









总结自视频(吴恩达大模型入门课):14_03_optional-video-efficient-multi-gpu-compute-strategies_哔哩哔哩_bilibili
1. 分布式数据并行(DDP,distributed data parallel)
适合模型不大,要求单个模型也可以加载并训练。原理如下图所示。
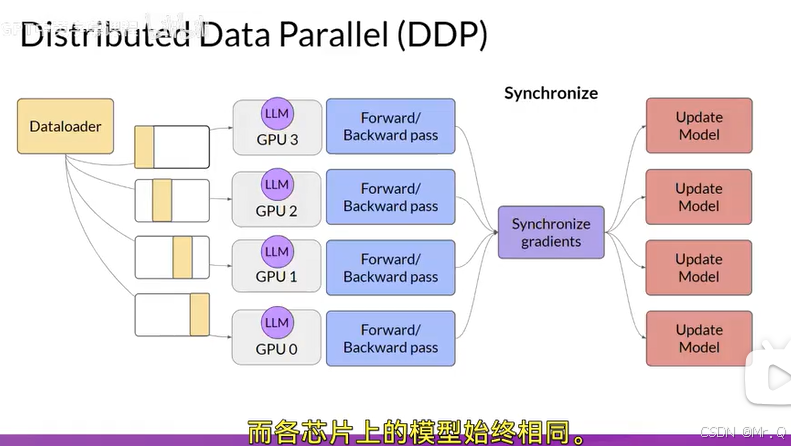
其核心思想是:
-
模型复制:将同一模型复制到每个GPU或计算节点。
-
数据分片:将训练数据划分为多个子集,每个GPU处理不同的数据子集。
-
梯度同步:所有GPU独立计算梯度后,通过通信同步梯度并更新模型参数,确保模型一致性。
1.1 工作原理
-
初始化:
-
每个GPU(或节点)加载相同的模型副本。
-
数据加载器通过分布式采样器(如
DistributedSampler)为每个GPU分配唯一的数据子集。
-
-
前向传播:
-
每个GPU使用本地数据计算损失和梯度。
-
-
梯度同步:
-
所有GPU的梯度通过高效的通信库(如NCCL)进行全局平均(AllReduce操作)。
-
-
参数更新:
-
每个GPU使用同步后的梯度独立更新模型参数(因初始参数相同,梯度也相同,更新后仍保持一致)。
-
1.2 代码实现(pytorch为例)
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def train(rank, world_size):
# 初始化进程组
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# 创建模型并移至当前GPU
model = Model().to(rank)
ddp_model = DDP(model, device_ids=[rank])
# 配置分布式数据采样器
dataset = MyDataset()
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader = DataLoader(dataset, batch_size=64, sampler=sampler)
# 训练循环
for inputs, labels in dataloader:
outputs = ddp_model(inputs.to(rank))
loss = loss_fn(outputs, labels.to(rank))
loss.backward()
optimizer.step()
optimizer.zero_grad()
if __name__ == "__main__":
world_size = 4 # GPU数量
mp.spawn(train, args=(world_size,), nprocs=world_size)2. 与其他并行策略对比
| 策略 | 数据并行(DDP) | 模型并行(MP) | 管道并行(PP) |
|---|---|---|---|
| 核心思想 | 复制模型,拆分数据 | 拆分模型,数据完整传递 | 模型分阶段,数据流水线处理 |
| 适用场景 | 模型可单卡容纳,数据量大 | 模型参数过大无法单卡存放 | 超大规模模型(如千亿参数) |
| 通信开销 | 梯度同步(AllReduce) | 层间激活值传递 | 阶段间激活和梯度传递 |
| 实现复杂度 | 低(框架原生支持) | 高(需手动拆分模型) | 中高(需设计流水线) |



















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











