






文章目录
DBSCAN算法
DBSCAN算法是一个基于密度、对噪声鲁棒的空间聚类算法:DB-SCAN可以找到样本点的全部密集区域,把这些密集区域当做一个一个的聚类簇
DB-SCAN算法的特点:
- 基于密度,对远离密度核心的噪声点鲁棒
- 无需知道聚类簇的数量
- 可以发现任意形状的聚类簇
基本概念
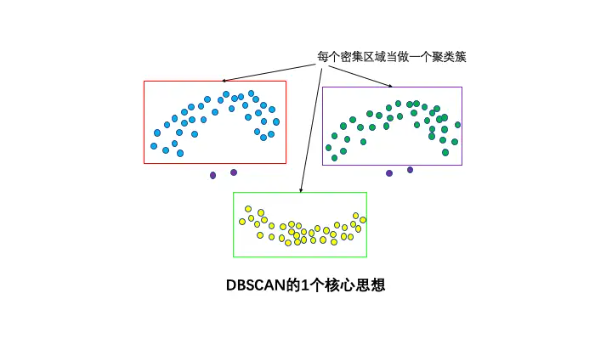
1个核心思想:基于密度
DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇
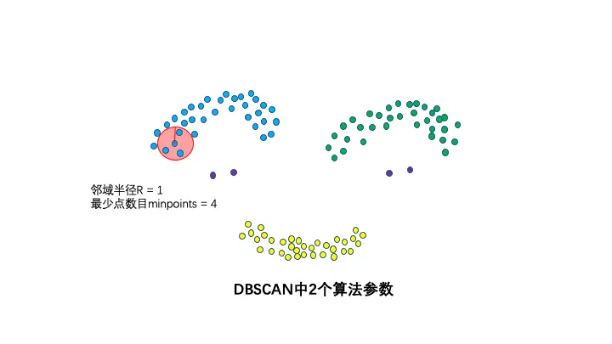
2个算法参数:邻域半径R和最少点数目minpoints
这两个算法参数在刻画什么叫密集:当邻域半径R内的点的个数大于最少点数目minpoints时,就是密集
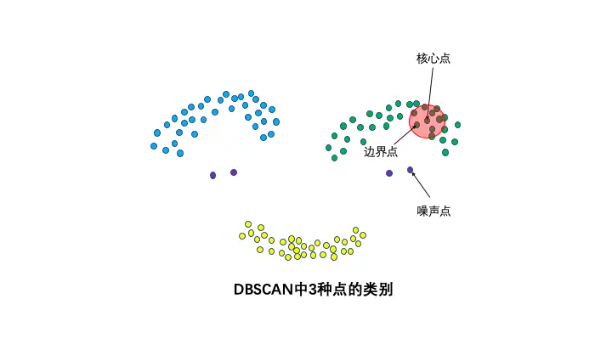
3种点的类别:核心点,边界点和噪声点
- 核心点:如果一个点P在半径\varepsilon内拥有超过minpoints个的点(包括点P自身),则点P被认为是一个核心点
- 边界点:如果一个点不是核心点,但在某个核心点的\varepsilon范围内,并且至少是minpoints-1个核心点的密度直达点,则这个点被认为是边界点
- 噪声点:如果一个点既不是核心点,也不是任何核心点的密度可达点,则被认为是噪声点
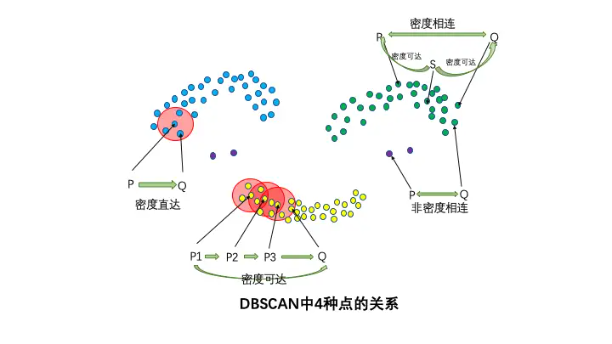
4种点的关系:密度直达,密度可达,密度相连,非密度相连
- 密度直达:如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达(Q不一定是核心点,在Q的\varepsilon邻域内没有足够的点,不能将P包含在其密度直达性簇内)
- 密度可达:如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达,密度可达也不具有对称性
- 密度相连:如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连,密度相连的两个点属于同一个聚类簇
- 非密度相连:如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点
DBSCAN算法步骤
聚类簇(Cluster):由一个核心点P和所有从P密度可达的点组成
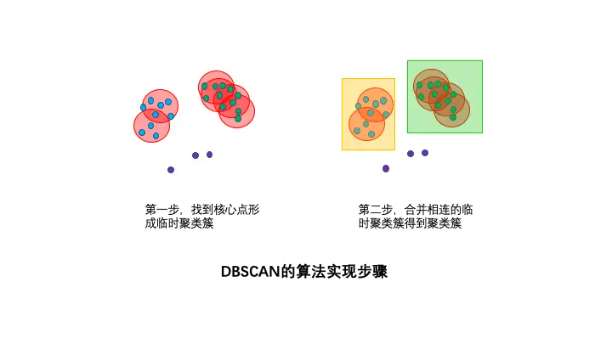
- 寻找核心点形成临时聚类簇
扫描全部样本点,如果某个样本点R半径范围内点数目>=minpoints,则将其纳入核心点列表,并将其密度直达的点形成对应的临时聚类簇 - 合并临时聚类簇得到聚类簇
重复此操作,直到当前临时聚类簇中的每一个点要么不在核心点列表,要么其密度直达的点都已经在该临时聚类簇,该临时聚类簇升级成为聚类簇
DBSCAN代码
# --*-- coding:utf-8 --*--
# @Author : 一只楚楚猫
# @File : 05DBSCAN.py
# @Software : PyCharm
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.cluster import dbscan
import matplotlib.pyplot as plt
X, _ = datasets.make_moons(n_samples=500, noise=0.1, random_state=1)
df = pd.DataFrame(X, columns=['feature1', 'feature2'])
df.plot.scatter('feature1', 'feature2', s=100, alpha=0.6, title='dataset by make_moon')
plt.show()
"""
eps为邻域半径,min_samples为最少点数目
cluster_ids中-1表示对应的点为噪声点
"""
core_samples, cluster_ids = dbscan(X, eps=0.2, min_samples=20)
"""
np.c_ 是 NumPy 库中的一个函数,用于沿着列(列优先)堆叠数组
# 假设有两个一维数组 a 和 b
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
c = np.c_[a, b]
[[1 4]
[2 5]
[3 6]]
"""
df = pd.DataFrame(np.c_[X, cluster_ids], columns=['feature1', 'feature2', 'cluster_id'])
"""
astype('i2') 是一个用于转换数据类型的方法,将 'cluster_id' 列的数据类型转换为 16 位整数(int16 或 i2)
"""
df['cluster_id'] = df['cluster_id'].astype('i2')
"""
c = list(df['cluster_id']): c 参数指定了每个点的颜色,这里使用 list() 函数将 DataFrame 中 'cluster_id' 列的值转换成列表,列表中的每个元素对应一个点的颜色
cmap = 'rainbow': cmap 参数设置颜色映射表,用于根据 'cluster_id' 列的值为散点图上的点分配颜色。'rainbow' 是一个预设的颜色映射,它将按照彩虹的颜色顺序为不同的聚类分配颜色
colorbar = False: 这个参数决定是否在散点图旁边显示颜色条,颜色条用于显示颜色和 'cluster_id' 值之间的映射关系
"""
df.plot.scatter('feature1', 'feature2', s=100, c=list(df['cluster_id']), cmap='rainbow', colorbar=False, alpha=0.6,
title='DBSCAN cluster result')
plt.show()
参考文献
1、图解机器学习 | 聚类算法详解:https://www.showmeai.tech/article-detail/197
2、20分钟学会DBSCAN聚类算法:https://cloud.tencent.com/developer/article/1664886
3、ChatGPT















 840
840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









