







目录
采样为什么是困难的(the curse of high dimensionality)
基于概率分布的采样Inverse Transform Sampling
MCMC背景
在统计学中,经常会遇到高维积分的计算,用传统的数值方法往往很难解决高维积分计算问题。不过,通过随机模拟的方法为解决这些高维积分问题提供了一个思路。所谓随机模拟方法,是使通过随机变量函数的概率模拟或随机抽样求解工程技术问题的近似数值解的概率统计方法。
马尔可夫链蒙特卡洛MCMC,就是其中一种应用广泛的模拟方法,使得统计学领域中极大似然估计、非参数估计、贝叶斯统计学等方向上的很多问题得到了解决。
本次学习笔记参考了网络很多资源,就不列举了,这里推荐下,B站的机器学习白板推导系列。
关于采样的理解
什么是采样
所谓采样,简单来说就是按照某个概率分布(概率密度函数),生成一批样本。比如下面按照均匀分布进行离散采样。假设离散变量r有3个取值,a1,a2,a3,概率分布如下图所示:
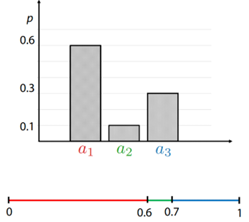
所有取值概率之和为1。此时我们可以从 Uniform[0,1) 生成一个随机数 b,若 0≤b<0.6,则选择出 a1;若 0.6≤b<0.7,则选择出 a2;若 0.7≤b<1,则选择出 a3。
为什么要采样
采样的动机通常有两种:
- 机器学习中,如果你已经通过训练学习出来一个模型,可能是个很复杂的概率分布函数。在推理阶段,需要从训练的概率分布中,产生一些样本。比如VAE、GAN生成模型中,输入一张图片到模型里,会生成一张新的图片,这个新生成的图片就是从概率分布中采样得到的。
- 简化对于复杂函数求和或求积分的运算,近似求解,比如蒙特卡洛积分。如果我们要计算上图中f(x)在[a, b]区域的面积。
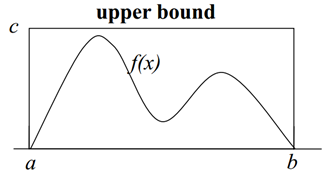
我们可以产生N个服从均匀分布的样本。然后统计处于函数f(x)曲线之下样本点的数量。这里就是采样的动机。
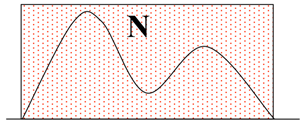
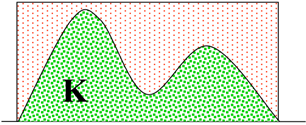
因此最终的面积为,![]()
什么是好的样本
如果我们从P(x)分布中采集了N个样本,如何让这些样本点充分地表达P(x)?
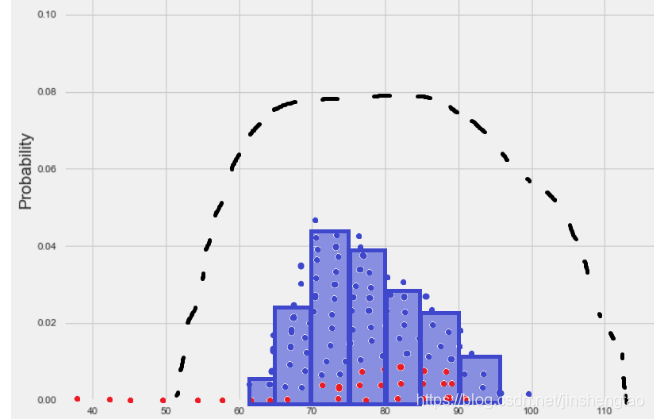
如上图所示,这些样本点应该大部分集中在高概率区域,概率越低的地方,样本点越稀疏。如果大部分样本点在低概率区域,那么这种采样就是失败的,无法表达当前分布。
如果上图表达了某国公民的财富的分布,虽说大部分人都是韭菜或者绵羊,但是从客观统计财富分布的情况,样本之间还是要有一定限制的,它们应该是相互独立的。比如,即使是收集了10个码农的存款数据,那么这10个码农也不要在同一家公司里,不然重复统计,相关性太强的样本,没有意义。
因此,好样本应该是,
(1)样本点趋向高概率区域,同时兼顾低概率区域。
(2)样本点之间相互独立
采样为什么是困难的(the curse of high dimensionality)
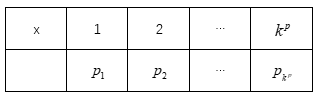
假设变量x是p维的,且每个维度有k种取值,即![]() ,那么总的状态空间复杂度维
,那么总的状态空间复杂度维![]() ,且每个状态有自己的概率。为了使样本趋于高概率区域,不可能遍历每个状态的概率值,看看哪个高,哪个低。
,且每个状态有自己的概率。为了使样本趋于高概率区域,不可能遍历每个状态的概率值,看看哪个高,哪个低。
蒙特卡洛采样方法
许多科学问题的基本部分都是计算下面形式的积分![]()
这里f(x)是感兴趣的目标函数,D通常是高维空间种的一个区域。通常情况下,如果问题稍微复杂一点,这个积分就难以计算。但是根据数学期望的定理,我们可以另辟蹊径。
若随机变量Y符合函数![]() ,
,![]() 为概率密度函数,且
为概率密度函数,且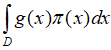 绝对收敛,则有:
绝对收敛,则有:
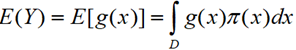
根据上述定理,如果f(x)可以被分解成一个函数g(x)与一个概率密度函数f(x)的乘积,那么上述f(x)积分可以看作是g(x)在密度![]() 下的期望。另外,我们求E(Y)时不需要算出Y的概率分布,只要利用X的概率密度即可。
下的期望。另外,我们求E(Y)时不需要算出Y的概率分布,只要利用X的概率密度即可。
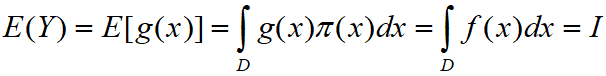
这样,如果我们能得到![]() 的独立样本
的独立样本![]() ,就能获得I的近似值
,就能获得I的近似值![]() ,
,
![]()
由大数定理有,![]()
这就是Monte Carlo积分,接下来我们关心从已知分布中怎么采样。目前的统计模拟方法从抽样分布是否改变角度可以分为静态蒙特卡洛与动态蒙特卡洛方法。静态蒙特卡洛方法是对独立同分布随机变量模拟抽样,包括逆变换法(Inverse Transform Sampling)和拒绝采样(Rejection Sampling)。动态蒙特卡洛本文此次讲解MCMC中最常见的Metropolis-Hasting法。
基于概率分布的采样Inverse Transform Sampling
该方法就是基于累计分布函数的逆函数进行采样。给定目标密度函数后,通过求累计密度函数的逆函数能够将任何形式的随机变量转化为均匀分布随机变量,也就是用均匀分布的随机变量带入逆函数中来模拟目标分布。
下面是示例,从离散的一维的累计分布中采样,即从数字1到N抽样,使得样本逼近当前的概率分布。

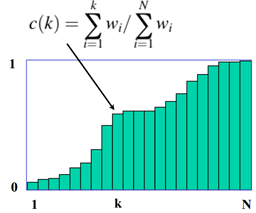
累积分布函数为,
![]()
累积分布函数的逆函数为,
![]()
在计算了累计概率分布后,每次采样,从[0,1]中按照均匀分布生成随机数字u。然后根据u查询累计概率分布函数,得到采样样本j,如下图所示
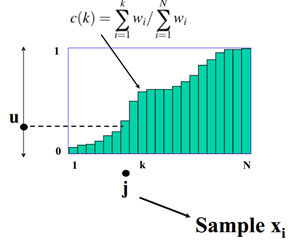
举例:
假设现在希望从指数分布密度函数λ=1中抽样:
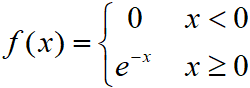
相应的累积概率密度为:
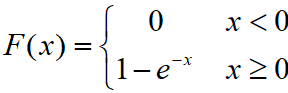
接下来,通过F的反函数将一个0到1的均匀分布的随机数转换成了符合指数分布的随机数。由于x小于0的地方概率为0,因此对于x小于0的地方不用采样。这样,累积概率密度反函数如下:
![]()
代码仿真:
import matplotlib.pyplot as plt
def sampleExp(Lambda = 2,maxCnt = 50000):
ys = []
standardXaxis = []
standardExp = []
for i in range(maxCnt):
u = np.random.random()
y = -1/Lambda*np.log(1-u) #F-1(X)
ys.append(y)
for i in range(20):
t = Lambda * np.exp(-Lambda*i)
standardXaxis.append(i)
standardExp.append(t)
plt.plot(standardXaxis,standardExp,'r')
plt.hist(ys,1000,normed=True)
plt.show()
sampleExp(1,50000)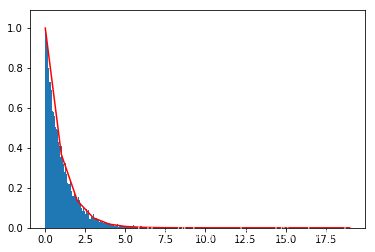
从上图中可以发现采样点与原始分布非常吻合。
接受-拒绝采样Rejection Sampling
假设已知概率密度函数P(x),想要进行采样,但是其累积概率密度函数可能很难通过积分计算得到,或者它的反函数也不容易计算。这时可以考虑拒绝采样。我们首先构造提议分布Q(x),这个函数相对容易采样。然后我们找一个常数c,将其与Q(x)相乘之后,即c*Q(x)将P(x)完全罩住。如下图所示,相当于cQ(x)给P(x)划定了上界。

在cQ(x)的范围内,按照[0, 1]均匀分布采样:
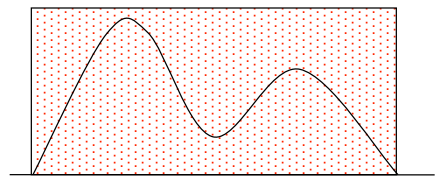
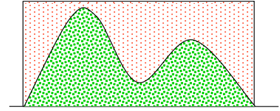
如果采样点落在函数P(x)的曲线下方,则接收这个采样,否则拒绝。
样本生成步骤:
- 从备选分布q(x)中抽样,得到样本xi
- 从均匀分布U[0,1]中抽样,得到样本u
- 如果存在
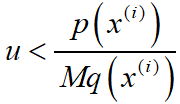 ,则接受样本xi,否则拒绝
,则接受样本xi,否则拒绝
下图是对拒绝采样很好的总结。

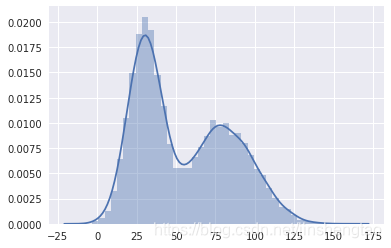
这种方法非常依赖于提议分布Q(x)的形式,如果M*Q(x)与P(x)越接近,则接受率越高,采样效率也就越高。但是往往提议分布和常数M,很难设计。对于极端复杂的P(x),如果拒绝采样设计不好,可以认为无法采样,因为始终被拒绝。
代码仿真:
import numpy as np
import scipy.stats as st
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
def p(x):
return st.norm.pdf(x, loc=30, scale=10) + st.norm.pdf(x, loc=80, scale=20)
def q(x):
return st.norm.pdf(x, loc=50, scale=30)
x = np.arange(-50, 151)
k = max(p(x) / q(x))
def rejection_sampling(iter=1000):
samples = []
for i in range(iter):
z = np.random.normal(50, 30)
u = np.random.uniform(0, k*q(z))
if u <= p(z):
samples.append(z)
return np.array(samples)
plt.plot(x, p(x))
plt.plot(x, k*q(x))
plt.show()
s = rejection_sampling(iter=30000)
sns.distplot(s)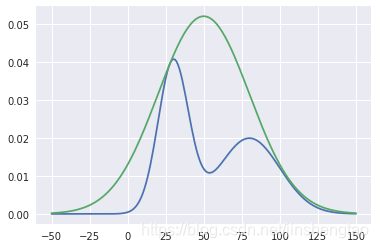
重要性采样
我们回到一开始谈论蒙特卡洛方法的背景,我们想要通过求某个函数g(x)在密度函数![]() 分布下的数学期望,达到求另一个函数f(x)的积分的目的。重要性采样并不是用于生成样本,它是用于估计函数f(x)的数学期望的方法。
分布下的数学期望,达到求另一个函数f(x)的积分的目的。重要性采样并不是用于生成样本,它是用于估计函数f(x)的数学期望的方法。
![]()
如果符合![]() 的分布难以采样,我们可以引入另一个分布
的分布难以采样,我们可以引入另一个分布![]() ,可以很方便的生成样本,使得
,可以很方便的生成样本,使得
![]()
其中,
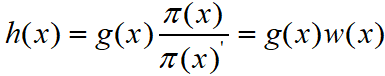
我们把w(x)成为important weight。重要性采样的一般流程:
- 从提议分布
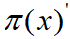 产生N个样本xi
产生N个样本xi - 构建重要性权重
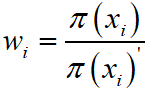
- 估计函数的数学期望
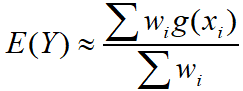
MCMC 蒙特卡洛马尔可夫链
蒙特卡洛方法的一个基本步骤是产生(伪)随机数,使之服从目标概率分布![]() 。当X是一维的情况时,很容易靠逆变换法、接受拒绝采样做到。但是当我们需要从一个高维
。当X是一维的情况时,很容易靠逆变换法、接受拒绝采样做到。但是当我们需要从一个高维![]() 的密度函数非常复杂的分布中抽样时,我们既无法求出逆函数、也很难球场密度函数的支撑集与常数M。要解决这个问题,MCMC方法是比较常用的。MCMC方法本质上是一个蒙特卡洛综合程序,它的随机样本产生与一条马氏链有关。
的密度函数非常复杂的分布中抽样时,我们既无法求出逆函数、也很难球场密度函数的支撑集与常数M。要解决这个问题,MCMC方法是比较常用的。MCMC方法本质上是一个蒙特卡洛综合程序,它的随机样本产生与一条马氏链有关。
什么是马尔可夫链
接下来介绍下有关马氏链的基本知识,假设{Xt: t≥0}是随机序列,随机序列所有可能取到的值组成的集合记为S,称为状态空间(马氏链每个节点上采样样本)。如果对于![]() 及任意状态si,sj,si0,……,sit-1都有,
及任意状态si,sj,si0,……,sit-1都有,
![]()
则称{Xt: t≥0}为马氏链。直观上看对于马氏链(马氏过程),要预测将来的唯一有用信息就是过程当前的状态,而与以前的状态无关。马氏链的性质完全由它的转移概率(转移核)来决定,它是由状态si到状态sj的一步转移概率,这里用P(i,j)表示,即,
![]()
用![]() 表示马氏链在t时刻处于状态sj的概率,用
表示马氏链在t时刻处于状态sj的概率,用![]() 表示在t步状态空间概率的行向量,初始向量用
表示在t步状态空间概率的行向量,初始向量用![]() 表示,通常
表示,通常![]() 中只有一个分量为1,其余全部是0,意味着马氏链从一个特定的状态开始,随着时间的变化,概率值扩散到整个状态空间。
中只有一个分量为1,其余全部是0,意味着马氏链从一个特定的状态开始,随着时间的变化,概率值扩散到整个状态空间。
从t时刻到t+1时刻,马氏链中状态值si的概率计算如下(注意t+1时刻的状态si之前可能是任意其他状态)
![]()
如果我们定义一个转移概率矩阵P,P(i,j)就是从状态i转移到状态j的概率。这意味着此矩阵每一行元素的和为1。这样从t时刻到t+1时刻,马氏链中状态值si的概率计算可以写成更紧凑的形式,
![]() ,
,![]()
定义n步转移概率![]() ,表示从状态i出发经过n步到达状态j的概率,即
,表示从状态i出发经过n步到达状态j的概率,即
![]()
接下来,介绍两个马氏链重要性质:
- 不可约
如果对所有的i,j都有正整数n,使得![]() ,则称此马氏链为不可约的,也就是所有状态互相之间是有联系的,从一个状态总能转移到另一个状态(虽然可能不止一步)。
,则称此马氏链为不可约的,也就是所有状态互相之间是有联系的,从一个状态总能转移到另一个状态(虽然可能不止一步)。
- 非周期
如果从状态x到状态y的步数都不是某个整数的倍数(即无公约数),就称此链是非周期的。马氏链不会在某些状态之间以固定的长度陷入循环。
平稳分布定义及目的
接下来是关于马氏链的例子。下图代表孩子心情转变的概率关系,转移概率矩阵为:

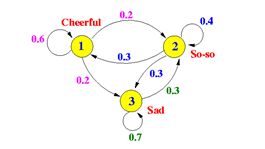
若假设初始的三个概率分别是[0.5,0.3,0.2],即t0时刻,小孩子有50%的概率是高兴的,30%的概率是一般,20%的概率是难过。将此代入转移概率,我们发现经过一个充分长的时间,期望的心情状态与初始状态无关了,比如观察100步迭代
代码仿真:
transfer_matrix = np.array([[0.6,0.2,0.2],[0.3,0.4,0.3],[0,0.3,0.7]],dtype='float32')
start_matrix = np.array([[0.5,0.3,0.2]],dtype='float32')
value1 = []
value2 = []
value3 = []
for i in range(30):
start_matrix = np.dot(start_matrix,transfer_matrix)
value1.append(start_matrix[0][0])
value2.append(start_matrix[0][1])
value3.append(start_matrix[0][2])
print(start_matrix)
x = np.arange(30)
plt.plot(x,value1,label='cheerful')
plt.plot(x,value2,label='so-so')
plt.plot(x,value3,label='sad')
plt.legend()
plt.show()
输出结果:
[[0.23076935 0.30769244 0.46153864]]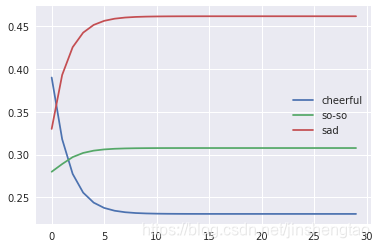
可以发现,从10轮左右开始,我们的状态概率分布就不变了,一直保持在[0.23076934,0.30769244,0.4615386]。换一个初始概率分布试一试[0.2,0.3,0.5]

最终状态的概率分布趋于同一个稳定的概率分布[0.23076934,0.30769244,0.4615386],也就是说,经过k步后,我们的马尔科夫链模型的状态转移矩阵收敛到的稳定概率值与初始状态概率值无关,马氏链达到了一个平稳分布![]() ,平稳分布的数学表达。
,平稳分布的数学表达。
如果存在一个分布,
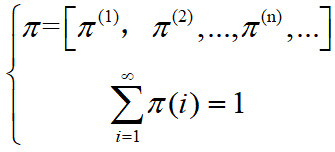
使得下式成立,xàx*代表的是条件概率P(x*|x)
![]() ,
,
也即![]()
则称它是平稳分布。下面图示表示,经过k步后的t时刻,马氏链收敛于平稳分布。X为状态,不同的状态都有对应自己的概率分布。
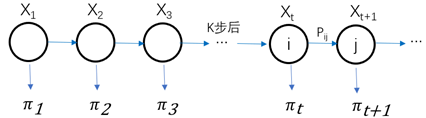
另外注意,平稳分布的条件是马氏链是不可约、非周期的。在马氏链中,不同时刻的状态有自己的概率分布。当马氏链达到平稳分布后,每个时刻对应的概率分布都相同了。
那为什么MCMC引入平稳分布呢?有何用?
我们是要对目标概率分布进行采样。我们利用马氏链收敛于平稳分布的性质,构造马氏链(包括状态随机变量及状态转移矩阵)。经过若干次迭代在t=k时刻马氏链达到平稳分布,我们认为此时的状态分布收敛于/逼近目标分布,那么整个马氏链t=0到t=k所有随机变量状态即为目标分布的采样。
如何让平稳分布逼近目标分布呢?见后续MH算法中证明。
马氏链收敛到平稳分布的条件
接下来,我们需要回答什么样的马氏链才能收敛到平稳分布呢?它的充要条件是什么?
假如一个分布![]() 满足细致平衡条件(detailed balance),则这个分布是平稳分布。反之不成立,仅仅是充分非必要条件。所谓细致平衡,对任意状态x和x*都有
满足细致平衡条件(detailed balance),则这个分布是平稳分布。反之不成立,仅仅是充分非必要条件。所谓细致平衡,对任意状态x和x*都有
![]()
简单证明:
如果细致平衡条件满足的话,则
![]()
由于状态转移矩阵的行向量和为1,即![]() ,因此满足细致平衡条件的分布,一定是平稳分布。
,因此满足细致平衡条件的分布,一定是平稳分布。
![]()
MH算法方法案例
我们知道了马氏链收敛到平稳分布的条件,那么如何构造马氏链,使之收敛到平稳分布?这个状态转移矩阵该如何构造呢?下面用不严谨的方式,推导Metroplis-Hasting算法。
对于马氏链中的两个状态x和x*,其对应的分布用p(x)和p(x*)表示(也就是前面提到的![]() ),给定提议分布Q作为状态转移矩阵,
),给定提议分布Q作为状态转移矩阵,
关于提议分布选取对称概率分布(方便MH的接受率公式中约去P(x|x*)=P(x*|x)) 。提议分布的采样方法举例,把当前状态带入U(a,b)分布采样;或把当前状态作为高斯分布的均值,再采样 。
通常下式不成立,
![]()
为了让上式成立,两边乘以一个因子,
![]()
我们这么理解上式,
![]()
我们把![]() 称为接受率,根据接受率来决定是否转移。比如马氏链在时刻t处于状态x,以概率α(x,x*)接受x*作为马氏链在下一个时刻的状态值,以概率1-α(x,x*)拒绝转移到x*,从而在下一个时刻仍处于状态x。那怎么构造这个因子呢?
称为接受率,根据接受率来决定是否转移。比如马氏链在时刻t处于状态x,以概率α(x,x*)接受x*作为马氏链在下一个时刻的状态值,以概率1-α(x,x*)拒绝转移到x*,从而在下一个时刻仍处于状态x。那怎么构造这个因子呢?
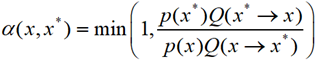
再次申明,Q表示的是条件概率。因此有
![]()
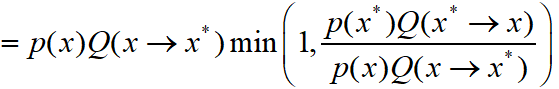
![]()
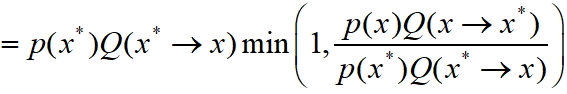
![]()
上面证明了如果引入接受率,对于任意的提议分布,都能满足细致平衡条件
![]()
下面给出MH算法的完整流程:
- 给定初始状态x
- 从提议分布Q(x(i+1)|xi)中生成样本x*,提议分布必须是对称分布(比如高斯分布,N(x*, δ))
- 计算接受率,
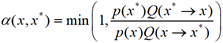
- 从均匀分布[0,1]中,生成阈值u
- 如果u<α,则接受提议,马氏链的下一时刻状态为x*,否则马氏链维持当前状态
- 返回第二部,直到满足迭代上限
由于每次迭代都会生成样本点,我们取马氏链达到平稳分布后的样本点,这样就实现了采样的目的。
下面是利用MCMC算法,对一维双峰的分布进行采样的示意图。
![]()
左图展示了马氏链在不同迭代次数中,其采样对目标分布的逼近程度。右图中间震荡的曲线,表示马氏链在不同时刻i,对应的状态x的取值(一维分布,所以x取值也是一维的)。MCMC每个状态对应的被逼近目标分布的一次采样,这里每次采样生成只一个x变量,右图展示了MCMC在i=t次迭代后,共t个采样样本。
当马尔可夫链达到平稳分布后,若把i=1 到i= t 所有节点的状态做直方图统计,那么这个直方图分布将逼近目标分布。
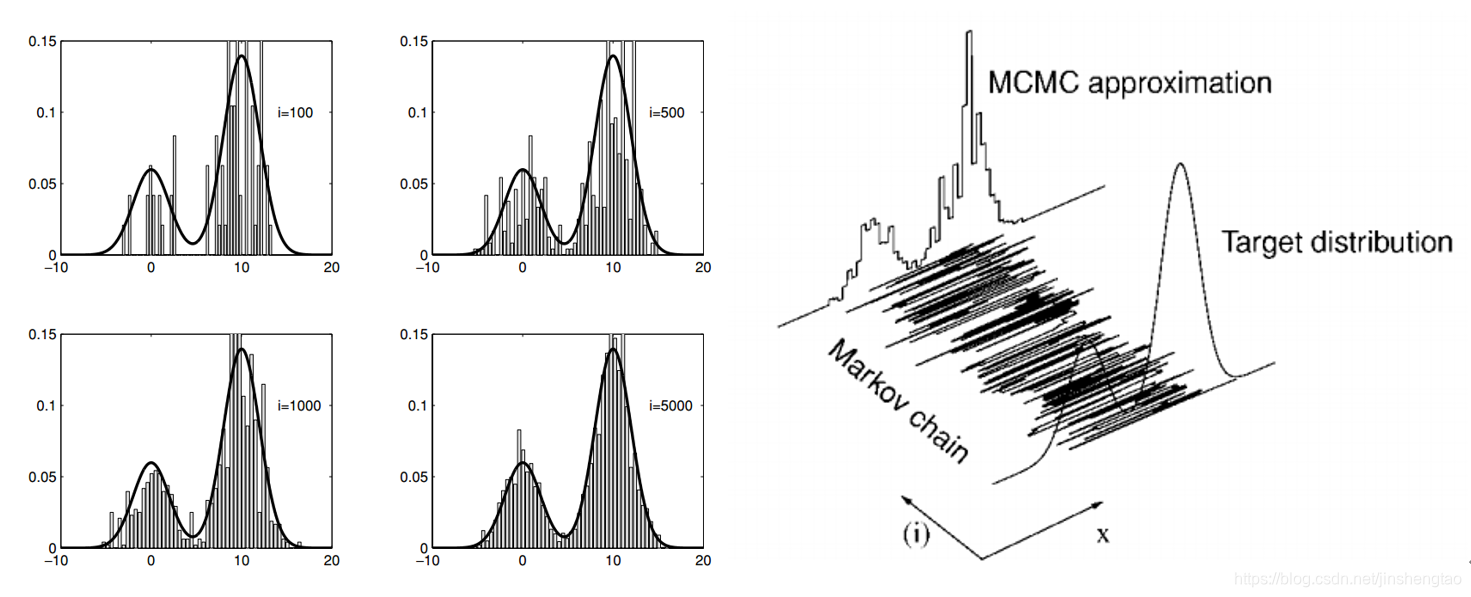
关于马尔可夫链达到平稳分布后,如何做采样满足目标分布:
a.可以是t=0时刻到t=k时刻,所有马尔可夫状态组成的采样集合 (状态选取,一定要到t=k时刻,否则采样分布残缺,无法描述目标分布)
b.也可以从t=k时刻起,从t=k+1...n,所有的马尔科夫状态组成的采样集合 (k时刻后,所有的马尔可夫状态都是满足目标分布的)
下面是一则例子,希望采样满足,逆![]() 分布
分布![]() ,这里假设n=5,a=4,应用Metroplis方法,假设我们用(0,.100)上的均匀分布做提议分布。取
,这里假设n=5,a=4,应用Metroplis方法,假设我们用(0,.100)上的均匀分布做提议分布。取![]() 作为初始值。
作为初始值。
假设得到一个候选值来自于均匀分布U(0,100),![]() ,再次强调初始样本来自提议分布。接下来计算接受率,
,再次强调初始样本来自提议分布。接下来计算接受率,
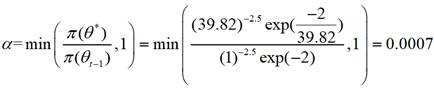
接下来在(0, 1)上均匀地抽取一个u,如果u<a,则接受θ*(把他作为下一次抽样地初值,继续以上运算),否则拒绝它。
下面的代码仿真是两则对二元分布的采样,一个是圆形,一个是高斯
import numpy as np
import scipy.stats as st
import seaborn as sns
mus = np.array([5, 5])
sigmas = np.array([[1, .9], [.9, 1]])
def circle(x, y):
return (x-1)**2 + (y-2)**2 - 3**2
def pgauss(x, y):
return st.multivariate_normal.pdf([x, y], mean=mus, cov=sigmas)
def metropolis_hastings(p, iter=1000):
x, y = 0., 0.
samples = np.zeros((iter, 2))
for i in range(iter):
x_star, y_star = np.array([x, y]) + np.random.normal(size=2)
if np.random.rand() < p(x_star, y_star) / p(x, y):
x, y = x_star, y_star
samples[i] = np.array([x, y])
return samples
if __name__ == '__main__':
samples = metropolis_hastings(circle, iter=10000)
sns.jointplot(samples[:, 0], samples[:, 1])
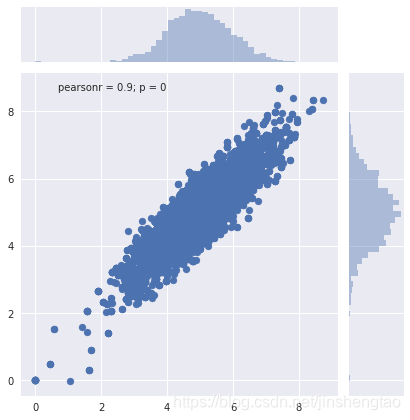
samples = metropolis_hastings(pgauss, iter=10000)
sns.jointplot(samples[:, 0], samples[:, 1])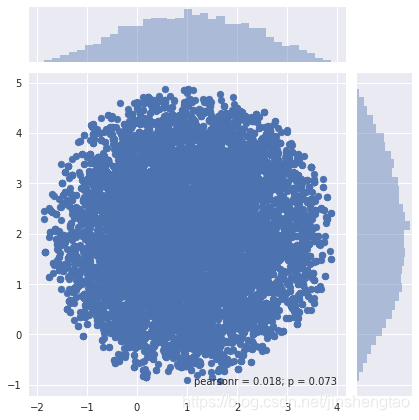
MCMC的问题
- 无理论检验马氏链何时收敛
理论只保证收敛性(证明略),但无法直到何时收敛。缺乏明确的理论证明,马氏链到达某一步后达到平稳分布,所以何时收敛并不知道。只能隔一段时间做检查、统计平均,看看是否达到平稳分布。
- 混合时间过长,或者无法收敛
我们把马氏链开始到收敛到平稳分布中间的时间叫做burn in/mixing时间,也就是说马氏链只有经过burn in时间后才会收敛到平稳分布。对于某些高维复杂分布,并且维度之间相关性非常强,不是相互独立的,无法分解,此时马氏链无法收敛,而是发散的。
- MCMC采样具有一定相关性
由于MCMC基于马尔可夫链,所以前后状态之间的样本一定具有相关性,因此从采样角度来说不能具有很好的代表性。实际运用中,只能每隔几步,取一个样本。
可逆马尔科夫链蒙特卡洛RJMCMC简介
关于可逆马尔科夫链蒙特卡洛(reversible jump markov chain monte carlo)此处仅作简单介绍,不展开。与MCMC相似,RJMCMC的目的也是为了产生一个以平稳分布的马氏链。不同之处是MCMC适用于变量个数即参数空间的维度是确定的问题中,而对于参数空间维度不定的问题,只能用RJMCMC来解决。
RJMCMC可以在不同参数空间中跳转以产生样本,一个可以应用RJMCMC的例子是,在一张图片中,有k个物体,每个物体需要n个参数θ来描述。由于k是不确定的,所以参数空间的维度不确定,那么就愮RJMCMC来进行推断确定k的大小。
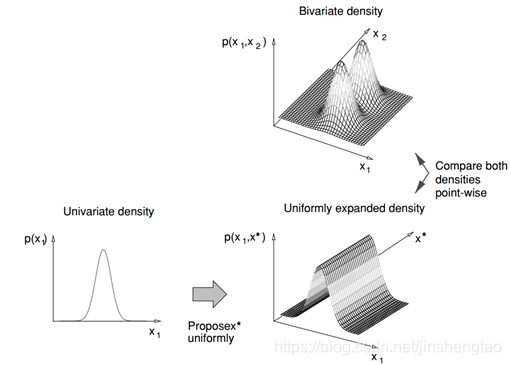
为了实现RJMCMC,需要有birth,death,update三种跳跃(也有人说是merge, split, birth, death四种)。Birth实现了低维空间到高维空间的跳转,death实现了从高维空间到低维空间的跳转,而update实现了同一参数空间中的状态改变。对于目标跟踪的例子,birth对应图片中物体个数的增加,death对应图片中物体个数的减少,update对应物体参数的更新。下图就是一个birth的实例图,为了适配二维分布,提议分布从一维增加到二维。
算法步骤如下:

注意,k是状态空间的维度,u表示状态空间的采样,不同跳转方式有自己的概率。

















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









