







最近打算做全景图拼接,尝试过hugin和opencv stitch,一直没有很满意的效果。打算深入研究,恰好,在github看到清华一小哥的项目,故逐步分析他的代码。
sift特征是全景拼接的第一步,相当基础,但sift特征提取与匹配从0开始实现起来又挺折腾的,故花点时间整理下。
清华小哥的博客:http://ppwwyyxx.com/2013/SIFT-and-Image-Stiching/
我的github连接:https://github.com/haopo2005/panorama.git
在ubuntu平台下跑,eigen安装后,记得添加makefile中eigen头文件所在目录,其他没啥了。
一、特征提取与sift特征简介
1. 整体特征与局部特征
在做目标识别与分类时,传统的方法大都将目标作为一个整体,从大量包含目标的图片集中学习并提取整体特征,如面积、周长、不变矩和傅立叶描绘子等,并进行统计分类。这种识别方法有很大缺陷:对结构复杂的图像,识别效果受到图像分割精度的制约,或者需要大量的时间学习大量的数据,又比如目标的形状发生较大变化时(目标遮挡),目标的整体特征会突然变化,这些对于目标识别不利。
而人类的视觉系统可以将物体分解为多个许多有意义的小块,并通过这些局部信息进行目标的辨识。利用局部特征对图像进行描述,在图像内容复杂、噪声干扰大、存在局部遮挡、目标姿态发生较大变化等情况下,利用局部信息进行目标识别是非常有效的。
2. 局部特征区域检测方法分类
a. 密集选取方法:
研究者认为,在模式识别的低层处理中,所有图像区域都有一定的作用,丢失任何细节都可能对最终效果产生很大的影响。常见做法:
(1) 将图像密集地分为互不重叠的特征窗口,每个特征窗口都当作一个局部特征区域
(2) 以整幅图像的每一个像素点为中心,选取周围的区域作为局部特征区域
(3) 在检测窗口的每个像素位置、不同尺度下提取大量的特征区域,供进一步使用
密集选取方法在滑动窗口模型中应用很多,其优点是基本没有丢失图像的细节,可以得到非常丰富局部特征。但是其中很大一部分特征区域信息量过小,对后期的识别没有作用甚至起到干扰作用,加重了下一步特征优化工作。
b. 稀疏选取方法:
通过特征检测,选取具有显著特点的图像区域作为局部特征。检测算子一般可以分为基于形状的和基于外观的。
(1) 基于形状的检测算子是根据图像的边界、直线、弧线等来确定特定区域的位置。主要用于外形区分度明显的目标识别,比如canny特征
(2) 基于外观的检测算子是在图像的灰度模式下,搜索具有某种稳定性和不变性的特征点或关键区域。比如Hessian矩阵、Harris角点、高斯差分DOG、SIFT特征
稀疏选取法检测的特征区域数量一般在200~3000,其主要优点是简洁、紧致,图像的关键点远少于图像的像素,使得后面的识别过程能大大加速。但很多特征区域检测算法往往和图像的特性有关,应用到通用的目标识别时,可能会有一定的局限。
c. 其他方法
有人在研究向量空间模型的取样策略时发现,当训练集的样本数足够多时,随机取样法能达到和某些稀疏取样相近甚至更好的结果。比如使用显著性映射在分类过程中动态选取图像块的方法。
3. sift特征简介
SIFT算子(Scale-Invariant FeatureTransform),是一种图像的局部描述子,具有尺度、旋转、平移的不变性,而且对光照变化、仿射变换和3维投影变换具有一定的鲁棒性。另外,它还具有以下有点:
a.很好的独特性,适于在海量特征数据库中进行快速、准确的匹配;
b.算法产生的特征点在图像中的密度很大,速度可以达到实时要求;
c.由于 SIFT 特征描述子是向量的形式,它可以与其他形式的特征向量进行联合。
Sift在一定程度上可以解决:
n 目标的旋转、缩放、平移(RST)
n 图像仿射/投影变换(视点viewpoint)
n 光照影响(illumination)
n 目标遮挡(occlusion)
n 杂物场景(clutter)
n 噪声
二、sift特征提取步骤
SIFT算法的实质可以归为在不同尺度空间上查找特征点(关键点)的问题。SIFT算法实现物体识别主要有三大工序:
1. 构造DOG尺度空间
2. 关键点搜索与精确定位
3. 方向赋值
4. 关键点描述
5. 特征匹配
三、DOG尺度空间构造
在讲解DOG尺度空间构造之前,我们先弄明白以下几个问题:
1. 什么是尺度空间
从认知学的角度讲,在一幅图像中,即使对一个事物没有概念,或者并不熟悉它,人仍然能够感知此物体的结构。对于计算机而言,想要得知图像中哪些是有意义的,必须先要明确这样一个问题:在一幅图像中,只有在一定的尺度范围内,一个物体才有意义。举一个例子,树枝这个概念,只有在几厘米到几米的距离去观察它,才能感知到它的确是树枝;如果在微米级或者千米级去观察,就不能感知到树枝这个概念了,这样的话可以感知到的是细胞或者是森林的概念。
因而,尺度空间中各尺度图像的模糊程度逐渐变大,能够模拟人在距离目标由近到远时目标在视网膜上的形成过程。并且尺度越大,图像越模糊。
注意,高斯核是唯一可以产生多尺度空间的核函数。
2. 哪些点是SIFT中要查找的关键点(特征点)
所谓关键点,就是在不同尺度空间的图像下检测出的具有方向信息的局部极值点。这些点不会因光照条件的改变而消失,比如角点、边缘点、暗区域的亮点以及亮区域的暗点,既然两幅图像中有相同的景物,那么使用某种方法分别提取各自的稳定点,这些点之间会有相互对应的匹配点。
3. 多尺度和多分辨率
尺度空间表达和金字塔多分辨率表达之间最大的不同是:
l 尺度空间表达是由不同高斯核平滑卷积得到,在所有尺度上有相同的分辨率;
l 而金字塔多分辨率表达每层分辨率减少固定比率。
所以,金字塔多分辨率生成较快,且占用存储空间少;而多尺度表达随着尺度参数的增加冗余信息也变多。多尺度表达的优点在于图像的局部特征可以用简单的形式在不同尺度上描述;而金字塔表达没有理论基础,难以分析图像局部特征。

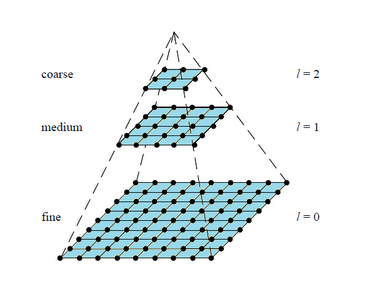
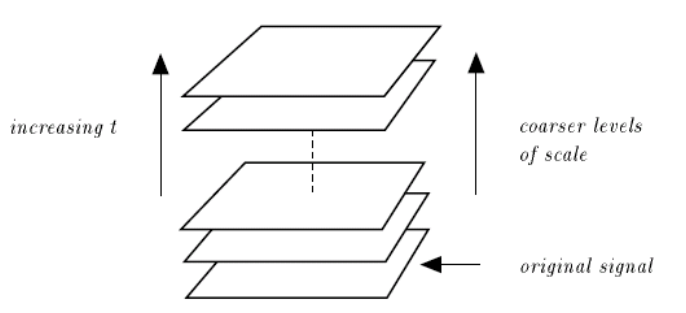
通过上面的图可以形象的感觉到多尺度表示和多分辨率表示的区别。多尺度在所有尺度上像素数是相同的,细节通过平滑逐步丢失。多分辨率(金字塔)是对图像进行降采样(通常是水平,竖直方向1/2),从而得到一系列尺寸缩小的图像(上图是对缩小图像插值放大的结果)
DOG高斯差分金字塔的构建分为两部:高斯金字塔构建和差分图像计算。
(1)高斯金子塔构建
多次进行如下步骤:
a. 对图像做高斯滤波平滑
b. 对图像做将采样
这样,一幅图像可以产生O组(octave)图像,一组图像包括S层(interval)图像。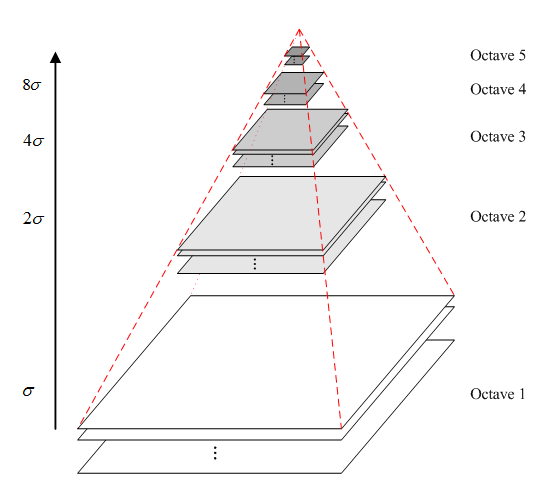
参数设置啥的,可以看github上的config.cfg文件。具体实现:
a.给定一张图片,按照组数Oi,定义每组图片的长和宽,δ为缩放因子
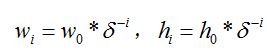
b.将原始图像用双线性插值的方式缩小到指定大小
c.将缩放后的图像转换为灰度图
d.然后根据组内层数Si,指定高斯模糊核函数
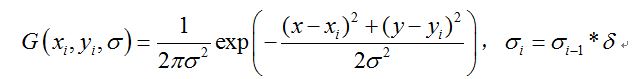
为了加速计算,采用一维高斯核函数分别对图像的行和列进行卷积,达到高斯模糊效果,具体实现见代码。
缩放的代码:
ScaleSpace::ScaleSpace(const Mat32f& mat, int num_octave, int num_scale):
noctave(num_octave), nscale(num_scale),
origw(mat.width()), origh(mat.height())
{
// #pragma omp parallel for schedule(dynamic)
REP(i, noctave) {
if (!i)
pyramids.emplace_back(mat, nscale);//拷入某组图像O,及该组图像的层数S
else {
float factor = pow(SCALE_FACTOR, -i);
int neww = ceil(origw * factor),
newh = ceil(origh * factor);
Mat32f resized(newh, neww, 3);
resize(mat, resized); //双线性插值,两组图像之间
pyramids.emplace_back(resized, nscale);
}
}
}原图:

第一组:

第二组:

第三组:

一维卷积高斯模糊代码:
/*该构造函数在ScaleSpace函数内,由emplace_back阶段发起调用*/
GaussianPyramid::GaussianPyramid(const Mat32f& m, int num_scale):
nscale(num_scale),
data(num_scale), mag(num_scale), ort(num_scale), /*为每个vector指定成员数量?*/
w(m.width()), h(m.height())
{
TotalTimer tm("build pyramid");
if (m.channels() == 3)
data[0] = rgb2grey(m);
else
data[0] = m.clone();
Filter blurer(nscale, GAUSS_SIGMA, SCALE_FACTOR); //组内层间进行不同种类的高斯模糊,不再做图像缩放,生成s个高斯核函数
for (int i = 1; i < nscale; i ++) {
data[i] = blurer.GaussianBlur(data[0], i); // sigma needs a better one
}
}
GaussCache::GaussCache(float sigma) {
// TODO decide window size ?
/*
*const int kw = round(GAUSS_WINDOW_FACTOR * sigma) + 1;
*/
kw = ceil(0.3 * (sigma / 2 - 1) + 0.8) * GAUSS_WINDOW_FACTOR; //ceil向上取整,高斯核大小(6*sigma +1)*(6*sigma +1),核中央为1,往外依次减小
//cout << kw << " " << sigma << endl;
if (kw % 2 == 0) kw ++;
kernel_buf = create_auto_buf<float>(kw);
const int center = kw / 2;
kernel = kernel_buf.get() + center;
kernel[0] = 1;
float exp_coeff = -1.0 / (sigma * sigma * 2),
wsum = 1;
for (int i = 1; i <= center; i ++) //生成一维的高斯核函数,wsum为了归一化
wsum += (kernel[i] = exp(i * i * exp_coeff)) * 2;
float fac = 1.0 / wsum;
kernel[0] = fac;
for (int i = 1; i <= center; i ++)
kernel[-i] = (kernel[i] *= fac);
}
Filter::Filter(int nscale,
float gauss_sigma,
float scale_factor) {
REP(k, nscale - 1) { //每组有s种高斯核函数
gcache.emplace_back(gauss_sigma);
gauss_sigma *= scale_factor;
}
}
// TODO faster convolution,先调用filter.hh中的Mat32f GaussianBlur(const Mat32f& img, int n)
Mat32f Filter::GaussianBlur(
const Mat32f& img, const GaussCache& gauss) const {
m_assert(img.channels() == 1);
TotalTimer tm("gaussianblur");
const int w = img.width(), h = img.height();
Mat32f ret(h, w, 1);
const int kw = gauss.kw;
const int center = kw / 2;
float * kernel = gauss.kernel;
auto cur_line_mem = create_auto_buf<float>(
center * 2 + max(w, h), true);
float *cur_line = cur_line_mem.get() + center;
// apply to columns
REP(j, w){
const float* src = img.ptr(0, j); //某列第一个元素地址
// copy a column of src
REP(i, h) {
cur_line[i] = *src; //每列的一个元素对应高斯核的中央位置
src += w;
}
// pad the border with border value,构造边界外的图像值,上边界外的全用第一个列元素表示,下边界外的全用最后一个列元素表示
float v0 = cur_line[0];
for (int i = 1; i <= center; i ++)
cur_line[-i] = v0;
v0 = cur_line[h - 1];
for (int i = 0; i < center; i ++)
cur_line[h + i] = v0;
float *dest = ret.ptr(0, j);
REP(i, h) {
float tmp = 0;
for (int k = -center; k <= center; k ++) //对列方向做图像和高斯核的卷积
tmp += kernel[k] * cur_line[i + k];
*dest = tmp;
dest += w;
}
}
// apply to rows,原理同上,只是输入图像从dest继续,行方向做卷积
REP(i, h) {
float *dest = ret.ptr(i);
memcpy(cur_line, dest, sizeof(cur_line[0]) * w);
{ // pad the border
float v0 = cur_line[0];
for (int j = 1; j <= center; j ++)
cur_line[-j] = v0;
v0 = cur_line[w - 1];
for (int j = 0; j < center; j ++)
cur_line[center + j] = v0;
}
REP(j, w) {
float tmp = 0;
for (int k = -center; k <= center; k ++)
tmp += kernel[k] * cur_line[j + k];
*(dest ++) = tmp;
}
}
return ret;
}
刚才有4组分辨率,现在每个分辨率下有5种尺度,供20张图,为了示意,我只贴几组了(按尺度层数递增的顺序)
第二组:





第五组:





(2)高斯差分图像计算
计算同一组内,相邻两层之间平滑图像之差,并把查的绝对值作为差分图像。
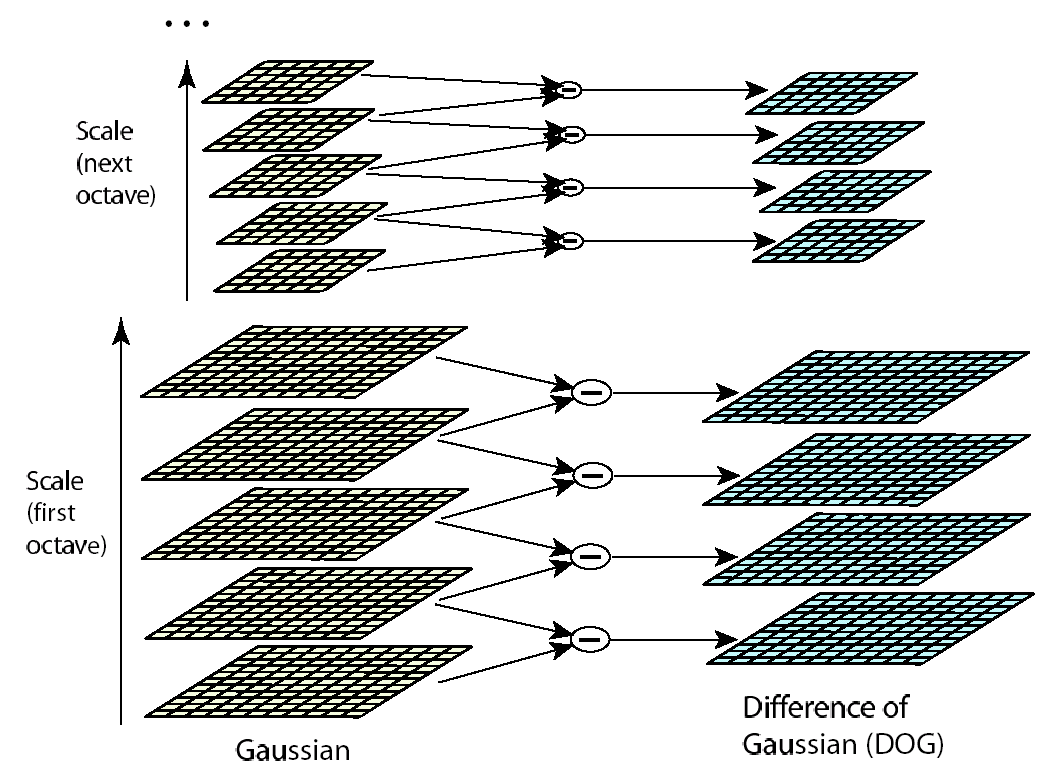
/*计算同一组内相邻两个尺度(高斯模糊)图片的差*/
Mat32f DOGSpace::diff(const Mat32f& img1, const Mat32f& img2) const {
int w = img1.width(), h = img1.height();
m_assert(w == img2.width() && h == img2.height());
Mat32f ret(h, w, 1);
REP(i, h) {
// speed up
const float *p1 = img1.ptr(i),
*p2 = img2.ptr(i);
float* p = ret.ptr(i);
REP(j, w)
p[j] = fabs(p1[j] - p2[j]);
}
return ret;
}
DOGSpace::DOGSpace(ScaleSpace& ss):
noctave(ss.noctave), nscale(ss.nscale),
origw(ss.origw), origh(ss.origh),
dogs(noctave)
{
#pragma omp parallel for schedule(dynamic)
REP(i, noctave) {
auto& o = ss.pyramids[i];
int ns = o.get_len(); //获取某一组图像内层数S
REP(j, ns - 1)
dogs[i].emplace_back(diff(o.get(j), o.get(j+1)));
}
}结果同样会很多,我只贴部分结果:
第一组:





第四组:





我们可以通过高斯差分图像看出图像上的像素值变化情况。(如果没有变化,也就没有特征。特征必须是变化尽可能多的点。)DOG图像描绘的是目标的轮廓。

















 2102
2102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









