







时空预测
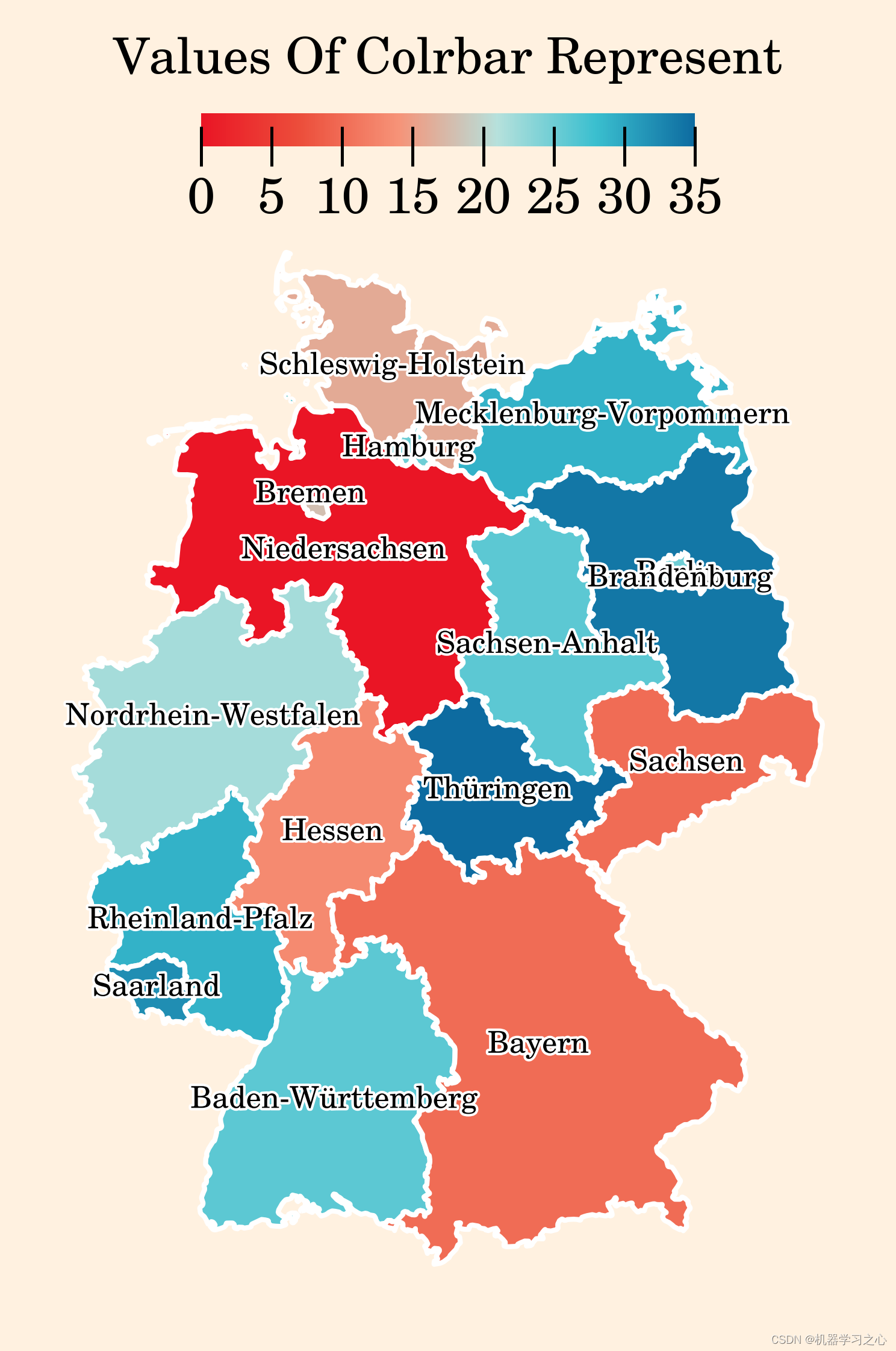
模型描述
数据收集和准备:收集与碳排放相关的数据,包括历史碳排放数据、气象数据、人口密度数据等。确保数据的质量和完整性,并进行必要的数据清洗和预处理。
特征工程:根据问题的需求和领域知识,对数据进行特征工程。这可能包括特征选择、特征变换、数据归一化等操作,以提取能够有效预测碳排放的特征。
构建深度学习模型:选择适当的深度学习模型来建模碳排放时空预测问题。常用的模型包括循环神经网络 (RNN)、长短期记忆网络 (LSTM)、卷积神经网络 (CNN) 等。根据问题的复杂性和数据的特点,可以采用单个模型或者多个模型进行组合。
模型训练:将数据集划分为训练集和验证集,使用训练集对深度学习模型进行训练,并使用验证集进行模型的调优和选择。在训练过程中,可以使用适当的损失函数(如均方误差)和优化算法(如随机梯度下降)来优化模型参数。
模型评估和验证:使用测试集对训练好的模型进行评估和验证。可以使用各种指标来评估模型的性能,如均方根误差 (RMSE)、平均绝对误差 (MAE) 等。
模型部署和预测:将训练好的模型部署到实际应用中,使用实时或者历史数据进行碳排放的时空预测。根据具体需求,可以使用模型输出的预测结果来指导决策或者制定相应的政策。



















 3948
3948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











