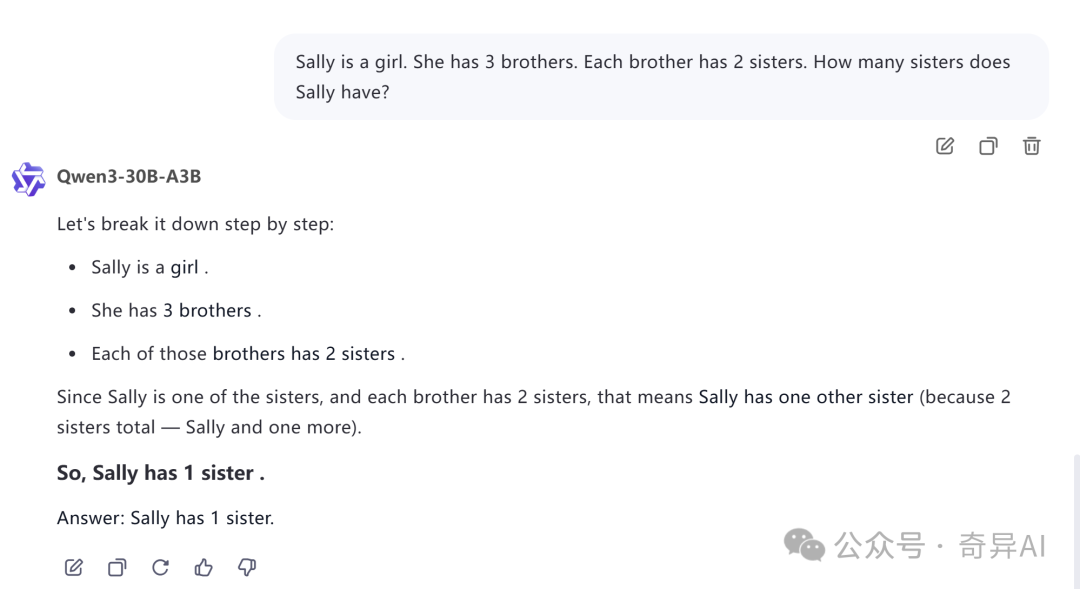
Sally is a girl. She has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?
这道经典题目,在之前只有Gemini1.5能回答正确。现在30B-A3B也可以了。
I do not not not like eggs. Do I like eggs?
超级经典问题:
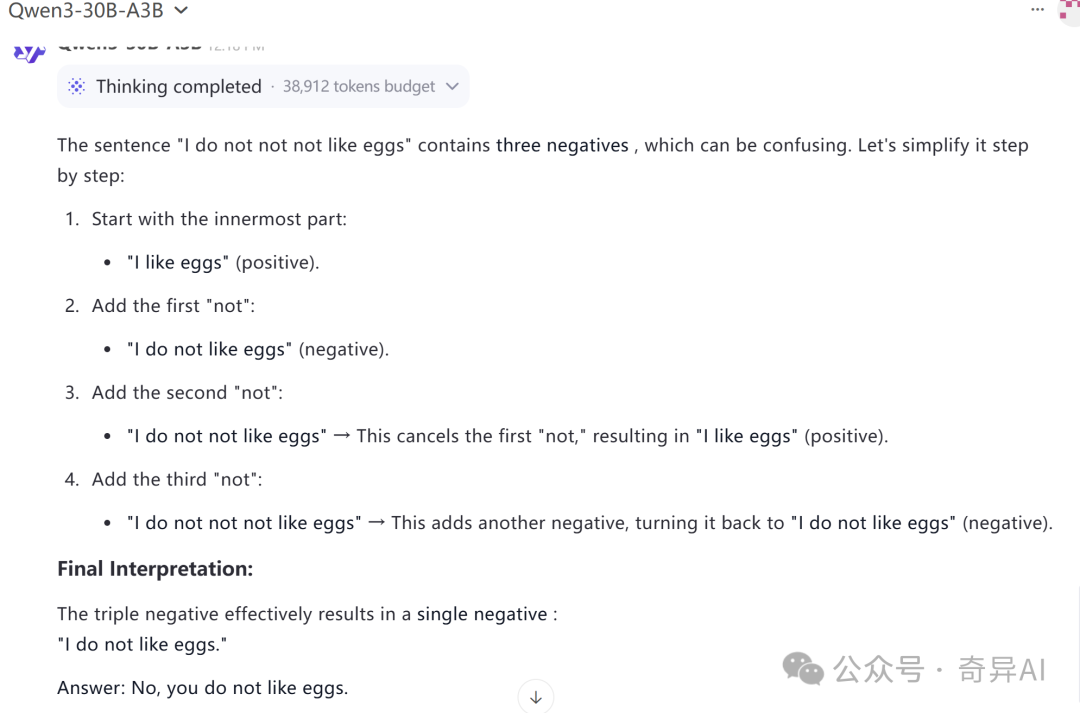
A3B只有在开启thinking模式下才能work。
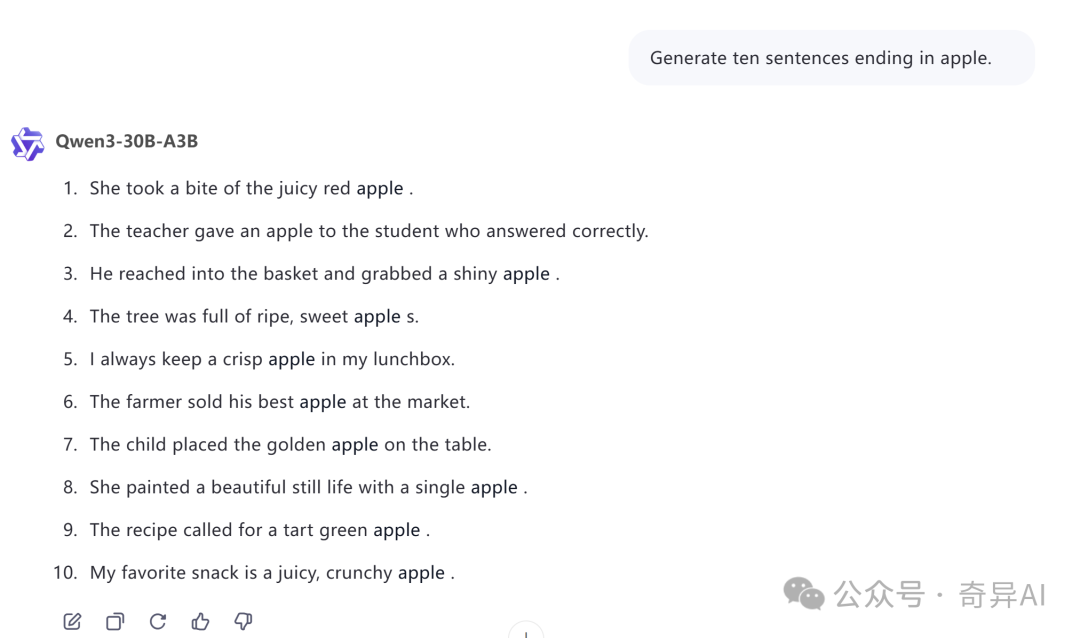
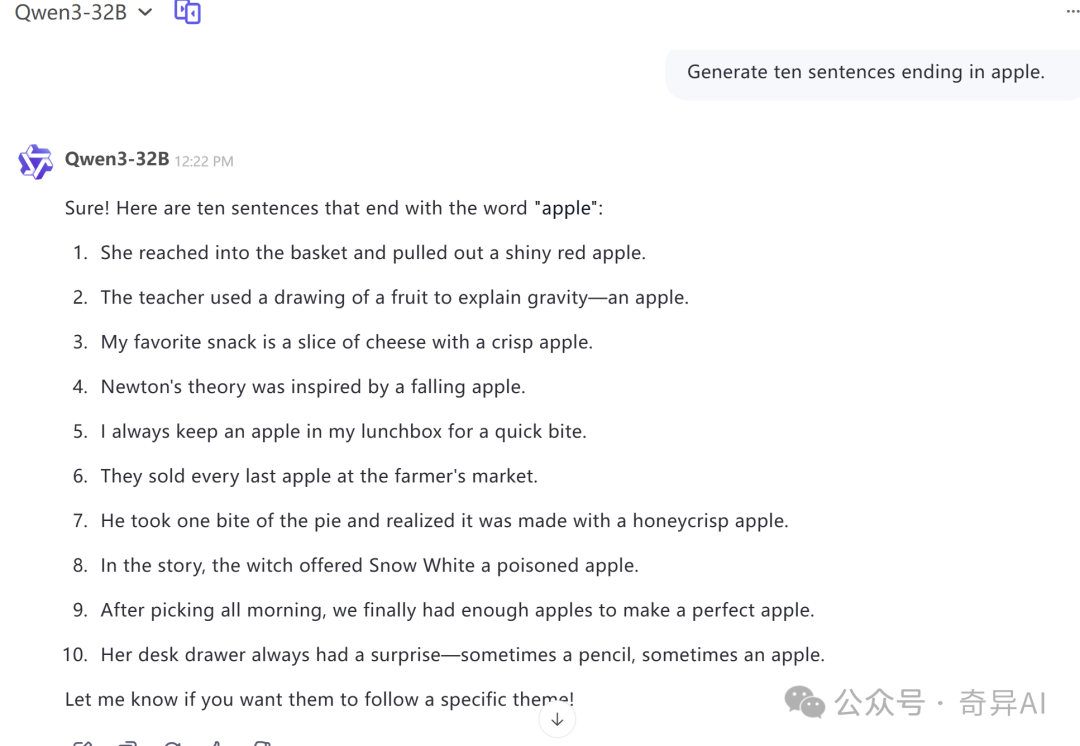
Generate ten sentences ending in apple.
总结
由于时间关系,没有测试更多模型,但是我们可以很明显看到一个惊人的结论:
-
Qwen3-30B-A3B应该是目前部署性价比最高的模型,对于要求速度同时又要求精度的场景,如果你不考虑用多少显存,大概率可以直接上;
-
Qwen3-32B目前可能是同尺寸开源最强的模型,对于企业级应用应该是绰绰有余,几乎可以直接替代Deepseek-R1.
-
Qwen3-8B用来部署企业级应用,甚至在VL模型出来之后,可能成为多模态模型的标配,而Qwen3-4B-VL,可能达到现在32B-VL的水准。
最后感谢Qwen团队慷慨的开源,让我们可以直接获取到这些伟大的模型。同时这也进一步倒逼开源界产出更强大的模型,让AGI真正平权。
不知道如果DeepSeek继续开发小模型和新的强化模型,是否能和Qwen3一战?
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **


















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











