







 本文探讨了一种无监督学习方法,通过左右视图一致性检查来估计深度。利用图像重建误差和左右一致性损失函数优化深度预测,网络结构采用encoder-decoder并结合数据增强进行训练。通过对比学习和后处理技术,提高了深度估计的准确性。
本文探讨了一种无监督学习方法,通过左右视图一致性检查来估计深度。利用图像重建误差和左右一致性损失函数优化深度预测,网络结构采用encoder-decoder并结合数据增强进行训练。通过对比学习和后处理技术,提高了深度估计的准确性。
ECCV2016_Unsupervised Monocular Depth Estimation with Left-Right Consistency
本文采用无监督学习(没有ground truth)的方法来估计深度,基本思路是匹配好左右视图的像素,得到disparity map。根据得到的视差disparity,由d = bf/disparity,算出depth map。本文能实现在35ms内恢复一张图512×256的图只需要25ms(GPU)。
本文提出的架构受Mayer的DispNet(Mayer的DispNet和Dosovitskiy的FlowNet相似)启发(code中也有resnet和vgg版本实现);最后通过左右匹配的一致性检查和当前利用深度学习的双目匹配很相似。
1.介绍
利用图像重建误差(image reconstruction loss)来最小化光度误差(类似于SLAM中的直接法)虽可以得到很好地图像重建结果(disparity),但得到深度预测结果非常差。
为了优化这个结果,作者采用Left-Right Consitency来优化。也就是以左视图为输入,以右视图为training中的监督真值,生成右侧对应的视图;然后又以左视图为监督真值,根据右视图生成左视图。最小化这两个过程的联合loss则可以一个很好的左右视图对应关系。
最终网络得到一个四个scale大小的输出(disp1-disp4)。
Left-Right Consistency Check
作者先根据左视图L1预测得到右视图R1,然后根据生成的右视图再预测的到左视图L2,此时要求L1与L2一致,即所谓(从)左(到有边,从)右(到左边)一致性。
看来,需要从双目匹配中寻找灵感
2.价值函数
价值函数考量了三个部分:
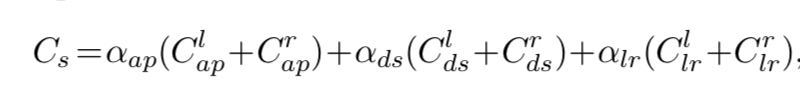
分别是:
- 左右视图的灰度匹配部分
- 视差平滑部分(让disparity的分布更加平滑)
- 左右视图的一致性部分(促使左视图中的disparity分布和右视图的disparity图严格相同)
左右视图的视差匹配程度:
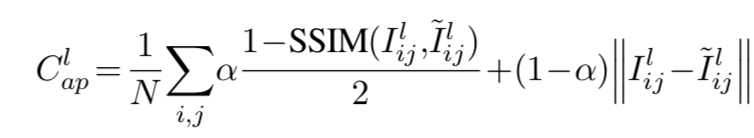
本文采用和Loss Functions for Neural Networks for Image Processing一文相同的形式,将SSIM和L1结合起来作为代价函数,其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9917
9917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









