







yolo 学习系列(四):训练结果评估
1 评价参数
1.1 召回率 Recall 和 精确率 Precision
具体公式不在赘述
以在大雁和飞机的图片中识别飞机为例:
- Precision其实就是在识别出来的图片中,飞机所占的比率
- Recall 是被正确识别出来的飞机个数与测试集中所有飞机的个数的比值
1.2 平均正确率 Average_precision(AP)
- 调节阈值K,可以得到不同的(P-R),最终可以让recall变化从0到1.
- 每一类都可以根据recall和precision绘制P-R曲线,AP就是该曲线下的面积。而mAP就是所有类AP的平均值。
2 结果评估
2.1 训练日志保存
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23 2>1 | tee yolo-voc.txt
2.2 验证命令
darknet.exe detector valid data/voc.data cfg/yolov2-tiny-voc.cfg backup/yolov2-tiny-voc_11400.weights -out -gpu 0 -thresh .5
darknet.exe detector valid data/voc.data cfg/yolov2-tiny-voc.cfg backup/yolov2-tiny-voc_11400.weights -thresh .5
python reval_voc_py3.py --year 2007 --classes data/voc.names --image_set test --voc_dir data/mkw/VOCdevkit/ results
2.3 召回率
darknet.exe detector recall data/voc.data cfg/yolov2-tiny-voc.cfg backup/yolov2-tiny-voc_11400.weights
2.4 mAP
darknet.exe detector map data/voc.data cfg/yolov2-tiny-voc.cfg backup/yolov2-tiny-voc_11400.weights
2.5 生成loss-iter曲线
在执行训练命令的时候加一下管道,tee一下log
./darknet detector train cfg/voc.data cfg/yolo-voc.cfg | tee training.log
将下面的python代码保存为drawcurve.py,并执行
python drawcurve.py training.log 0
python的代码为
import argparse
import sys
import matplotlib.pyplot as plt
def main(argv):
parser = argparse.ArgumentParser()
parser.add_argument("log_file", help = "path to log file" )
parser.add_argument( "option", help = "0 -> loss vs iter" )
args = parser.parse_args()
f = open(args.log_file)
lines = [line.rstrip("\n") for line in f.readlines()]
# skip the first 3 lines
lines = lines[3:]
numbers = {'1','2','3','4','5','6','7','8','9','0'}
iters = []
loss = []
for line in lines:
if line[0] in numbers:
args = line.split(" ")
if len(args) >3:
iters.append(int(args[0][:-1]))
loss.append(float(args[2]))
plt.plot(iters,loss)
plt.xlabel('iters')
plt.ylabel('loss')
plt.grid()
plt.show()
if __name__ == "__main__":
main(sys.argv)
3 mAP计算与PR曲线绘制
3.1 运行detector valid指令,生成对测试集的检测结果
命令格式: ./darknet detector valid <voc.data文件路径> <cfg文件路径> <weights文件路径> -out “”
例如:
./darknet detector valid ./cfg/voc.data cfg/yolov2-tiny-voc.cfg results/yolov2-tiny-voc_10000.weights -out ""
验证集在voc.data文件中已定义
classes= 1
train = /home/chris/darknet/scripts/2007_train.txt
valid = /home/chris/darknet/scripts/2007_val.txt # 此条命令用到该路径
names = data/voc.names
backup = /home/chris/darknet/results/
运行后在…/darknet/results/下生成一个 sea cucumber.txt 文件
其中txt中数据格式为: 文件名 置信度 x y w h
将文件名修改为 comp4_det_val_sea cucumber.txt

3.2 计算mAP并生成pkl文件
命令格式:python reval_voc.py --voc_dir <voc文件路径> --year <年份> --image_set <验证集文件名> --classes <类名文件路径> <输出文件夹名>
例如:
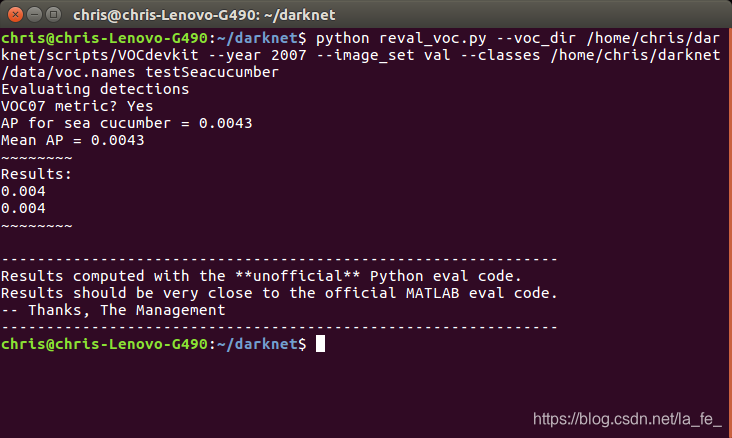
python reval_voc.py --voc_dir /home/chris/darknet/scripts/VOCdevkit --year 2007 --image_set val --classes /home/chris/darknet/data/voc.names testSeacucumber
# 此处的坑是 --image_set 后是 val,要与 voc.data 名称一致
这里用到两个文件 reval_voc.py 和 voc_eval.py ,将它们放在 darknet 一级目录下运行以上命令即可得到map值,并在testSeacucumber文件夹内得到 sea cucumber_pr.pkl 文件
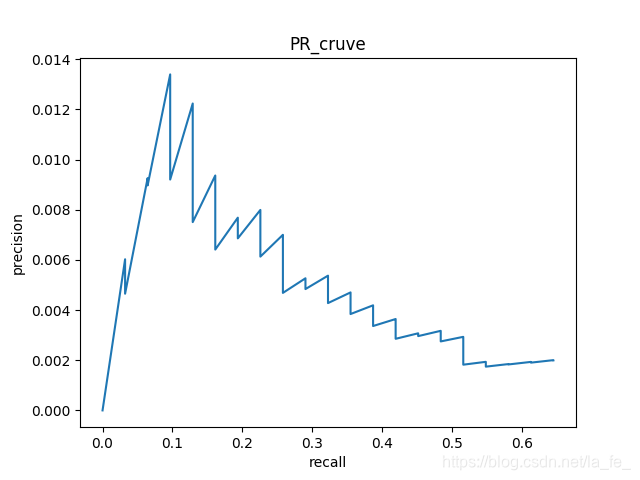
3.3 绘制PR曲线
在testSeacucumber文件夹内新建一个PR_draw.py文件,内容如下:
# -*- coding: utf-8 -*
#import _pickle as cPickle
import cPickle
import matplotlib.pyplot as plt
fr = open('sea cucumber_pr.pkl','rb')
inf = cPickle.load(fr)
fr.close()
x=inf['rec']
y=inf['prec']
plt.figure()
plt.xlabel('recall')
plt.ylabel('precision')
plt.title('PR_cruve')
plt.plot(x,y)
plt.show()
print('AP:',inf['ap'])
运行命令
python PR_draw.py















 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











