







一、学习目标
1.认识篇章分析中的问题
2.了解篇章如何表示
3.掌握篇章的分析方法
4.学习篇章关系的应用
二、篇章分析的任务
以例子来说明的话:

在第一个句子中,原本句子结尾为红色部分,但模型会输出蓝色部分。在第二个句子中,美伊中的伊应该是伊朗,但模型依旧以为是伊拉克。则就展示了以往模型的两个问题:
(1)无法捕捉到比较远的文章信息(如第一句中整段在讲“她”,模型却只看到“小狗”)
(2)过于依赖训练语料库(如第二句,训练语料库有许多美国和伊拉克的句子,而忽视句子讲的是伊朗)
三、篇章的表示
有两种方法:(1)使用神经网络来表示;(2)语言学篇章表示理论。其中,(1)在第7章已讲过,这里重点讲(2)。
1.话题链与回指
没啥好说的,直接看定义和例子:


2.修辞结构理论(RST)
RST是语言学篇章表示理论中的一个经典表示方法,其思想是将原篇章尽可能进行切分成EDU,然后再两两结合,形成更大的EDU,最后合成整个语篇。

常见的语篇结构如下:

于是,我们就可以将一个篇章进行分析:

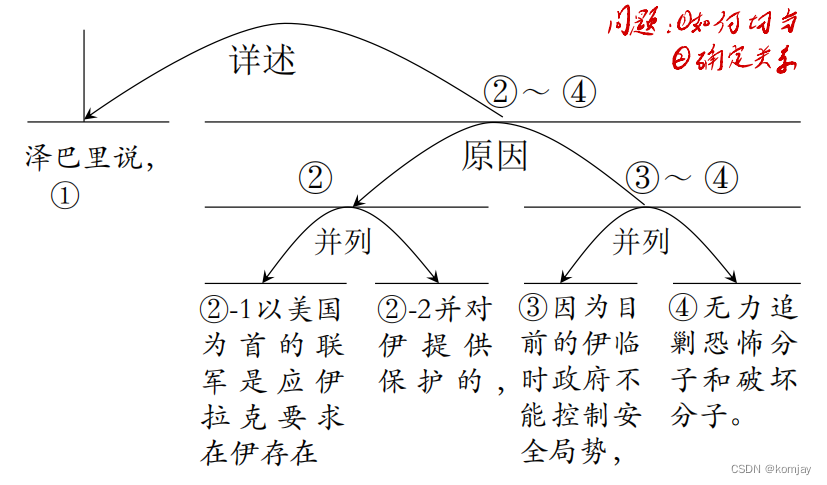
于是,我们需要解决的任务有两个:(1)如何切分EDU,(2)如何确定EDU的关系。具体如何实现,就是下一节篇章分析的任务。
3.其他的语篇理论

四、篇章分析
篇章分析所完成有多种,前面所说的两个任务也是其中的两个,其他的还有:

其中事件共指消解的例子有如下:(既要实现共指,又要消除歧义)

回到上一节的两个任务,我们将其整合一下:

其中论元和EDU可以看成是同一种东西,在实际中,我们一般一开始以句子作为一个EDU。再将任务再划分一下,分成4个步骤:
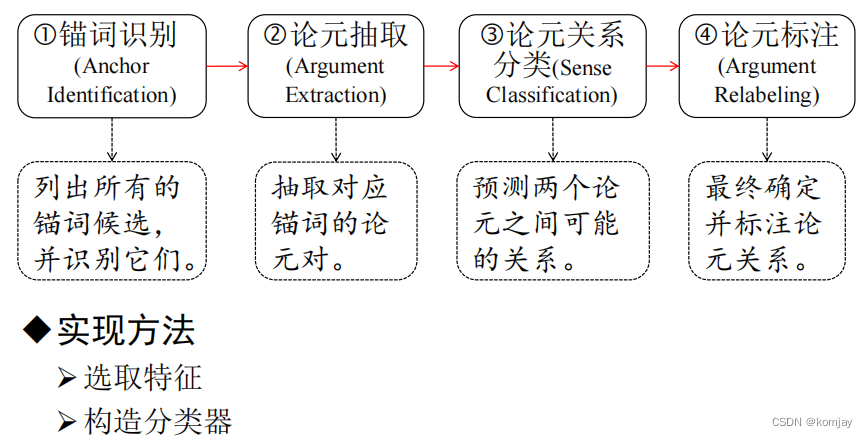
1.锚词识别
其中锚词识别,是用来分割句子的符号,其中以标点符号为主,还有句子中的“并”,“和”这种词。如下:

如何识别出锚词,可以用的特征有:

2.论元划分
经过分析,我们可以发现一些现象:
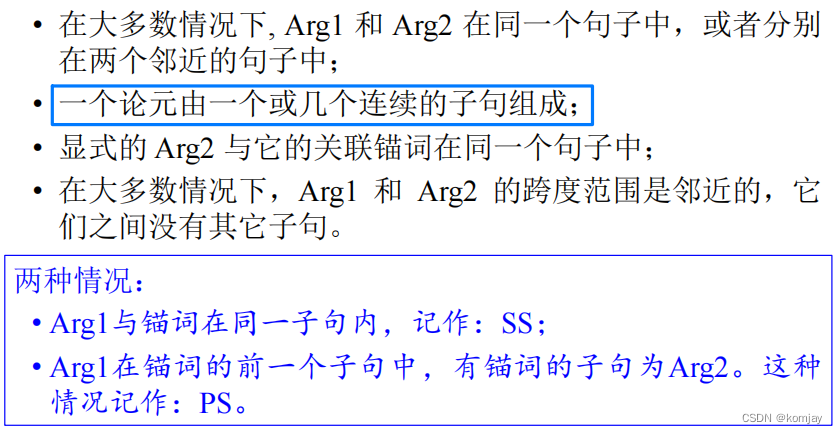
两种情况对应锚点是具体的词和标点符号两种情况:

3.论元关系识别
采用分类的思想。输入的特征分为词法和句法两种,使用的分类器也各种各样。如下:

4.论元标识
该任务是对论元关系识别任务的加深,是要确定两个论元孰前孰后。例子如下:

有了以上理论知识,我们可以用神经网络模型来实现这些工作。
五、神经网络实现篇章分析
1.论元划分
由于锚词识别只是让我们更好的进行论元划分,我们可以直接使用条件随机场(CRFs)来划分论元:
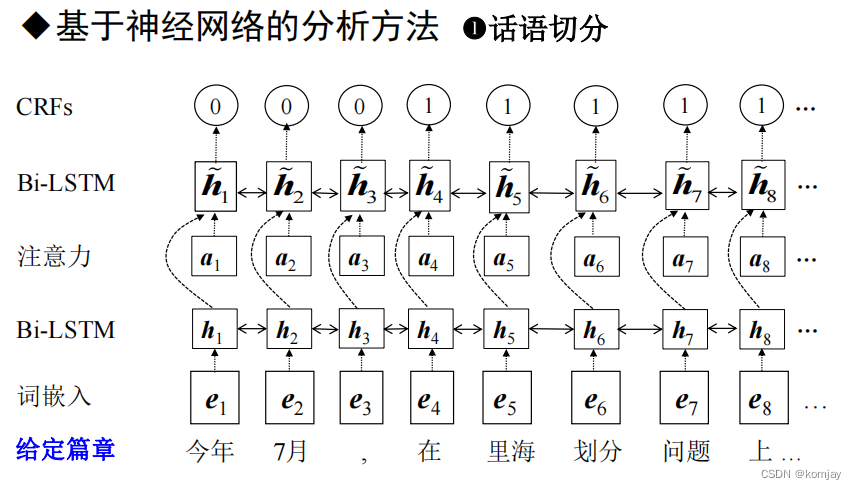
其中,输出为0是论元一,输出为1是论元二。
2.论元关系识别
我们要得到的句子间的关系z,而我们能用到的输入特征有:两个句子的所有词的词向量。整体模型样子如下:
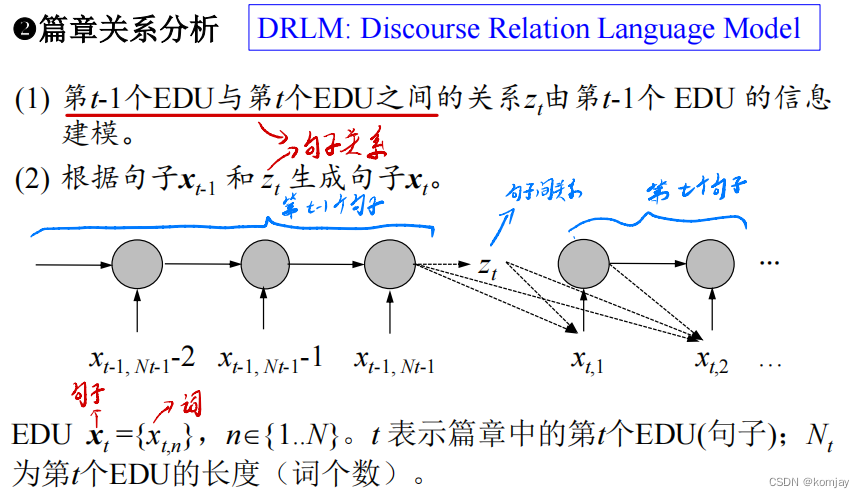
这是一个很特别的模型,因为其结果放在了隐藏层里。这也是DRLM的创新所在。其主体还是一个RNN模型,于是,在n时刻,模型进行的操作是计算隐藏层并计算下一个词的概率:

对计算出下个词的概率的公式进行展开,其包括三部分,之前所有词累计的信息h,上一个词的信息c,偏置项b是:

当上一个句子结束后,并不是预测下一个句子的第一个词,而是引入一个zt(句子关系),并计算出其概率:

再用上一个句子的信息和得到zt来预测下一个句子:

有了上面的目标函数后,我们就可以确定损失函数:

最后,在预测阶段,可以使用贝叶斯公式来确定句子间到底是什么关系:

六、篇章关系的应用
篇章关系的应用有很多,包括:机器翻译、人机对话、阅读理解、自动摘要等。我们以在机器翻译中为例:
1.传统机器翻译的问题:

于是想到的方法是:
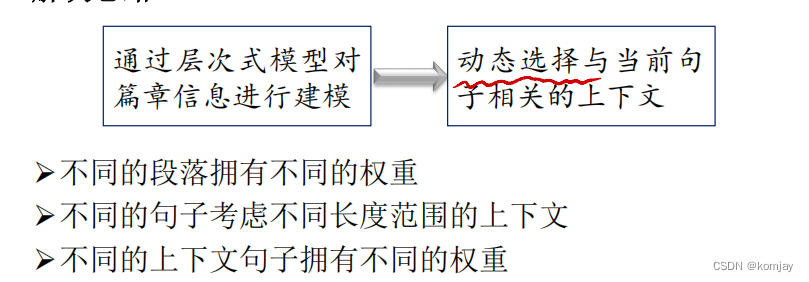
这就是篇章关系能做到的动态调整,举个例子来说:(这是使用篇章关系后的结果)

其使用篇章关系的过程如下:

七、本章小结
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









