









人像分割任务作为许多任务的一个中间阶段,对实时性要求极高,并且当前缺乏大规模的人像分割数据集,为此论文提出SiNet模型和用于进行数据扩充的简单方法。SINet中的空间压缩模块使用多尺度感受也来获取图像中不同尺寸的一致性信息,信息遮挡编码器则在不破坏全局一致性的前提下回复局部空间信息。该模型能够实现精度较高速度极快的人像分割,并且这种极轻量化的分割网络也在其他任务中给了我们应用的启发。
SINet包含空间压缩模块和信息遮挡编码器,前者通过使用多种尺寸的感受野信息来保持空间一致性,并且压缩特征图分辨率来消除多分支结构带来的高延迟;后者根据小分辨率特征图的置信图来提取大分辨率特征图上的必要信息
1. 信息遮挡编码器
编解码结构是语义分割模型中的常见结构,编码器用于提取输入图片的语义信息,解码器用于捕获位置信息并还原特征图尺寸(通常借助双线性插值上采样或者转置卷积);通常情况解码器还会接收编码器模块的高分辨率的特征图来进行逐元素的操作,但是这样的操作会加入已经被编码器移除的局部信息从而对最终的结果产生一定的误导,为此论文提出了一个信息遮挡模块。模型根据低分辨率的特征图来屏蔽高分辨率特征图中已经被以高置信度分割出的区域而仅仅筛选出置信度不高的区域参与解码过程。

SINet的整个过程如上图所示,其中包含了这个信息遮挡操作的具体做法,这能够保证低置信度区域能够在高分辨率特征图上得到更多信息并且不损害予以信息。下图所示是一个应用信息遮挡操作的特征图,可以看到边界部分置信度不高。

2. 空间压缩模块
多分支结构的优点在于以较少的参数量获得较高的准确度,但是分支越多模型延迟越高,空间压缩模块通过下面的结构来解决这一问题。
S2-Block本质上一个先压缩在解压的操作,通过使用平均池化调整感受也并且降低时延。S2-Module首先通过一个
1
×
1
1\times 1
1×1的点卷积来减半特征图尺寸并使用分组点卷积进行通过混洗,然后通过两个并行的S2-Block后再进行特征图融合,结合一个残差结构并通过PRelu,得到最终的输出结果。
S2-Block使用平均池化而非空洞卷积来调整感受野的原因有两个:1)空洞卷积的网格效应和时延;2)多分支结构对GPU并行计算并不友好。
3. SINet的网络架构

文章在训练模型的时候使用了Lovasz损失,这个损失不但用于主分割流程,还用于边界位置辅助分割网络(使用二进制掩码的形态学腐蚀和膨胀的差作为分割结果的边缘),最终损失为:
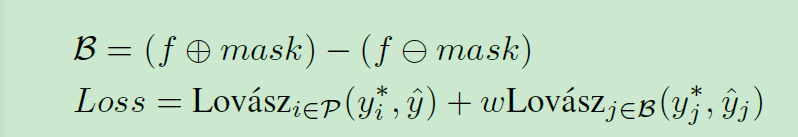
3.数据扩充方法
从通用数据集上跳出包含人像的数据和分割结果;使用DeepLabV3+通用目标分割网络再在人像数据上微调,用于产生人像分割的掩码。(这种方法有什么好特意说的,我也没想明白哈哈~)
4.实验结果
EG1800数据集:


欢迎关注 深度学习与数学 [获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]
















 4247
4247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









