






0、前言
本文将介绍一种轻量级万物分割SAM模型——MobileSAM的安装和实测情况。SAM是meta公司的一种图像分割大模型,它可以将图像中自带分割物体,他们号称“SAM已经学会了物体的概念”,诸如此类视觉大模型是目前图像分割领域的研究热点之一。然而,SAM模型存在着模型过于庞大对平民不太友好,只能运行在不差钱的人和公司的服务器上,这对于实际应用来说是不可接受的。然而,MobileSAM出现了,诸如此类的量化模型的出现给平民带来了福音,使得模型在保证准确率的同时,运行速度更快,更加适合实际应用。本文将体验MobileSAM模型,并进行实际运行测试,看看实际运行效果。

1、准备工作
安装
python环境说明
安装也比较简单,直接按照github主页要求按照就可以。我这里python版本是conda2021的 3.9版本

我计算机的配置是:

安装说明
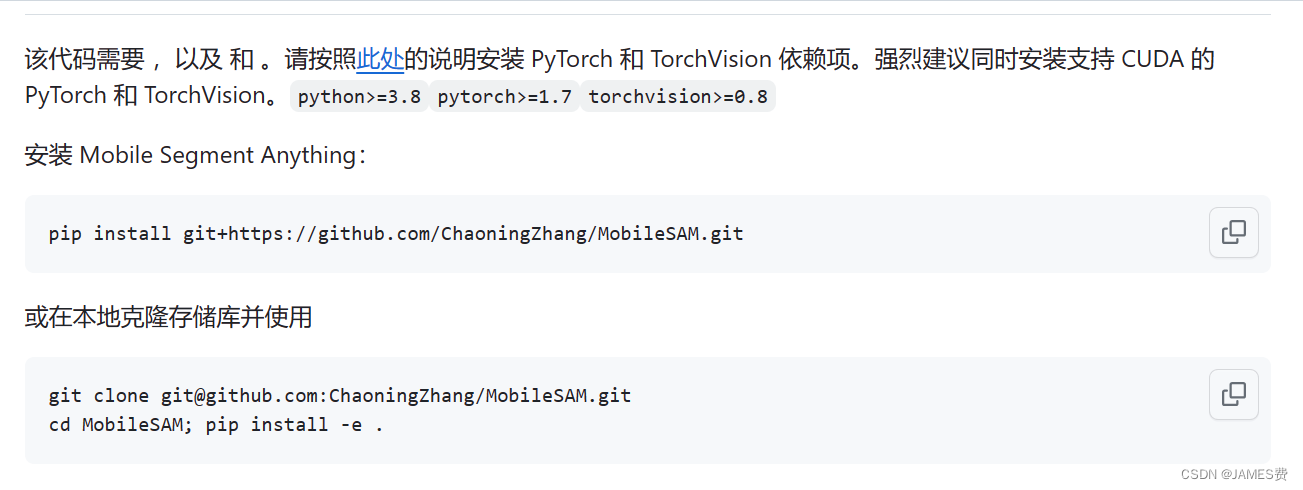
根据如上版本要求安装好依赖pytorch,torchvision两个依赖后,可以直接安装sam:
pip install git+https://github.com/ChaoningZhang/MobileSAM.git
运行测试app
安装依赖
运行官方自带的app,需要安装最新版本的 gradio:
pip install gradio
这里要注意,如果是conda的环境,安装完后可能会出现打不开spyder的情况,是由于gradio安装时,可能是对pyqt做了更换,可以通过重新安装spyder解决(其它环境根据实际情况而定):
pip install Spyder
修改代码
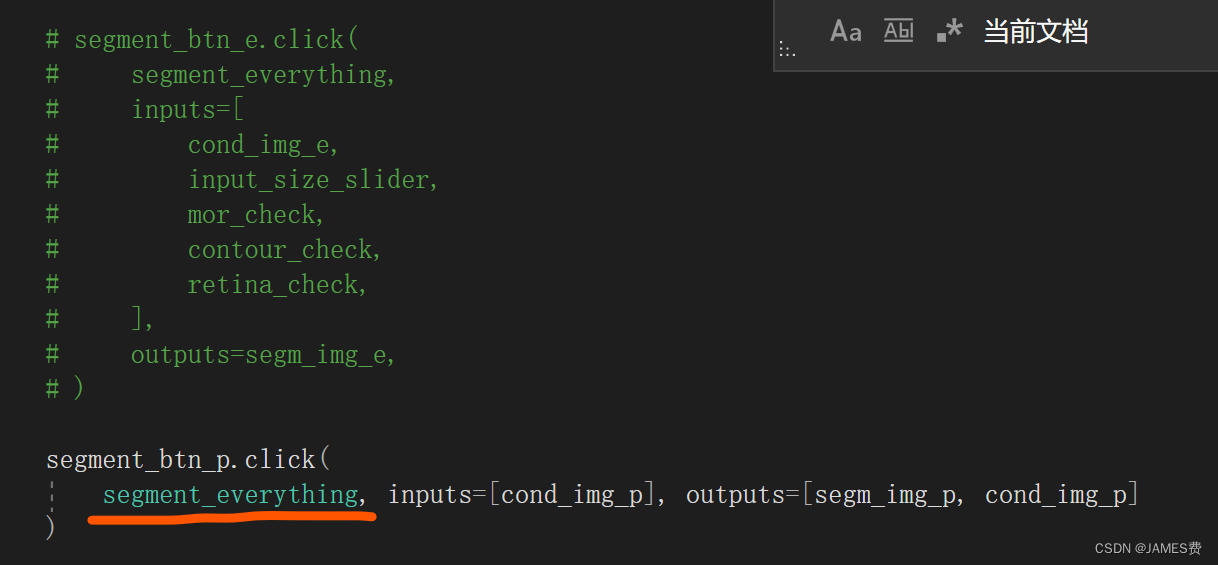
打开官方自带的app.py,可以发现,默认把自动分割给注释掉了,

不去掉的话,运行只有手动分割:
如果要自动分割,简单做法直接替换一下函数就行:
segment_with_points替换为segment_everything
2、实际测试效果
运行app后,点击浏览器进入url:http://127.0.0.1:7860/:
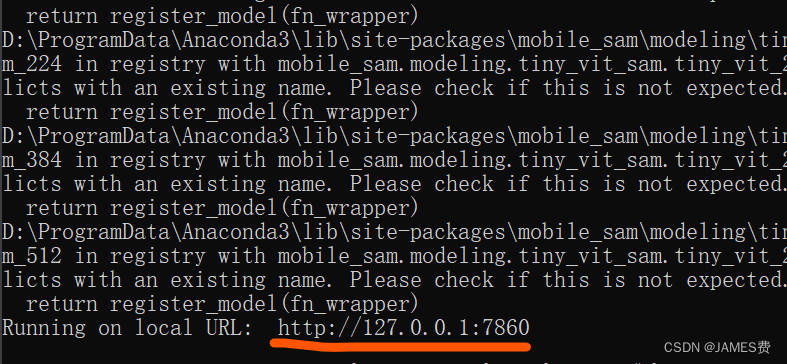
默认加载自带demo图片:
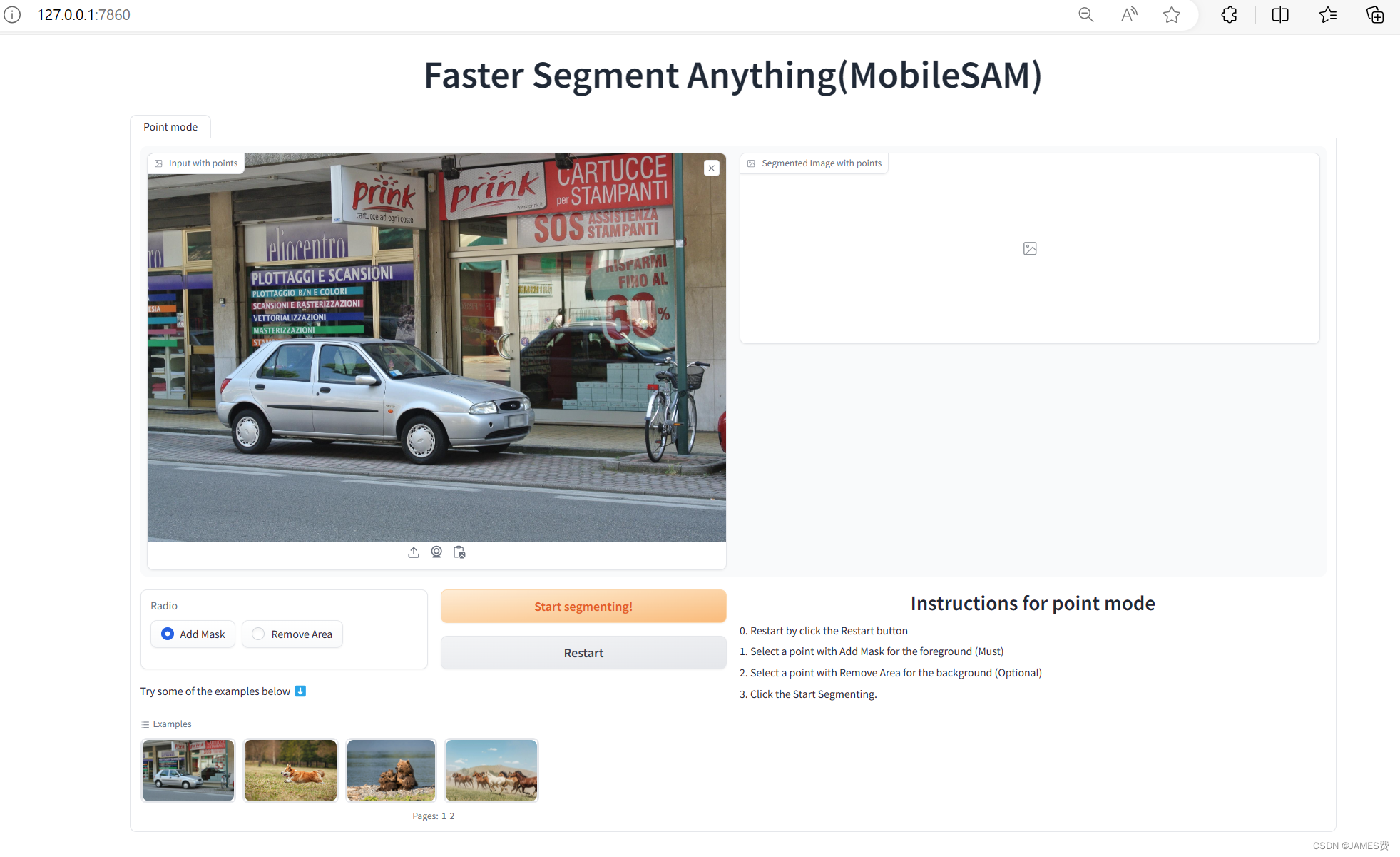
自带图片测试
点击start segmenting按钮就开始自动分割了:

风格结果如下:

由上图可知分割的整体效果还是可以的,但是比较耗时,已经超过了10秒。
其它图片测试1

图片信息为
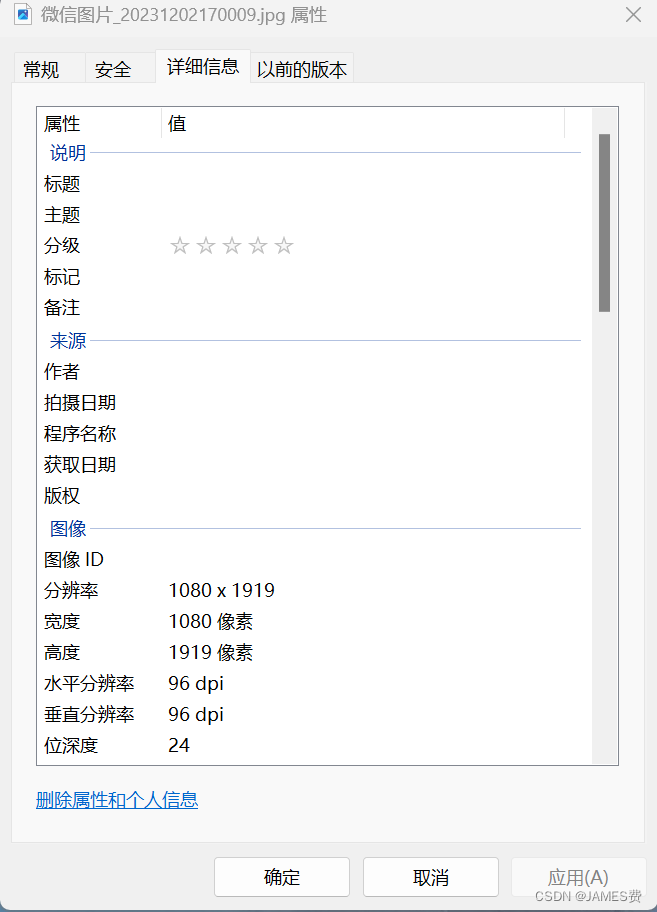
耗时为:

其它图片测试2

图片信息:

消耗时间:
结果:

总结
从运行几个demo可以看出,总体上,mobilesam的分割效果还是不错的,可以对高纹理特征的物体进行有效分割。但是离实际的产品应用可能还需要进一步优化,包括识别的速度、包括准确度、和稳定性。
总之,mobilesam的出现,以及量化大模型技术的出现,给大模型端到端和平明化应用带来了希望,这点还是要感谢那些具有开源精神和具有高超编码技术的计算机大拿们,应用一位网友的话做得“功德无量,让大模型进入寻常百姓家”。我们相信,随着更多类似量化技术的贡献,低功耗、实时运行大模型的时代会快速到来的。



















 7223
7223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











