







论文:EXPLORING OCR CAPABILITIES OF GPT-4V(ISION) : A QUANTITATIVE AND IN-DEPTH EVALUATION
代码:https://github.com/SCUT-DLVCLab/GPT-4V_OCR
出处:华南理工
时间:2023.10
贡献:
- 本文作者测评了 GPT-4V 在 OCR 任务上的效果
- 测评包括:场景文本识别、手写文本识别、手写数学公式识别、表格识别、信息抽取
- 测评结论:GPT4V 对拉丁文识别的较好,在多语言场景识别的不太好,对复杂场景识别的也不太好(如手写数学公式、表格识别、信息抽取等)。GPT4V 的能力和特定 OCR 模型相比,效果还有较大的差距,所以如何激发 LMM 模型在 OCR 上的能力还值得探究。
一、背景
大语言模型的成功催生了很多大型多模态模型的出现,如 BLIP-2、OpenFlamingo、LLaVA、MiniGPT4、mPLUG-Owl、GPT-4V 等
GPT-4V 的表现很强,所以本文作者主要探究了 GPT-4V 在 OCR 领域的效果
作者测评的数据集如下:
- 场景文本识别(Scene Text Recognition,STR):CUTE80 [66], SCUT-CTW1500 [67], Total-Text [68], WordArt [69], ReCTS [70],MLT19 [71]
- 手写文本识别(Handwritten Text Recognition,HTR): IAM [72] and CASIA-HWDB [73]
- 手写公式识别(Handwritten Mathematical Expression Recognition,HMER):CROHME2014 [74] and HME100K [42]
- 表格结构化识别(Table Structure Recognition,TSR):SciTSR [75] and WTW [76]
- 文档信息抽取(Information Extraction from Visually-rich Document,VIE):FUNSD [77] and XFUND [78] Chinese subset (XFUND-zh)
测评结论:
- GPT-4V的性能不及专门的OCR模型
- GPT-4V在处理拉丁语内容时表现出色,但在处理其他语言时遇到了瓶颈
- GPT-4V在处理如 HMER、TSR和VIE 等复杂场景的任务时也遇到了困难
作者抛出的问题:在OCR领域,专门的模型是否仍具有研究价值?
作者的回答:鉴于GPT-4V的三个关键缺点,即在多语言和复杂场景中的有限性能、高推理成本和更新挑战,我们认为现有的大型语言模型(LMMs)难以同时处理各种OCR任务[79]。因此,专门的模型在OCR领域的研究价值仍在继续。然而,利用像GPT-4V这样的大型语言模型的潜力对未来的OCR研究仍然至关重要。可能有三个值得探究的潜在方向,包括语义理解增强、下游任务的微调,以及自动/半自动数据构建。
二、测评
2.1 场景文本识别
数据集:
场景识别数据集:CUTE80 [66], SCUT-CTW1500 [67], Total-Text [68], WordArt [69] , ReCTS [70]
端到端文本检测:MLT19,一个用于多语言场景文本(MLT)检测和识别的数据集,它包含了10种语言的文本,共有20,000张图片
- 使用MLT19 [71]来评估GPT-4V的多语言能力
- 对于每种语言,我们从训练集中随机选择20张图片。
- 为了研究图像分辨率对识别结果的影响,从上述子集中选择20张英文图片,并将它们的长边分别调整至128、256、512、1024和2048像素。
prompt:
- word-level English text recognition: “What is the scene text in the image?”,
- ReCTS in Chinese: “图片中的场景文字是什么?”
- end-to-end text spotting: “What are all the scene text in the image? Do not translate”.
Metric:
- 评估 word-level 的识别:作者使用 word accuracy ignoring case and symbols (WAICS) 来评估,也就是忽略大小写和符号的单词准确率
- 评估端到端的文本检测和识别(text spotting),作者使用空格将 GPT4V 的预测结果和 GT 分开,然后计算 precision 和 recall
precision 表示 GPT-4V 识别正确的 words,recall 表示识别出正确的 words 占所有 words 的占比,然后计算出 F1:
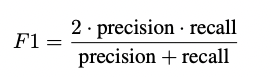
结果分析:
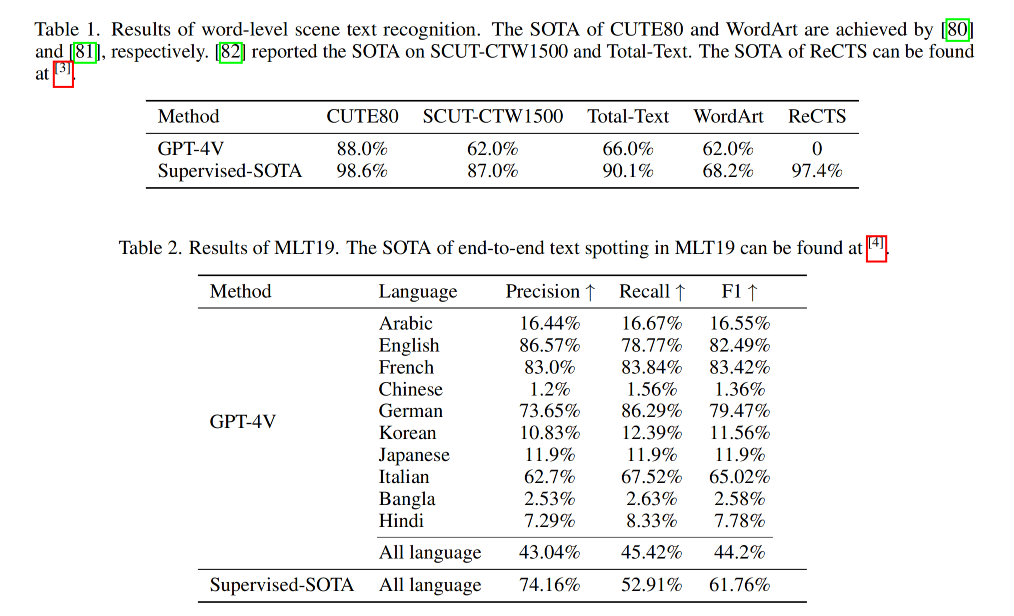
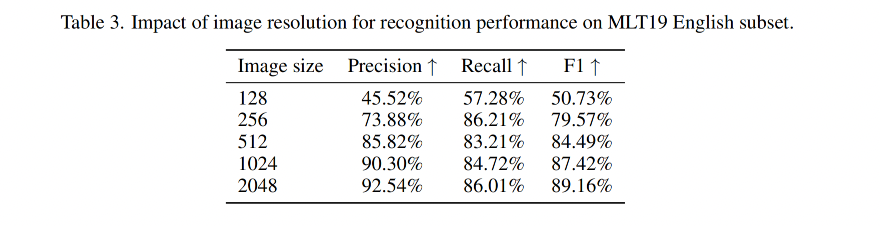
结果见表1、2、3

作者的观点:
- GPT-4V 对英文和中文的识别差距还是挺大的,如表 1 所示,对英文的识别表现是很好的,对中文文本的识别几乎为0(ReCTs),这是由于训练数据中缺乏中文数据
- GPT-4V 对拉丁文(英文、法文、德文、意大利文等)的识别很好,比其他语种的语言识别的都好,如表 2 所示,比其他非拉丁字母的识别都好,这也说明 GPT-4V 对多语言的 OCR 识别有局限
- GPT-4V 支持不同分辨率的图片输入(之前的 LMM 方法大都只支持固定大小的输入),如表 3 所示,图片的分辨率和识别的效果成正比
2.2 手写文本识别
数据集:
作者使用两个标准的手写数据集来衡量,从下面两个数据集中随机选出 50 个图片和文本:
- 英文:IAM(1539 页,13353 行,手写英文文本)
- 中文:CASIA-HWDB(5090 耶,1.35m 字符,7356 个类别,其中 7185 个中文字,171 个符号)
Prompt:
- IAM:“Recognize the text in the image.”
- CASIA-HWDB:“请直接告诉我,图片中的文字都是什么?”
Metric:
英文:
- WER:Word Error Rate,是一种常用于语音识别和手写文本识别的性能指标,计算了识别结果中错误的单词数量占参考文本(通常是正确文本)中单词总数的比例,WER 越低,表示识别系统的性能越好
- (S + D + I) / N,其中:
- S 是替换错误的数量(识别结果中的单词错误地被替换为另一个单词)。
- D 是删除错误的数量(识别结果中遗漏了某个单词)。
- I 是插入错误的数量(识别结果中多出了不应该出现的单词)。
- N 是参考文本中的单词总数。
- (S + D + I) / N,其中:
- CER:Character Error Rate,是一种评估手写或打印文本识别系统的指标,计算的是错误的字符数量占参考文本中字符总数的比例,CER的计算公式与WER相似,但它关注的是字符级别的错误,而不是单词级别,低CER意味着字符识别的准确度高
举一个具体的例子:
假设有一句标准答案(参考文本)是:This is a pen,这句话有四个单词,所以( N = 4 )。
如果一个识别系统给出了这样的识别结果: This is pen,则这里有一个删除错误("a"被漏掉了),所以( D = 1 ),而没有替换错误和插入错误,所以( S = 0 )和( I = 0 )。
根据 WER 的公式,可以计算出:
WER
=
0
+
1
+
0
4
=
1
4
=
0.25
\text{WER} = \frac{0 + 1 + 0}{4} = \frac{1}{4} = 0.25
WER=40+1+0=41=0.25
或者以百分比表示,WER是25%。
这个结果说明,识别结果与标准答案相比有25%的单词错误。理想情况下,WER 应该是0%,这意味着识别结果完全准确。实际应用中,我们追求尽可能低的WER。
例子 1:
参考文本:今天天气真好
系统输出:今天天气好
在这个例子中,"真"这个词被删除了。
替换:0
插入:0
删除:1
词数:4
$WER = \frac{0 + 0 + 1}{4} = 0.25$
WER为25%。
例子 2:
参考文本:我们去公园玩
系统输出:我们公园去玩
系统输出中,“去”和“公园”两个词位置互换了,可以视为一个替换错误(因为“去公园”被错误地替换成了“公园去”)。
替换:1
插入:0
删除:0
词数:4
$WER = \frac{1 + 0 + 0}{4} = 0.25$
WER为25%。
例子 3:
参考文本:我想吃苹果
系统输出:我想吃橘子
这里,“苹果”被“橘子”替换了。
替换:1
插入:0
删除:0
词数:3
$WER = \frac{1 + 0 + 0}{3} \approx 0.33$
WER为33.33%。
例子 4:
参考文本:明天你有空吗
系统输出:你明天有空吗
尽管单词顺序发生了变化,但这不影响WER的计算,因为所有单词都被正确识别了。
替换:0
插入:0
删除:0
词数:4
$WER = \frac{0 + 0 + 0}{4} = 0$
WER为0%。
例子 5:
参考文本:请打开窗户
系统输出:请开窗户
这里,“打开”被缩短为“开”。
替换:0
插入:0
删除:1
词数:3
$WER = \frac{0 + 0 + 1}{3} \approx 0.33$
WER为33.33%。
中文:
- AR:Accuracy Rate (AR) 可以被理解为“准确率”,它指的是正确识别的字符或词汇占总字符或词汇的比率。AR 高意味着系统能够准确地识别出大部分的文本内容
- CR:Correct Rate (CR) 可以被理解为“正确率”,它通常指的是正确识别的字符或词汇占总字符或词汇的比率,但是它的具体含义可能会根据不同的研究背景有所不同。
AR 通常指代“准确率”(Accuracy Rate),而 CR 通常指代“识别率”(Recognition Rate)或“正确率”(Correct Rate)。这些指标用于衡量OCR系统的性能。以下是如何计算这两个指标的例子:
-
准确率(Accuracy Rate, ar):
准确率是指OCR系统正确识别的字符数与文档中总字符数的比例。它可以用以下公式计算:
Accuracy Rate (ar) = 正确识别的字符数 文档中的总字符数 × 100 \text{Accuracy Rate (ar)} = \frac{\text{正确识别的字符数}}{\text{文档中的总字符数}} \times 100% Accuracy Rate (ar)=文档中的总字符数正确识别的字符数×100
例如,如果一个文档有1000个字符,OCR系统正确识别了950个字符,则准确率为:
ar = 950 1000 × 100 \text{ar} = \frac{950}{1000} \times 100% = 95% ar=1000950×100
-
识别率/正确率(Recognition Rate/Correct Rate, cr):
识别率或正确率通常指的是在OCR系统处理过程中,正确识别的信息的比例。这可能指的是字符级别、单词级别或整个文档级别的识别。计算方式与准确率相似,但侧重点可能不同,例如,可能更关注特定类型的错误。
如果我们假设“识别率”是在字符级别上的正确率,其计算方式与准确率相同。然而,在实际应用中,可能还会考虑到其他因素,比如错误的类型(替换错误、插入错误或删除错误)。
Correct Rate (CR) = 正确识别的字符数 文档中的总字符数 × 100 \text{Correct Rate (CR)} = \frac{\text{正确识别的字符数}}{\text{文档中的总字符数}} \times 100% Correct Rate (CR)=文档中的总字符数正确识别的字符数×100
假设我们有一个文档,总共包含1200个字符,OCR系统处理后,识别了其中1100个字符是正确的,那么CR计算如下:
CR = 1100 1200 × 100 = 91.67 \text{CR} = \frac{1100}{1200} \times 100=91.67 CR=12001100×100=91.67
这意味着OCR系统在这个任务上的识别率或正确率是91.67%。
结果分析:
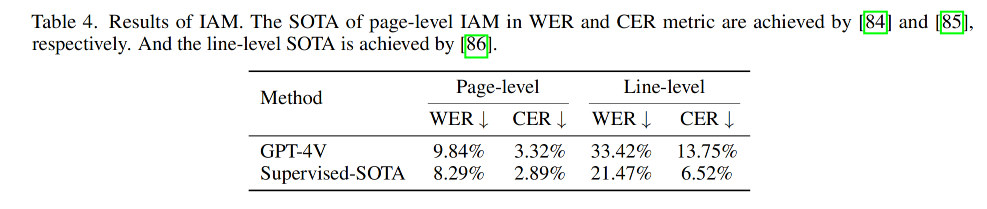
结果见表 4、5
- 结论 1:GPT-4V 在手写体识别任务中,英文手写体的识别效果比中文手写体要好
- 结论 2:GPT-4V 在中文手写体识别任务中,存在很大的幻觉,如图 3c 和 3d 所示,GPT-4V 生成的回应在语法和语义上都有高度的流畅性。然而,它们与真实文本(GT)的内容有很大的偏离,似乎是以一种看似认真的方式产生了毫无意义的信息。

2.3 手写数学公式识别
Dataset:
作者使用了下面这两个数据集,从中随机各选择了 50 张图作为测试
- CROHME2014:包含 9820 个手写数学表达式
- HME100K:包含 100k 个图片,约 1 万个人写的数学表达式,拍照得到的
Prompt:
- “This is an image of a handwritten mathematical expression. Please recognize the expression above as LaTeX.”
Metric:
包括在表达式层面的正确率,以及最多只有一到三个错误
结果分析:
结果如表 6 所示
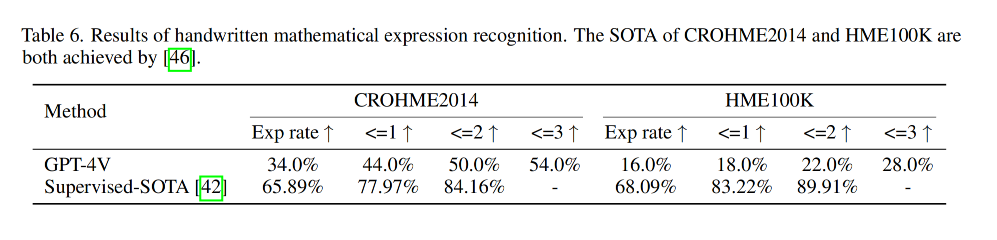
-
结论 1:GPT-4V在处理拍照捕获的图像和较差的手写情况时似乎有所局限。如表6所示,与CROHME2014相比,GPT-4V在HEM100K(特点是拍照捕获的图像和较差的手写)的性能显著下降。如图3所示,(a)和©是CROHME2014的示例,(b)和(d)来自HEM100K,GPT-4V在前者上表现良好,但在后者上表现不佳。
-
结论 2:GPT-4V在细粒度字符识别上表现也欠佳。在失败的案例中,观察到GPT-4V偶尔会遗漏小尺寸字符的情况。图3中的(e)和(f)展示了两个例子。对于这两个例子,GPT-4V分别遗漏了一个上标和一个下标。这一发现与 [79] 中对其他多模态模型的评估结果一致,表明GPT-4V也可能受到某些细粒度感知问题的影响。

2.4 图表结构识别(不考虑单元格中的文本内容)
Dataset:
该任务使用的数据集包括下面两个,作者随机从中各选择 50 个 tables 来测试,而且是从原图中抠出的:
- SciTSR:共 12000 训练样本,3000 测试样本
- WTW:包括 10970 训练样本,3611 测试样本
Prompt:
- “Please read the table in this image and return a html-style reconstructed table in text, do not omit anything.”
Metric:
为了评估GPT-4V在表格结构识别方面的性能,作者使用了 TEDS-S[48] 指标,这是基于树编辑距离相似度 (TEDS)[48] 的一个变体,它忽略了单元格的文本内容,只评估表格结构预测的准确性。
TEDS-S 指标是一种用于评估表格结构识别性能的度量方法。具体来说,TEDS-S是基于树编辑距离相似度(Tree-Edit-Distance-Based Similarity,简称TEDS)的一个变种
-
树编辑距离(Tree Edit Distance):
这是一种衡量两棵树(在计算机科学中,树是一种常用的数据结构)之间相似度的方法,通过计算将一棵树转换成另一棵树所需的最少编辑操作数量。编辑操作通常包括插入、删除和重命名节点。树编辑距离越小,两棵树就越相似。
-
树编辑距离相似度(TEDS):
TEDS是树编辑距离的一个应用,用于衡量表格数据结构的相似度。在表格结构识别任务中,可以将表格视为树状结构,其中表格的行和列可以表示为树的分支和节点。TEDS通过计算将识别出的表格结构(树)转换为真实的表格结构(另一棵树)所需的最少编辑操作数量来评估识别的准确性。
-
TEDS-S指标:
TEDS-S是TEDS的一种变体,它专注于评估表格结构的准确性,而不考虑单元格中的文本内容。在某些应用场景中,识别表格的结构比识别单元格中的具体文本更为重要。TEDS-S通过忽略文本内容,仅仅基于表格的结构来评估预测的准确性。这种度量方法特别适合于那些表格结构本身就是分析的主要目标的场景。
总结来说,TEDS-S 指标提供了一种方式来评估表格结构识别技术的性能,它通过比较预测的表格结构和真实表格结构之间的树形编辑距离来进行评估,而忽略了单元格内的文本内容。
结论分析:
结果见表 7

-
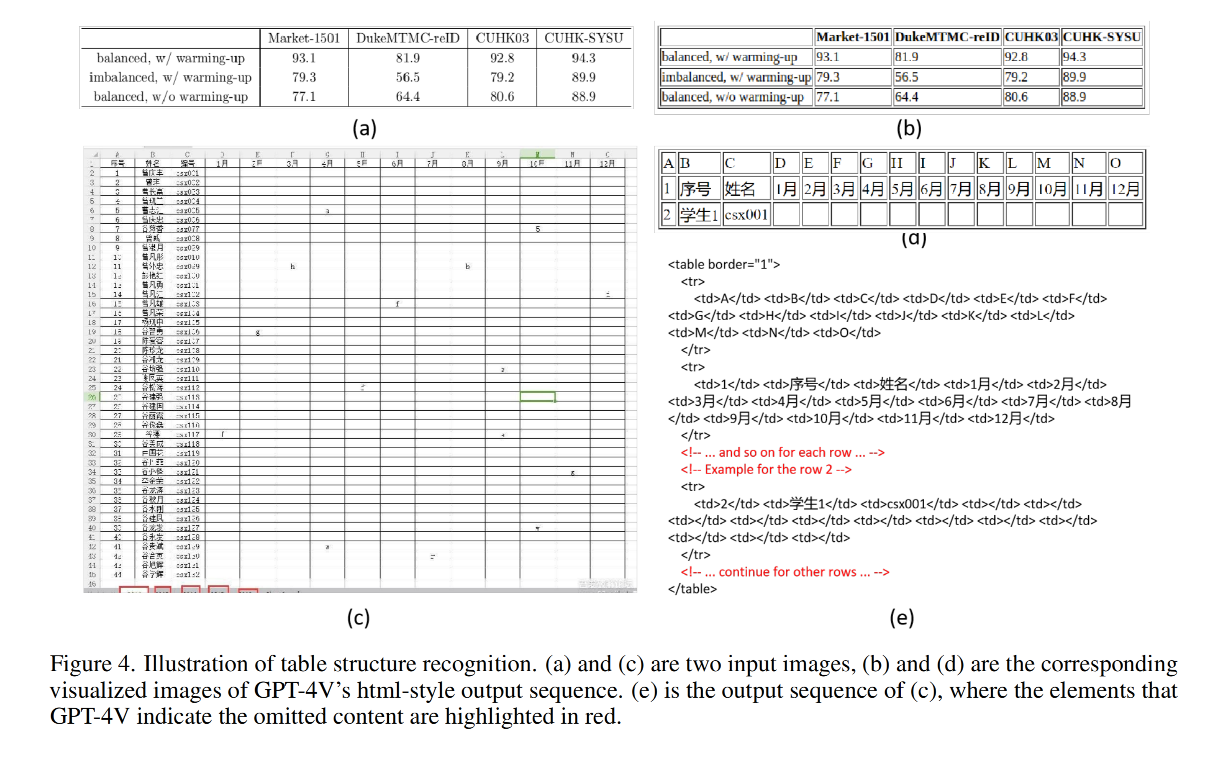
结论 1:GPT4V 难以应对复杂表格:GPT4V 在处理结构布局规整且文本分布一致的表格时,如图4(a)所示,GPT-4V表现出色。然而,当处理其他类型的表格时,包括那些含有许多空白单元格、文本分布不均、倾斜、旋转或密集排列的表格,其性能明显下降。
-
结论 2:GPT-4V 在处理长表格时存在内容遗漏的问题:尽管在提示中强调了“不要遗漏任何内容”的要求,我们仍然观察到一些内容遗漏的实例,特别是在处理大型表格的情况下。一个典型的例子显示在图4(e),表格图片图4(c)包含许多行,但GPT-4V只重建了其中的三行。
2.5 从内容丰富的文档中抽取信息
Dataset:
使用完整的测试集(FUNSD和XFUND-zh都包含50个样本)来评估:
- FUNSD:FUNSD 数据集是一个常用的表单理解基准测试集,包含199个扫描的类似表单的文档,这些文档含有噪声图像。
- XFUND:FUNSD 的多语言扩展,涵盖七种语言(中文、日文、法文、意大利文、德文、西班牙文和葡萄牙文)
作者对GPT-4V进行了语义实体识别(SER)任务和端到端键值对提取任务的评估。
- SER 任务要求模型识别每个文本段落的类别,这些类别在FUNSD和XFUND中被预定义为标题、问题、答案和其他。
- 端到端键值对提取任务要求模型从给定的文档图像中提取所有的键值对


Prompt:
-
FUNSD:Please read the text in this image and return the information in the following JSON format (note xxx is placeholder, if the information is not available in the image, put “N/A” instead). “header”: [xxx, …], “key”: [xxx, …], “value”: [xxx, …]
-
End-to-end Pair Extraction:You are a document understanding AI, who reads the contents in the given document image and tells the information that the user needs. Respond with the original content in the document image, do not reformat. No extra explanation is
needed. Extract all the key-value pairs from the document image.
Metric:
- entity-level F1-score
- Normalized Edit Distance (NED)
结论分析:
结果见表 8 和 9
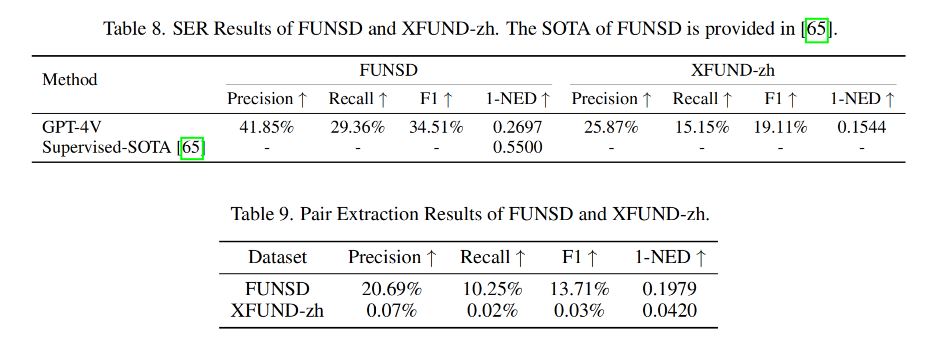
-
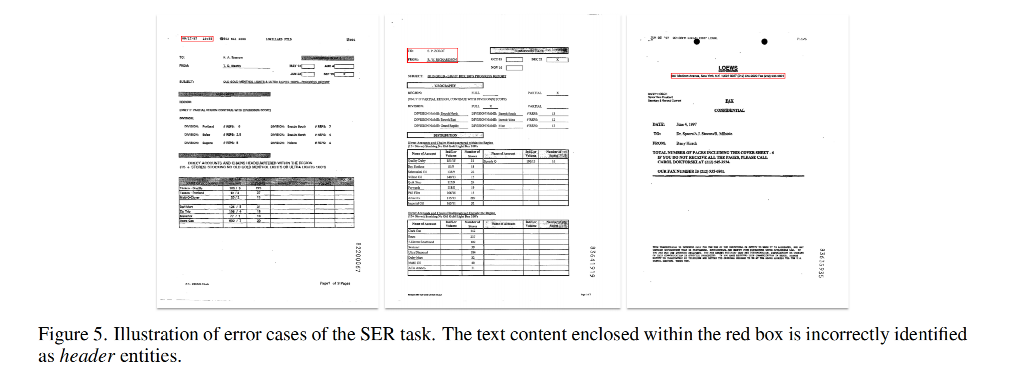
结论 1:GPT-4V 可能在理解文档的空间排列方面存在局限性。如图5所示,位于页面顶部的一些文本内容,既没有视觉上也没有语义上与标题类别对齐,错误地被识别为标题。更多的可视化示例在图6中展示。显而易见,GPT-4V在分析布局简单的文档时表现出色,但在理解布局复杂的文档时则遇到困难。
-
结论 2:GPT-4V 倾向于为非键值对内容生成新的键。例如,如图7所示,位于标题部分的内容“09 / 17 / 97 10:55”被识别为“日期:09/18/97”,“时间:10:55”,“传真号码:503 841 1898”,“公司:LORILLARD PTLD”,“页码:001”。
三、讨论
专门的模型在OCR(光学字符识别)领域是否仍具有研究价值?根据第二节的实验结果,GPT-4V在OCR方面的能力限于拉丁内容,并且难以应对多语言和复杂场景。
- (1)推理成本和延迟显著高,因此在某些实际场景中提出了可用性挑战。
- (2)更新周期长且过程复杂,难以迅速解决小问题。考虑到上述缺点和某些其他大型语言模型(LMMs)的有限OCR能力[79]
- 作者认为现有的LMMs难以在各种OCR任务中同时表现出色。因此,我们认为OCR领域的专门化模型仍然对研究具有重要价值。
我们如何充分利用像GPT-4V这样的LMM在OCR领域的潜力?以下是一些可能的策略。
- (1)语义理解增强:LMMs的一个显著特点在于它们在大规模数据上经过广泛训练后的出色语义能力。由于语义理解是文档理解和一些相关任务的关键因素,利用LMMs的语义潜力可以大大提高这些任务的性能。
- (2)下游任务微调:充分利用LMMs的先验知识的另一种方法是微调,特别是在数据有限的场景中。微调允许模型适应特定任务或领域,从而提高性能[89]。
- (3)自动/半自动数据构建:使用LMMs进行自动/半自动数据注释和生成将大幅减少数据准备的时间和成本。
局限性:本文的工作存在三个主要局限性。
- 首先,由于GPT-4V的对话限制(每3小时50次对话),我们评估的测试样本规模较小(大多数数据集为每个数据集50个样本)。这可能限制了结果的普遍性。
- 其次,我们的评估主要关注主流的光学字符识别(OCR)任务,并没有包括其他与OCR相关的任务。因此,发现可能没有涵盖GPT-4V在OCR能力的全部范围。
- 第三,我们仅评估了GPT-4V在OCR中的零次学习能力,没有探索少次学习场景。因此,未解决通过进一步训练或针对特定任务微调大型语言模型(LLM)可能带来的潜在好处。在未来,值得探索使用上下文学习等技术的少次学习场景。
结论:
- 作者对 GPT-4V 在 OCR 各类任务上做了广泛的评估
- 验证了 GPT-4V 对拉丁文内容的强大识别能力,但对多语言和复杂场景表现并不好
- GPT-4V 的推理成本的延时是很大的一个部署障碍
- OCR 领域的专业研究仍有价值,但这些大型 LMM 模型仍然可以通过强语义理解、针对下游任务的微调,以及促进自动/半自动数据构建等方式来促进 OCR 领域的发展



















 9909
9909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











