








代码:https://github.com/OpenGVLab/InternVL/tree/main/internvl_chat/shell/internvl2.0_mpo
出处:OpenGVLab | 复旦等
时间:2024.11
效果:
- 提出了高效的偏好数据构建pipeline,构建了 MMPR 大规模高质量多模态推理偏好数据,大约包含 3M 样本
- 提出了 MPO,一个高效的 PO 方法用于提升模型的推理能力, InternVL2-8B-MPO 模型能够提升推理能力且降低幻觉
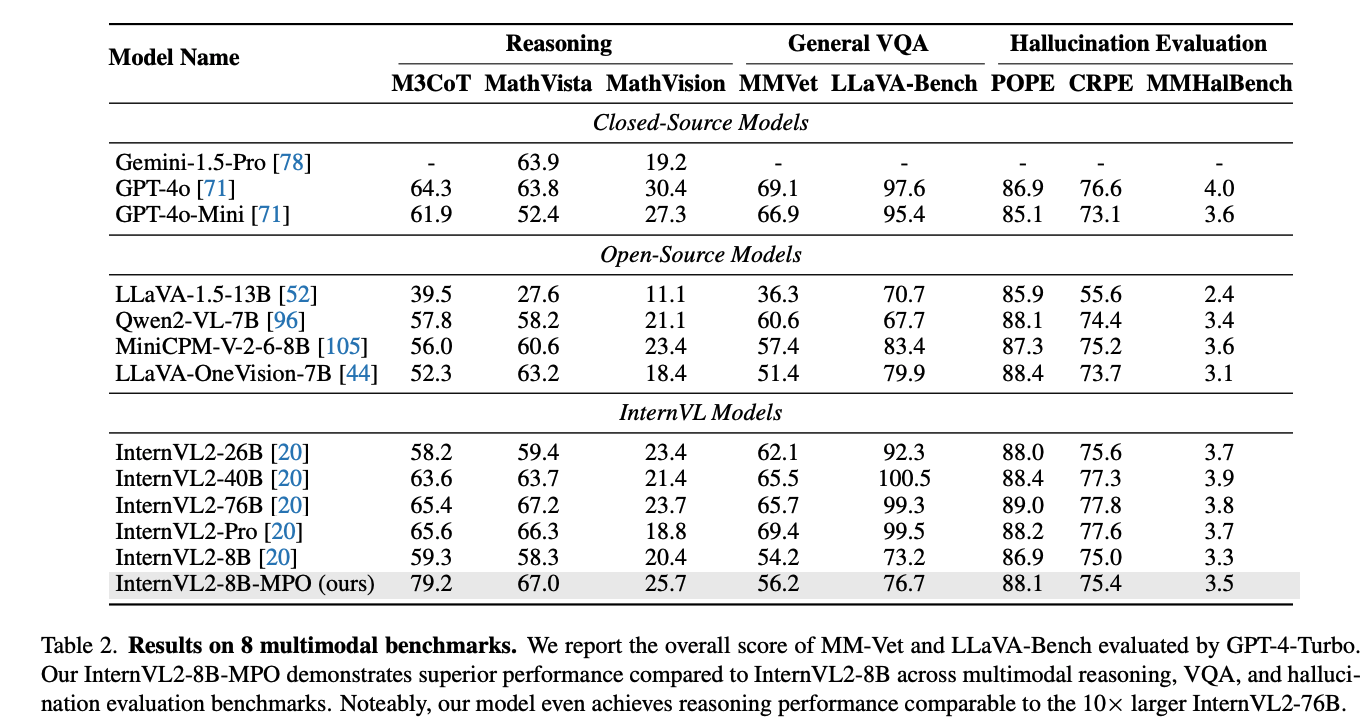
- 首次探究了使用 PO 的方法来提升多模态模型的推理能力, InternVL2-8B-MPO 在 MathVista 上 acc 达到了 67.0,比 InternVL2-8B 高 8.7 个点,和 InternVL2-76B(大10倍)的表现可比
- issue 中有人提出mpo模型的指令跟随能力不如sft模型
一、背景
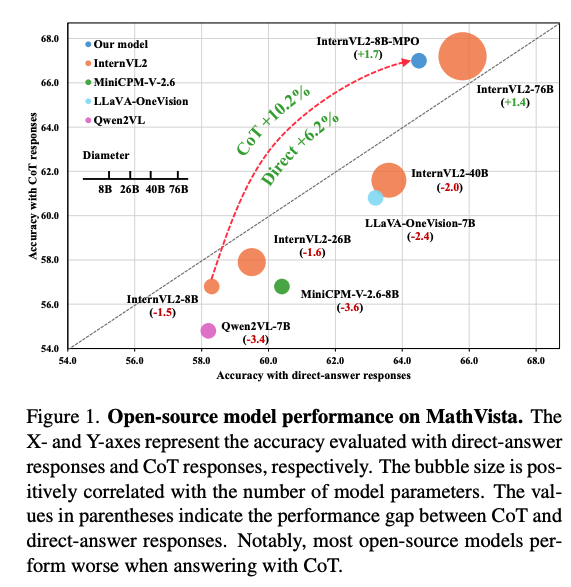
当前的多模态大模型一般有两个训练阶段,分别是预训练和有监督微调,虽然大量数据让模型在某些方面也取得了很好的效果,但这样的训练方式会限制多模态大模型的推理能力,尤其是在链式思维上的效果,如图1所示。
Internvl2-8b 在 MathVista(一个多模态推理的数学数据集)上使用直接回答的方式取得了58.3 分,当使用链式思维推理(CoT)推理时,下降到了 56.8 分。且很多其他模型(Internvl1.5、LLaVA-OneVision、Qwen2-vl、Minicpm-v)也是同样的结论。
究其原因主要是由于 SFT loss 引入的分布偏移, SFT 训练模型是依赖于教师强制训练方法,在这种方法中,模型训练时根据之前的真实标签来预测下一个token。然而,在推理阶段,模型必须基于它们自身先前的输出来预测每个token,这导致了训练和推理之间的分布偏移。由于直接回答方法只需要简短的响应,而CoT(思维链)推理涉及生成较长的推理过程,这使得分布偏移问题在CoT推理过程中变得更加严重。这导致模型在CoT推理方面的表现比直接回答答案的响应更差。
为了解决此问题,本文作者根据之前 NLP 方法中的偏好优化(preference optimization,PO)方法来对齐模型输出和期望得到的推理结果。
DPO(直接偏好优化)能够让模型从偏好信息中学习生成能和用户需求对齐的响应,是 Reinforcement Learning from Human Feedback (RLHF) 的基础。尽管RLHF(基于人类反馈的强化学习)在多模态大模型(MLLMs)中主要被用于减少幻觉现象 [18, 85, 106],但将其应用于增强多模态推理的研究仍然不够深入。基于此,作者尝试使用PO来加强多模态大模型的多模态推理能力。
使用 PO 的方法来提升多模态大模型的推理能力有很多挑战:
- 多模态推理偏好数据缺乏,标注代价大:现有的多模态偏好数据集主要是为了解决幻觉问题,所以主要是一些自然图像,缺少科学类和推理类的图像,标注起来也很费时费力
- 缺乏使用 PO 提升多模态推理能力的开源方法:很多 PO 的方法都是为了减轻幻觉,评价指标也是在幻觉benchmark上的提升而非推理能力上的提升,所以验证 PO 对多模态推理能力的提升还需要更多的探究
所以,本文的方法同时从数据和模型两个方面出发:
- 数据方面:设计了一套自动化的偏好数据收集pipeline,构建了一个高质量大规模的多模态推理偏好数据集 MMPR
- 模型方面:探究了多种不同的 PO 方法,引入了一个简单有效的方法 Mixed Preference Optimization (MPO),在不需要 reward model 的前提下能够提升多模态模型的 CoT 表现
如何自动化生成数据:
- 作者提出了一种 continuation-based pipeline 方法,称为 Dropout Next Token Prediction(DropoutNTP),适用于无明确真实答案的样本,以及一种 correctness-based pipeline 方法,适用于具有明确真实答案的样本。
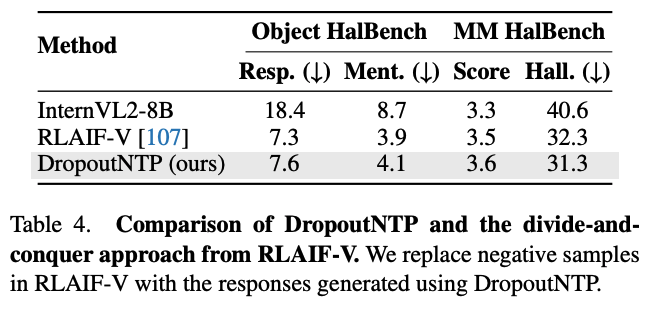
- 在无真实答案的数据中,也就是 DropoutNTP 中,由 InternVL2-8B 生成的响应被视为 positive samples。对于给定的响应,作者将其截断一半,然后提示InternVL2-8B在没有图像输入的情况下完成截断的回答部分。这个生成的补全部分作为配对样本的 reject answer。在第5.2节的实验结果表明,与RLAIF-V [107]中提出的分而治之方法相比,这种直截了当的方法在减少幻觉方面实现了可以媲美的性能。
- 在有真实答案的数据中,会让 InternVL2-8B 对一个问题进行多次回答。与真实答案匹配的回答被用作 chosen responses,而不匹配的则被用作 rejected responses。
MPO 方法:
- 作者提出的 MPO 方法的关键在于,一个有效的PO过程应使模型能够学习到响应pair之间的相对偏好、单个响应的绝对质量以及生成偏好响应的过程。
- 与先前的多模态PO方法 [47, 75, 85, 106, 107, 111] 相比,MPO 方法在以下几个方面表现出色:
- (1)高效的自动化数据构建流程:本文数据构造流程能够以可控成本生成高质量的偏好对。
- (2)在不同领域的有效性:使用本文的数据和方法微调的模型在推理、问答和幻觉基准测试中表现优异。
- (3)相对于最先进设置的改进:本文的结果基于InternVL2-8B,这是领先的开源多模态大模型之一,具有很好的潜力。
- 本文研究表明,PO不仅可以减轻幻觉现象,还可以增强多模态推理能力
二、方法
2.1 MMPR 数据集构造方法
作者提出了偏好数据构建流程,构建了 million-level MultiModal PReference dataset (MMPR) 数据集
MMPR 数据集的结构:
- 图像 Image
- 指令 Instruction
- 正确的回答 chosen response
- 拒绝的回答 rejected response
对于有清楚正确答案情况的 instruction:
- prompt 提示模型先提供推理过程,后输出最终结果例如:"Final Answer: *** "
- 与标准答案匹配的响应构成正集合Yp,而不匹配的响应构成负集合Yn。同时,未能提供明确最终答案的响应也会被合并到Yn中。根据这些标记为正面或负面的响应,通过选择来自Yp的一个响应yc和来自Yn的一个负面响应yr来构建偏好对。
对于没有清楚正确答案情况的 instruction:
- 使用 Dropout NTP,具体来说,直接将生成的所有响应视为正集合Yp。然后从Yp中抽样一个响应y,并截断该响应的后半部分,然后让模型在没有图像输入的情况下预测被截掉的部分。
- 虽然这里将生成的答案直接作为正确答案不是很完美,但截断后且无图像输入的预测结果肯定包括更多的幻觉和错误,所以能够组成一对儿样本
和之前方法的对比:
- RLAIF-V 中提出了分而治之的方法来生产数据,比较复杂
- 本文的数据生产方法更加高效
- 以 M3CoT 的数据生成为例,本文 pipeline 每生成一个偏好配对会产生 571.2 个 token 的成本,而 RLAIF-V 中使用的分而治之方法则需要 992.7 个 token。因此,本文数据生产成本仅为 RLAIF-V 的 57.5%。
2.2 MMPR 数据集示例和数据分布
数据分布:该数据集包含大约 750k 无明确参考答案的样本和 2.5M 有明确参考答案的样本。
- 对于无明确参考答案的样本,每条指令平均包含25.0个token,而被选中的和被拒绝的响应分别平均包含211.4个和171.2个token。最长的被选中和被拒绝的响应分别包含1,342个和1,642个token,而最短的被选中和被拒绝的响应分别包含20个和17个token。
- 对于有明确参考答案的样本,指令的平均长度为79.5个token,被选中的和被拒绝的响应分别平均包含300.0个和350.5个token。最长的被选中和被拒绝的响应分别包含2,018个和4,097个token,而最短的响应分别包含32个和33个token。

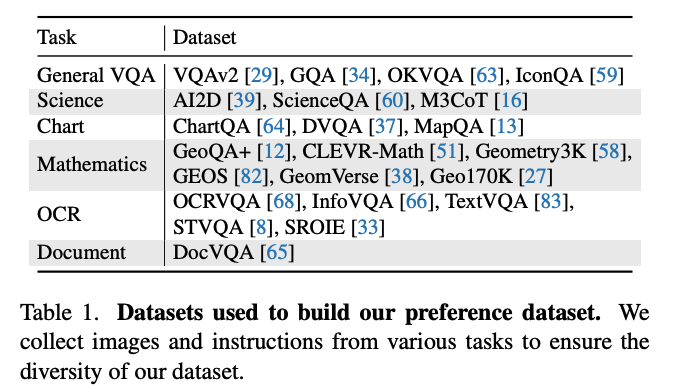
数据源:
2.3 如何使用偏好优化来提升模型效果
混合偏好优化(MPO)方法将监督微调(SFT)损失与多种偏好优化损失相结合,以提高训练效果。此外,还研究了结合多模态输入的不同链式思维(CoT)方法,以提升推理性能。
2.3.1 混合偏好优化
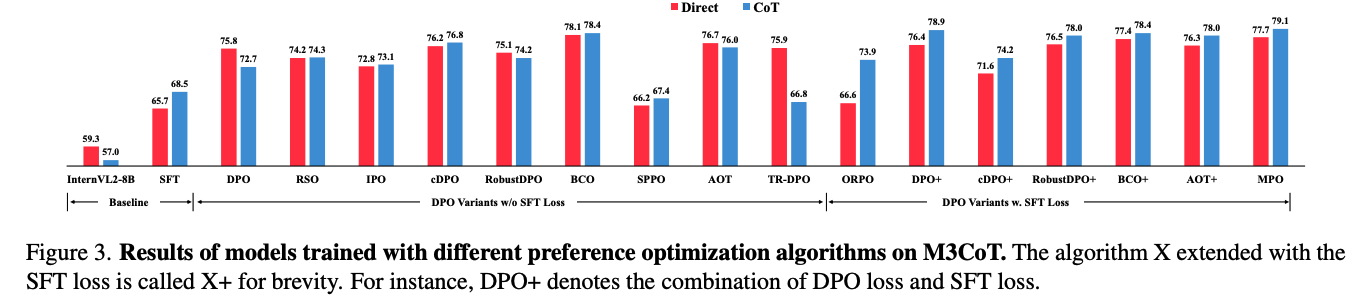
当多模态大语言模型(MLLMs)在大规模偏好数据集上使用直接偏好优化(DPO)进行训练时,它们可能无法生成合理的推理并产生无意义的内容。这一现象与Smaug [73] 中的分析一致。为了解决这个问题,本文引入了混合偏好优化(MPO),旨在学习响应对之间的相对偏好、单个响应的绝对质量以及生成优选响应的过程。
训练 loss:由三部分组成
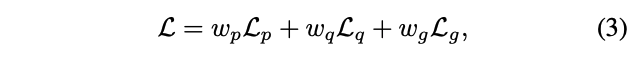
- preference loss(DPO):让模型在 chosen 和 rejected response 中选择相对的偏好,DPO 基于Bradley-Terry模型[9]的假设,避免了训练显性奖励模型的需求,公式如下所示, β \beta β 是 KL 惩罚系数,x 是 user query,yc 是 chosen response,yr 是 rejected response,策略模型 πθ 从模型 π0 初始化。
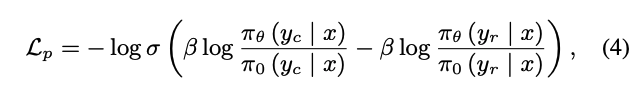
- quality loss(BCO loss):帮助模型理解每个 response 的绝对质量,也就是训练一个二分类器,选择的response 的 logits 被映射为 1,拒绝的 response 的 logits 被映射为 0。loss 如下, L q + L_q^+ Lq+ 为 chosen 的loss, L q − L_q^- Lq− 为 rejected 的 loss
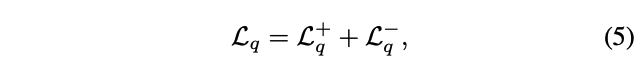
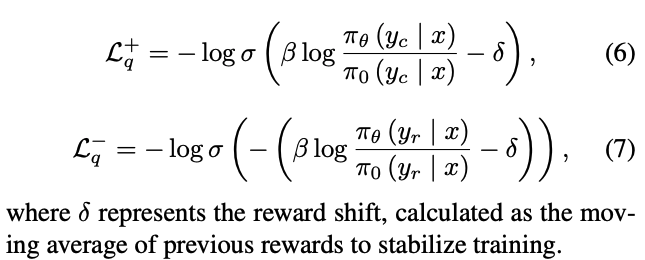
- generation loss(sft loss):用于生成偏好响应
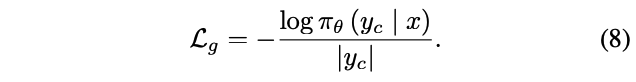
2.3.2 多模态模型链式思维方式输入
在数据采样过程中,需要模型提供详细的链式思维(CoT)推理过程,而不是直接回答最终答案。对于大多数样本,作者使用图2底部案例中显示的提示来采样响应,该提示要求模型进行逐步分析。
考虑到多模态模型涉及非文本输入,进一步引入以下CoT方法:
- (1)基于背景知识的CoT:模型首先介绍与问题或图像相关的背景知识,然后是推理步骤和最终答案。这种方法适用于科学领域的样本。
- (2)基于视觉内容的CoT:模型首先分析图像中的视觉内容,然后进行推理和给出最终答案。这种方法用于图表、OCR和文档领域的样本。
- (3)基于位置的 CoT:模型在生成文本响应的同时,将响应中引用的所有对象链接到图像中的相应区域。这种方法适用于一般的VQA领域样本。
- 上述CoT方法生成的响应与使用图2底部案例中显示的提示采样的响应混合。这些方法不仅有效地将多模态信息整合到推理过程中,还提高了数据的多样性。此外,在响应开始时包含背景知识和视觉内容也提高了由DropoutNTP生成的负面响应的质量,防止正负样本之间出现显著质量差异,从而降低训练效果。
三、效果
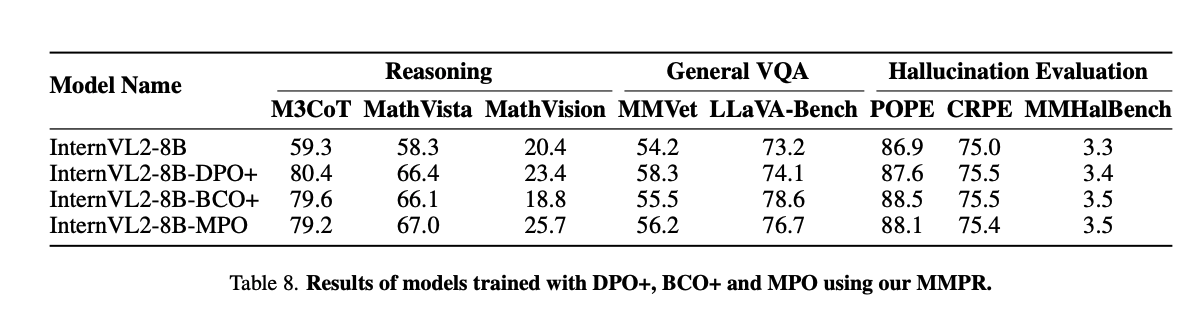
1、总体效果
2、消融实验
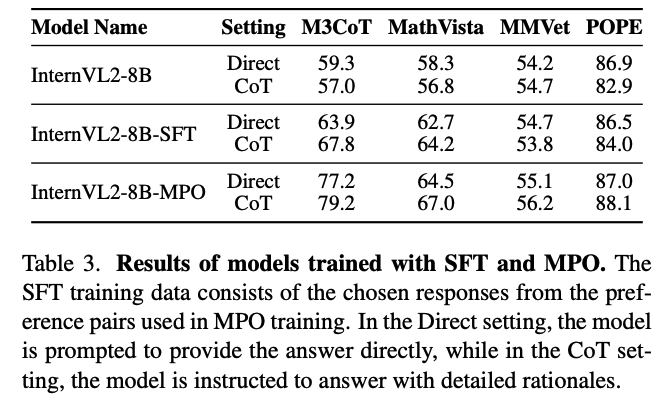
MPO 和 SFT 的对比:
作者使用 MMPR 数据集分别作为 SFT 数据和 MPO 数据来微调 InternVL2-8B,结果如表 3,结果显示 MPO 的结果更好
和 RLAIF-V 的数据对比:
不同 PO 方法的效果对比:
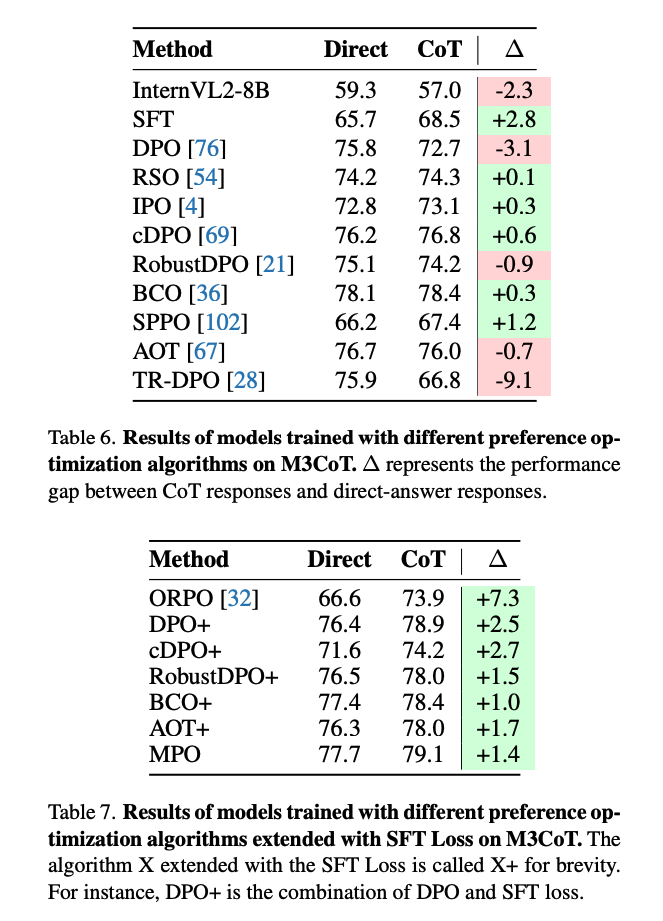
纯文本数据集效果对比:

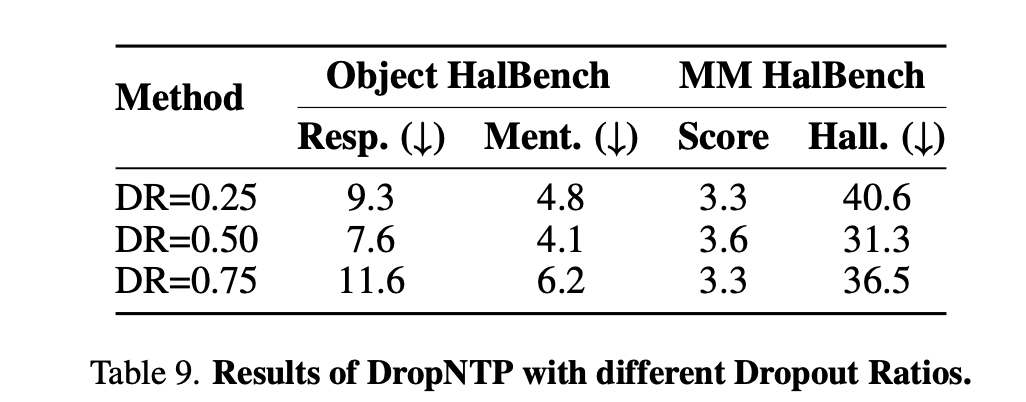
生成 rejected answer 的截断率对比:0.5 是最好的,也就是从一半截断
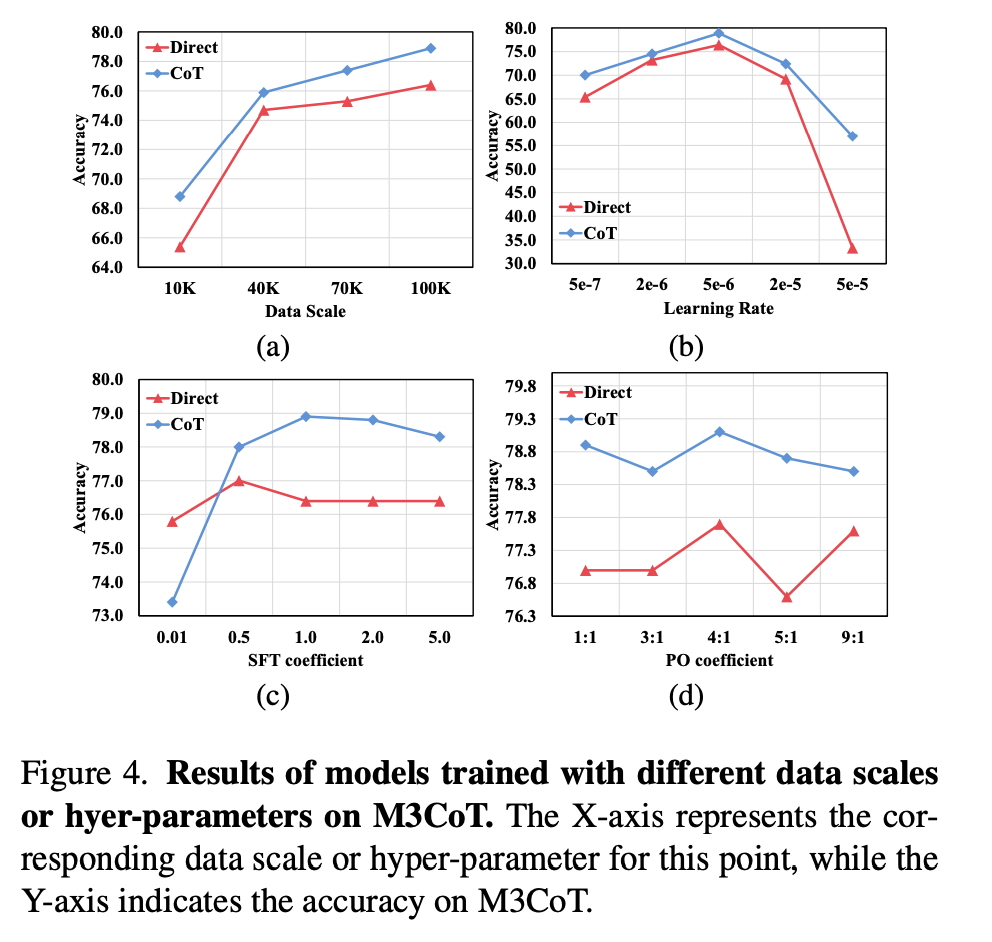
Data scale 的效果:图4a,100k的效果最好
学习率等超参数:图4b
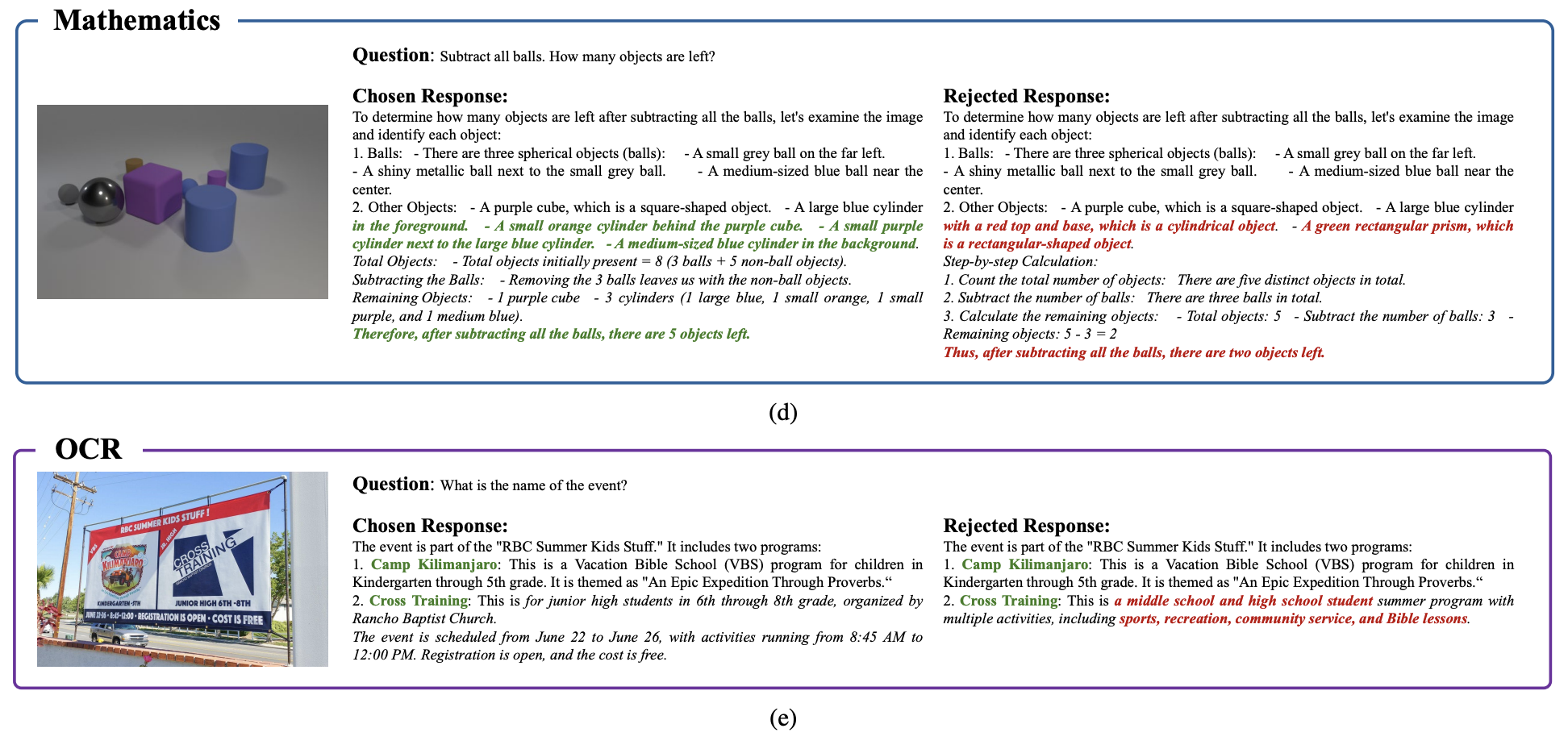
3、MMPR 数据示例























 1522
1522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











