






BERT 是 Bidirectional Encoder Representations from Transformers 的首字母缩写词,是专为自然语言处理 (NLP) 领域设计的开源机器学习框架。该框架起源于 2018 年,由 Google AI Language 的研究人员精心制作。本文旨在探讨 BERT 的架构、工作和应用。
什么是 BERT?
BERT (Bidirectional Encoder Representations from Transformers) 利用基于 transformer 的神经网络来理解和生成类似人类的语言。BERT 采用纯编码器架构。在最初的 Transformer 架构中,既有编码器模块,也有解码器模块。在 BERT 中使用纯编码器架构的决定表明,主要强调理解输入序列,而不是生成输出序列。
BERT 的双向方法
传统语言模型按顺序处理文本,从左到右或从右到左。此方法将模型的感知限制为目标词之前的直接上下文。BERT 使用双向方法同时考虑句子中单词的左右上下文,而不是按顺序分析文本,而是同时查看句子中的所有单词。
示例:“河岸位于河的_______。
在单向模型中,对空白的理解在很大程度上取决于前面的单词,并且模型可能难以辨别“bank”是指金融机构还是河的一侧。
BERT 是双向的,同时考虑左侧(“河岸位于”)和右侧上下文(“河流”),从而能够进行更细致的理解。它理解缺失的单词可能与银行的地理位置有关,展示了双向方法带来的上下文丰富性。
预训练和微调
BERT 模型经历两个步骤:
- 对大量未标记文本进行预训练,以学习上下文嵌入。
- 针对特定 NLP任务对标记数据进行微调。
大数据的预训练
- BERT 在大量未标记的文本数据上进行了预训练。该模型学习上下文嵌入,即在句子中考虑周围上下文的单词表示。
- BERT 从事各种无监督的训练前任务。例如,它可能会学习预测句子中缺失的单词(掩蔽语言模型或 MLM 任务),理解两个句子之间的关系,或预测成对的下一个句子。
对标记数据进行微调
- 在预训练阶段之后,BERT 模型及其上下文嵌入物,然后针对特定的自然语言处理 (NLP) 任务进行微调。此步骤通过调整模型的一般语言理解以适应特定任务的细微差别,将模型定制为更有针对性的应用程序。
- BERT 使用特定于相关下游任务的标记数据进行微调。这些任务可能包括情绪分析、问答、命名实体识别或任何其他 NLP 应用程序。调整模型的参数,以优化其性能,以满足手头任务的特定要求
。
BERT 的统一架构使其能够以最少的修改适应各种下游任务,使其成为自然语言理解和处理的多功能且高效的工具。
BERT 是如何工作的?
BERT 旨在生成语言模型,因此仅使用编码器机制。Sequence of tokens 被馈送到 Transformer 编码器。这些标记首先嵌入到向量中,然后在神经网络中进行处理。输出是一系列向量,每个向量对应一个输入标记,提供上下文化的表示。
在训练语言模型时,定义预测目标是一项挑战。许多模型预测序列中的下一个单词,这是一种定向方法,可能会限制上下文学习。BERT 通过两种创新的训练策略来应对这一挑战:
- 掩码语言模型 (MLM)
- 下一句预测 (NSP)
1. 掩蔽语言模型 (MLM)
在 BERT 的预训练过程中,每个输入序列中的一部分单词被屏蔽,模型被训练为根据周围单词提供的上下文预测这些被屏蔽的单词的原始值。
简单来说,
- 掩码词:在 BERT 从句子中学习之前,它会隐藏一些单词(约 15%)并用特殊符号替换它们,例如 [MASK]。
- 猜出隐藏的单词: BERT 的工作是通过查看它们周围的单词来弄清楚这些隐藏的单词是什么。这就像一个猜谜游戏,哪里缺少一些单词,BERT 试图填补空白。
- BERT 如何学习:
- BERT 在其学习系统之上添加了一个特殊层来进行这些猜测。然后,它会检查其猜测与实际隐藏单词的接近程度。
- 它通过将猜测转换为概率来实现这一点,说:“我认为这个词是 X,我对此非常确定。
- 特别注意隐藏词
- BERT 在训练期间的主要重点是正确处理这些隐藏的单词。它不太关心预测没有隐藏的单词。
- 这是因为真正的挑战是找出缺失的部分,而这种策略帮助 BERT 真正擅长理解单词的含义和上下文。
用技术术语来说,
- BERT 在编码器的输出之上添加了一个分类层。该层对于预测掩码词至关重要。
- 分类层的输出向量乘以嵌入矩阵,将它们转换为词汇维度。此步骤有助于使预测的表示形式与词汇空间保持一致。
- 词汇表中每个单词的概率是使用 SoftMax 激活函数计算的。此步骤为每个掩码位置生成整个词汇表的概率分布。
- 训练期间使用的损失函数仅考虑掩码值的预测。该模型因其预测与掩码词的实际值之间的偏差而受到惩罚。
- 该模型的收敛速度比定向模型慢。这是因为,在训练期间,BERT 只关心预测掩码值,而忽略了非掩码词的预测。通过此策略实现的上下文感知增强弥补了收敛速度较慢。
2. 下一句预测 (NSP)
BERT 预测第二个句子是否与第一个句子相连。这是通过使用分类层将 [CLS] 标记的输出转换为 2×1 形状的向量,然后使用 SoftMax 计算第二个句子是否跟随第一个句子的概率来完成的。
- 在训练过程中,BERT 学习理解成对句子之间的关系,预测原始文档中的第二个句子是否跟在第一个句子之后。
- 50% 的输入对将第二个句子作为原始文档中的后续句子,而其他 50% 的输入对则随机选择句子。
- 帮助模型区分连通和不连通的句子对。在进入模型之前处理输入:
- 在第一个句子的开头插入一个 [CLS] 标记,并在每个句子的末尾添加一个 [SEP] 标记。
- 指示句子 A 或句子 B 的句子嵌入将添加到每个标记中。
- 位置嵌入指示序列中每个标记的位置。
- BERT 预测第二个句子是否与第一个句子相连。这是通过使用分类层将 [CLS] 标记的输出转换为 2×1 形状的向量,然后使用 SoftMax 计算第二个句子是否跟随第一个句子的概率来完成的。
在 BERT 模型的训练过程中,Masked LM 和 Next Sentence Prediction 一起训练。该模型旨在最小化 Masked LM 和 Next Sentence Prediction 的组合损失函数,从而产生一个强大的语言模型,在理解句子内的上下文和句子之间的关系方面具有增强的能力。
为什么要一起训练 Masked LM 和 Next Sentence Prediction?
Masked LM 帮助 BERT 理解句子中的上下文,Next Sentence Prediction 帮助 BERT 掌握句子对之间的联系或关系。因此,同时训练这两种策略可确保 BERT 学习对语言的广泛而全面的理解,捕捉句子中的细节和句子之间的流动。
BERT 架构
BERT 的架构是一个多层双向变压器编码器,与变压器模型非常相似。transformer 架构是一种编码器-解码器网络,它在编码器端使用 self-attention,在解码器端使用 attention。
- 伯特基础 在Encoder 堆栈中有 1 2 层,而 BERT大 在 Encoder 堆栈中有 24 个层。这些比原始论文中描述的 Transformer 架构(6 个编码器层)更多。
- 与原始论文中建议的 Transformer 架构相比,BERT 架构(BASE 和 LARGE)还具有更大的前馈网络(分别为 768 和 1024 个隐藏单元)和更多的注意力头(分别为 12 个和 16 个)。它包含 512 个隐藏单元和 8 个注意力头。
- 伯特基础包含 110M 参数,而 BERT大有 340M 个参数。

BERT BASE 和 BERT LARGE 架构。
此模型首先将 CLS 令牌作为输入,然后是一系列单词作为输入。这里 CLS 是一个分类标记。然后,它将 input 传递给上述层。每一层都应用自我注意,并通过前馈网络传递结果,然后移交给下一个编码器。该模型输出一个隐藏大小的向量(BERT BASE 为 768)。如果我们想从这个模型输出一个分类器,我们可以获取与 CLS 令牌对应的输出。
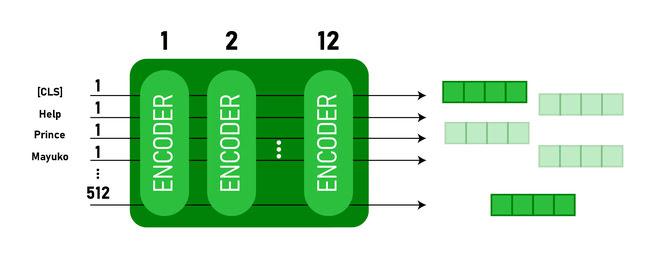
BERT 输出作为 Embeddings
现在,这个经过训练的向量可用于执行许多任务,例如分类、翻译等。例如,本文在 分类任务中仅在 BERT 模型上使用单层神经网络就取得了很好的结果。
如何在 NLP 中使用 BERT 模型?
BERT 可用于各种自然语言处理 (NLP) 任务,例如:
1. 分类任务
- BERT 可用于情感分析等分类任务,目标是将文本分类为不同的类别(积极/消极/中性),可以通过在 Transformer 输出顶部为 [CLS] 令牌添加分类层来使用 BERT。
[CLS] 令牌表示来自整个输入序列的聚合信息。然后,可以将此池化表示用作分类图层的输入,以对特定任务进行预测。
2. 问答
- 在问答任务中,需要模型在给定的文本序列中定位和标记答案,可以为此目的训练 BERT。
- BERT 通过学习两个额外的向量来标记答案的开头和结尾,从而进行问答训练。在训练过程中,模型会提供问题和相应的段落,并学习预测段落中答案的开始和结束位置。
3. 命名实体识别 (NER)
- BERT 可用于 NER,其目标是识别和分类文本序列中的实体(例如,人员、组织、日期)。
- 基于 BERT 的 NER 模型的训练方法是从 Transformer 中获取每个标记的输出向量并将其馈送到分类层。该层会预测每个令牌的命名实体标签,以指示它所表示的实体类型。
如何使用 BERT 对文本进行标记化和编码?
要使用 BERT 对文本进行标记和编码,我们将使用 Python 中的“transformer”库。
安装变压器的命令:
!pip install transformers
- 我们将使用 BertTokenizer.from_pretrained(“bert-base-cased”)加载带有大小写词汇表的预训练 BERT 分词。
- tokenizer.encode(text) 对输入文本进行分词,并将其转换为令牌 ID 序列。
- print(“Token IDs:”, encoding) 打印编码后获取的 Token ID。
- tokenizer.convert_ids_to_tokens(编码) 将令牌 ID 转换回其对应的令牌。
- print(“Tokens:”, tokens) 打印转换 Token ID 后获取的 Token
- Python3 语言
BERT 模型 – NLP 的解释.py
输出:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102]
Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']
tokenizer.encode 方法在编码序列的开头和结尾添加特殊的 [CLS] – classification 和 [SEP] – 分隔符标记。
BERT 的应用
BERT 用于:
- 文本表示:BERT 用于为句子中的单词生成单词嵌入或表示。
- 命名实体识别 (NER):BERT 可以针对命名实体识别任务进行微调,其中目标是识别给定文本中的实体,例如人员、组织、位置等名称。
- 文本分类:BERT 广泛用于文本分类任务,包括情感分析、垃圾邮件检测和主题分类。它在理解和分类文本数据的上下文方面表现出了出色的性能。
- 问答系统:BERT 已应用于问答系统,其中模型经过训练以理解问题的上下文并提供相关答案。这对于阅读理解等任务特别有用。
- 机器翻译:BERT 的上下文嵌入可用于改进机器翻译系统。该模型捕捉了语言的细微差别,这些细微差别对于准确翻译至关重要。
- 文本摘要:BERT 可用于抽象文本摘要,其中模型通过理解上下文和语义来生成较长文本的简洁而有意义的摘要。
- 对话式 AI:BERT 用于构建对话式 AI 系统,例如聊天机器人、虚拟助手和对话系统。它掌握上下文的能力使其能够有效地理解和生成自然语言响应。
- 语义相似性:BERT 嵌入可用于测量句子或文档之间的语义相似性。这在重复检测、释义识别和信息检索等任务中很有价值。
BERT 与 GPT
BERT 和 GPT 的区别如下:
| 伯特 | GPT | |
|---|---|---|
| 建筑 | BERT 专为双向表示学习而设计。它使用掩码语言模型目标,根据左侧和右侧上下文预测句子中缺失的单词。 | 另一方面,GPT 专为生成语言建模而设计。它利用单向自回归方法,在给定前面的上下文中预测句子中的下一个单词。 |
| 训练前目标 | BERT 使用掩码语言模型目标和下一句预测进行预训练。它侧重于捕获双向上下文和理解句子中单词之间的关系。 | GPT 经过预先训练,可以预测句子中的下一个单词,这鼓励模型学习语言的连贯表示并生成与上下文相关的序列。 |
| 上下文理解 | BERT 对于需要深入了解句子中的上下文和关系的任务非常有效,例如文本分类、命名实体识别和问答。 | GPT 在生成连贯且与上下文相关的文本方面表现出色。它通常用于创意任务、对话系统和需要生成自然语言序列的任务。 |
| 任务类型和使用案例
| 通常用于文本分类、命名实体识别、情绪分析和问答等任务。 | 应用于文本生成、对话系统、摘要和创意写作等任务。 |
| 微调 vs 小样本学习 | BERT 通常使用标记数据对特定的下游任务进行微调,以使其预训练的表示适应手头的任务。 | GPT 旨在执行小样本学习,它可以使用最少的特定任务训练数据推广到新任务。 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











