







一、PyTorch与计算机视觉简介
PyTorch是一个开源的深度学习框架,其动态图的特性非常适合快速实验和模型原型设计。在计算机视觉任务中,如图像分类、目标检测、图像分割等,PyTorch提供了丰富的API和预训练模型,帮助开发者快速搭建和优化模型。
二、使用官方数据集
1. 数据集准备
PyTorch附带了torchvision库,它不仅包含了常用的计算机视觉模型,还有对经典数据集(如CIFAR-10、CIFAR-100、MNIST、ImageNet等)的便捷访问。以MNIST为例,您可以这样加载数据集:
# MNIST dataset
train_dataset = torchvision.datasets.MNIST(root='data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='data/',
train=False,
transform=transforms.ToTensor())数据将会保存在data路径下![]()
三、生成自己的数据集合
1、使用官方数据集从压缩包转成图片跟标签。
def convert_to_img(train=True):
if(train):
f=open('./data/train.txt','w')
data_path='./data/data_train/'
if(not os.path.exists(data_path)):
os.makedirs(data_path)
for i,(img,label) in enumerate(zip(train_set[0],train_set[1])):
img_path=data_path+str(i)+'.jpg'
print('train_img_path:', img_path, 'train_img_num:', i)
io.imsave(img_path,img.numpy())
f.write(str(label.item()) + '\n')
f.close()
else:
f = open('./data/test.txt', 'w')
data_path = './data/data_test/'
if (not os.path.exists(data_path)):
os.makedirs(data_path)
for i, (img, label) in enumerate(zip(test_set[0], test_set[1])):
img_path = data_path + str(i) + '.jpg'
print('test_img_path:', img_path, 'test_img_num:', i)
io.imsave(img_path, img.numpy())
f.write(str(label.item()) + '\n')
f.close()
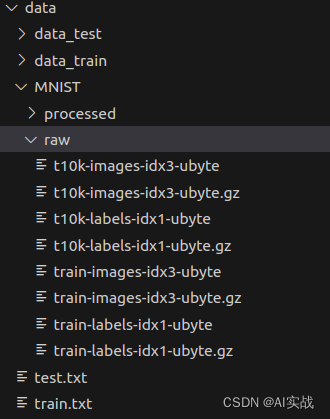
最终我们便将官方数据集合转成自己的数据集,可以自行使用。最终的数据的组成如下:
四、构建自定义数据集
当标准数据集不能满足特定需求时,创建自定义数据集变得尤为重要。
1. 数据集结构
首先,您需要按照一定的结构组织您的数据。一般建议为每个类别创建单独的文件夹,文件夹内存放对应类别的图片。
2. 编写数据集类
继承torch.utils.data.Dataset,实现__len__和__getitem__方法:
class CustomImageDataset(Dataset):
def __init__(self, data_path, model, transform=None, target_transform=None):
self.data_path = data_path
self.model = model
self.img_labels = []
self.image_lists =[]
self.transform = transform
self.target_transform = target_transform
self.obtain_label_image()
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img = Image.open(self.image_lists[idx])
image = np.array(img)
label = self.img_labels[idx]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
def obtain_label_image(self):
if(self.model == "train"):
# 指定文件夹路径
folder_path = self.data_path + 'data_train/'
# 获取文件夹中的文件列表
file_list = os.listdir(folder_path)
for i in range(len(file_list)):
image_path = folder_path + str(i) +".jpg"
#print(image_path)
self.image_lists.append(image_path)
file_path = self.data_path + 'train.txt' # 替换为实际文件路径
with open(file_path, 'r') as file:
# 逐行读取文件内容
for line in file:
# 处理每一行的数据,例如打印或存储
self.img_labels.append(int(line.strip())) # 使用strip()方法去除行末的换行符
if (self.model == "test"):
# 指定文件夹路径
folder_path = self.data_path + 'data_test/'
# 获取文件夹中的文件列表
file_list = os.listdir(folder_path)
for i in range(len(file_list)):
image_path = folder_path + str(i) +".jpg"
#print(image_path)
self.image_lists.append(image_path)
file_path = self.data_path + 'test.txt' # 替换为实际文件路径
with open(file_path, 'r') as file:
# 逐行读取文件内容
for line in file:
# 处理每一行的数据,例如打印或存储
self.img_labels.append(int(line.strip())) # 使用strip()方法去除行末的换行符通过以上步骤,您已成功使用PyTorch从官方数据集过渡到了自定义数据集的训练流程,这是进行计算机视觉项目定制化研究和应用的重要起点。随着实践的深入,您将能够更熟练地利用PyTorch的强大功能,探索更多计算机视觉的前沿应用。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









