







Abstract
3D实例分割(3DIS)是一项关键任务,但在全监督设置中进行点级注释非常繁琐。因此,使用边界框(bboxes)作为注释显示出了巨大的潜力。目前的主流方法是两步过程,包括从边界框注释生成伪标签,然后用伪标签训练3DIS网络。然而,由于边界框之间的交叉存在,不是每个点都有确定的实例标签,尤其是在重叠区域。为了生成更高质量的伪标签并实现更精确的弱监督3DIS结果,我们提出了用于3D实例分割的基于盒监督的模拟辅助平均教师(BSNet),其设计了一种名为模拟辅助Transformer的创新伪标签生成器。该标签生成器由两个主要部分组成。第一个是模拟辅助平均教师,首次将平均教师引入该任务,并构建模拟样本以帮助标签生成器获取重叠区域的先验知识。为了更好地建模局部-全局结构,我们还提出了作为教师和学生标签生成器解码器的局部-全局感知注意力。我们在ScanNetV2和S3DIS数据集上进行的广泛实验验证了我们设计的优越性。
代码地址:https://github.com/peoplelu/BSNet
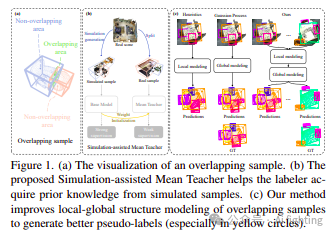
Introduction
3D实例分割是3D场景理解中的基本任务,主要集中在为场景中的每个前景对象预测掩码和类别。当前的实例分割方法主要在全监督设置下进行,并取得了可观的结果。然而,点级注释的耗时性提出了重大挑战。相比之下,使用3D边界框(对象级别)注释实例明显更容易,只需要中心点和尺寸(长度、宽度、高度)的注释。然而,使用边界框的显著限制在于它们无法捕捉到对象的详细形状或几何。因此,弥合对象级别和点级别注释之间的差距仍然是一个挑战。
-
现有方法通过Box2Mask参数化边界框来标记点云,但存在边界框重叠导致点对象分配不明确的问题。
-
WISGP采用直接启发式方法解决重叠区域模糊性,选择邻近点中最常见标签。
-
Gapro使用高斯过程训练重叠样本,通过后验概率实现二元分类。
-
-
生成重叠区域标签:使用平均教师和EMA优化伪标签,同时利用非重叠区域构建模拟重叠样本训练基础模型。
-
建模重叠样本结构:现有方法要么关注局部结构,要么强调全局关系,需要设计通用网络整合两者以生成更精确的伪标签。
-
Method
3.1概述
如图 2(I) 所示,我们的方法框架首先根据 bbox 注释为训练集中的实例生成伪对象掩码。随后,这些伪对象掩码用于训练 3DIS 网络。在整个过程中,最关键的步骤是生成一个出色的伪标签器,以预测重叠区域的伪标签,如图 2(II) 所示。在生成过程中,有两个显著的设计亮点。第一个是采用了一种独特的训练策略,称为模拟辅助平均教师(Simulation-assisted Mean Teacher,SMT)
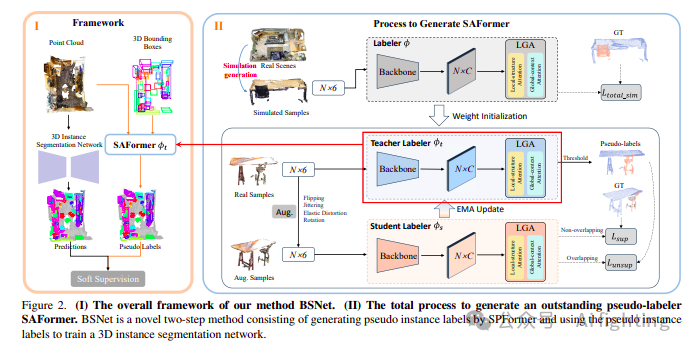
3.2. SAFormer 的生成过程
我们开发了一种新型的伪标签器,称为 SAFormer,能够准确预测重叠区域的标签,从而在 bbox 监督的 3DIS 中取得精确的结果。接下来,我们将依次介绍生成过程。
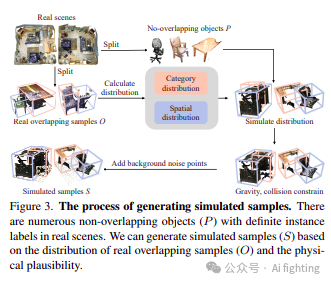
3.2.1 模拟样本生成
ScanNetV2 中丰富的具有明确实例标签的非重叠 bboxes 允许我们生成模拟的重叠样本。如图 3 所示,我们首先从真实场景中提取真实的重叠样本 O 和非重叠对象 P。随后,我们对这些真实重叠样本进行类别分布和空间分布的分析。具体来说,我们确定哪些类别对构成重叠样本,计算每个类别对的样本数量 n,并计算每个类别对中心点之间距离的平均值 µ 和方差 σ。在获得统计数据后,我们开始模拟分布。首先,我们根据 n 的分布进行类别对的采样。假设采样的类别对为 (a, b),然后我们从集合 P 中为每个类别 a 和 b 均匀采样一个对象点云。在获得这两个点云后,我们基于相应的 µ 和 σ 进行高斯采样以获得距离 d,表示这两个点云之间的距离。最后,为了简化操作,我们直接沿 X 轴或 Y 轴平移其中一个点云 d 距离。值得注意的是,在进行距离平移之前,我们对点云对的中心点进行对齐。为了更好地保持物理合理性,我们基于以下两个原则进行场景调整:1) 重力:对象不应漂浮在空中;2) 碰撞:这两个对象不应表现出任何碰撞。具体细节在补充材料中涵盖。设计碰撞约束的另一个目的是验证在构建模拟样本时两个对象是否可以匹配。具体来说,在多次(上限为 M)距离采样和碰撞约束校正之后,某些对象对可能仍然无法生成重叠区域。这些对随后被排除使用。最后,考虑到真实重叠样本包含背景噪声点,我们添加适当数量的地板点来表示背景噪声点的存在。
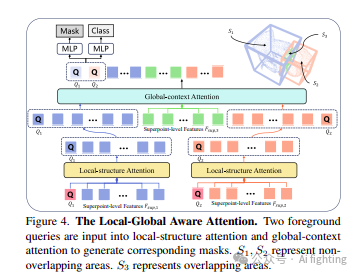
3.2.2 局部-全局感知注意力
如图 4 所示,LGA 主要包含局部结构注意力和全局上下文注意力。假设输入的点云由 N 个点组成,每个点包含位置信息 (x, y, z) 和颜色信息 (r, g, b)。首先,我们将点云输入到轻量级 3D-UNet 中以获得点级特征 F。随后,遵循 SPFormer,我们使用平均池化将点级特征 F 聚合成超点级特征 Fsup。接下来,我们初始化两个可学习查询 Q1 和 Q2,分别代表两个前景实例。为了更好地建模局部结构,我们分别在不同实例的非重叠区域内使用自注意力层和前馈层。此方法确保每个局部区域与属于同一实例的类似区域进行交互,显著增强了局部结构的判别能力和表示能力。具体来说,我们将 Fsup,1 与 Q1 以及 Fsup,2 与 Q2 连接起来形成 Fv,1 和 Fv,2,然后分别输入它们,其中 Q = Fv,iWq, K = Fv,iWk, V = Fv,iWv,Wq, Wk, Wv 表示查询、键和值的线性变换矩阵。最后,我们将 F′v 输入到前馈层中以获得 F′′v。在建模每个非重叠区域 S1 和 S2 内的局部结构并通过前景查询将这些结构聚合成整体表示后,我们需要整合全局信息。具体方法是将 F′′v,1、F′′v,2 和 Fsup,3 的特征连接起来。然后,我们将这些连接的特征输入到自注意力层和前馈层中。通过这种方法,我们可以建模非重叠区域与重叠区域之间、两个前景实例之间的关系,并将这些全局关系聚合到 Q1 和 Q2 中。最后,为了分类重叠区域,我们通过计算 Fsup,3 与 Q1、Q2 之间的点积来获得两个对象的掩码 Mins,1 和 Mins,2。最终的掩码通过 Sigmoid 函数和 0.5 阈值获得:Mi = Sigmoid(Mins,i) > 0.5, i = 1, 2。由于 M1 和 M2 代表两个不同的前景对象掩码,对于 M1 和 M2 都未激活的区域,我们将其分类为背景区域。这种方法自然地帮助标签器过滤掉背景点,这相比 Gapro [29] 是一种改进,因为 Gapro 忽略了背景点的存在。此外,为了更好地帮助标签器学习同一类别的统一知识,我们添加了一个类别预测头。在模拟重叠样本 S 上训练时,由于实例标签是完整的,我们直接使用 SPFormer和 Mask3D 的共享损失:Ltotal_sim = λ1Lcls + λ2Lbce + λ3Ldice,其中 λ1、λ2、λ3 是超参数,Lcls 是交叉熵损失,Lbce 是二元交叉熵损失,Ldice 是 dice 损失。
3.2.3 平均教师方法
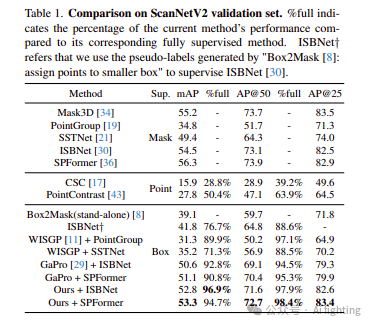
在上述过程中,标签器 ϕ 已通过在模拟样本上的训练学习了重叠场景的先验知识。随后,我们使用预训练权重作为教师标签器 ϕt 和学生标签器 ϕs 的初始权重。然后,我们对真实的重叠样本进行数据增强,包括翻转、抖动、弹性变形等。原始样本被输入到教师标签器中,而增强样本被输入到学生标签器中。由于真实样本中非重叠区域的标签是已知的,我们可以直接监督这些区域。对于重叠区域,为了更好地利用教师标签器的预测,我们基于固定阈值 τ 为重叠区域选择高置信度的伪标签。教师标签器使用 EMA 技术更新其参数。通过这种设计,教师标签器可以在线持续更新伪标签并将知识传递给学生。与此同时,学生标签器可以使用 EMA 将获得的知识传递回教师。进一步来说,通过模拟获得的初始化权重,教师标签器获得了区分重叠区域的能力。它可以生成更高质量的伪标签,加速平均教师的训练速度。最终,经过良好训练的教师标签器 ϕt 被称为 SAFormer,用于生成重叠区域的最终伪标签。对于真实样本的微调,我们采用弱监督方法。具体方法可以分为两部分。首先,对于非重叠区域,由于标签已知但仅是完整对象的部分标签,我们仅监督非重叠区域:M′ = QsF T Experiments 4.2. 与最先进方法的比较 ScanNetV2。如表1所示,我们将我们的方法与ScanNetV2验证集上的现有最先进方法进行了比较。得益于通过SMT构建的模拟样本的创新性和LGA建模局部和全局信息的能力,我们提出的SAFormer可以生成更高质量的伪标签来监督3DIS网络。因此,我们的box-supervised 3DIS方法在mAP、AP@50和AP@25方面显著优于其他方法。值得强调的是,我们的结果在mAP方面可以达到与相应的完全监督方法相比的95%。这比之前的方法有了显著提升,之前的方法通常只能达到约90%的性能。为了生动地展示我们方法与其他方法之间的差异,我们在图5中可视化了伪标签的定性结果。从黄色圆圈突出显示的区域可以看出,我们的方法可以为重叠区域生成更准确的伪标签。
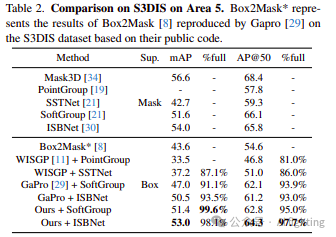
S3DIS。我们在S3DIS上使用区域5进行评估,如表2所示。我们提出的方法在mAP和AP@50方面优于之前的方法,展示了我们方法的有效性和泛化能力。

Experiments
消融研究
以下实验在ScanNetV2验证集上进行,而其他实验在ScanNetV2训练集上进行。借助mAcc,我们可以探讨不同技术对处理重叠区域的影响。
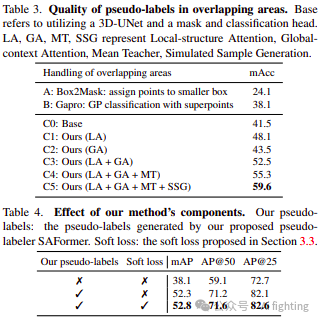
如表3所示,设置B代表当前处理重叠区域的最先进技术,其性能显著高于设置A。我们将我们的方法SAFormer与这些方法进行比较,并在设置C中对每个组件进行消融研究。在设置C0中,由于神经网络的强大拟合能力,即使不使用我们提出的SMT和LGA,我们的基本性能仍然超过了当前的最先进方法Gapro。在设置C1中,我们直接使用骨干网络和LA在真实场景上训练标签生成器。结果显示mAcc比Gapro提高了10.0,表明通过专门的局部结构建模和多个样本的累积,深度神经网络可以准确预测重叠区域标签。在设置C2中,我们将LA替换为GA,mAcc比Gapro提高了5.4。
组件的效果。表4展示了不同组件的3DIS结果。在第一行中,我们评估了训练期间忽略重叠区域并仅使用确定区域作为伪标签的方法。第二行展示了我们提出的标签生成器SAFormer所生成伪标签的有效性,使mAP提高了14.2。在最后一行中,为验证软损失的影响,我们进行了相应的消融实验,并使mAP的性能提升了0.5。
不同伪标签利用方法的效果。如表5所示,我们观察到迭代自训练对性能提升的贡献最小,而Mean Teacher则使mAcc提高了2.8。研究结果表明,Mean Teacher可以通过促进学生和教师标签生成器之间的信息传递,生成更高质量的伪标签。
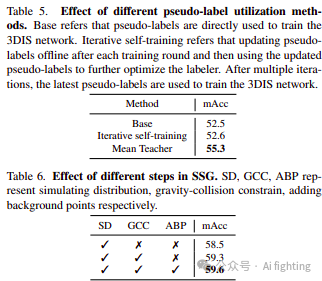
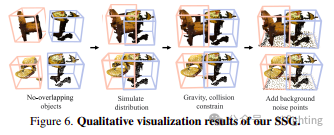
SSG不同步骤的效果。表6显示,随着模拟重叠样本变得更真实,伪标签的质量变得更好。值得注意的是,加入背景点使mAcc提高了0.3。这部分是因为它使样本更真实。另一方面,由于我们设计的使用sigmoid函数的掩码激活,可以自然过滤掉背景点。为了更生动地展示生成过程,我们在图6中可视化了定性结果。显示生成的模拟样本成功地将单个3D形状以有意义的方式结合在一起。
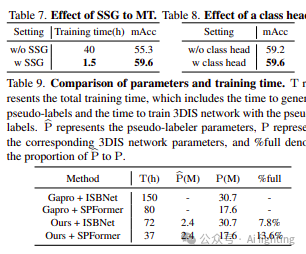
SSG的效果。如表7所示,在SSG的帮助下,标签生成器可以预测更高质量的伪标签。此外,由于标签生成器初始化时使用模拟样本,教师标签生成器在训练初期可以提供更稳定和准确的伪标签,从而加快整体训练过程。
类别头的效果。根据表8,可以推断出加入类别头有助于标签生成器为同一类别获取统一的表示,从而生成更精确的伪标签。
总结:
本研究的主要贡献如下:
(i)提出了一种弱监督3D实例分割方法BSNet,使用边界框作为注释并设计了一种新型伪标签生成器。
(ii)设计了一种开创性的伪标签生成器SAFormer,首次将深度神经网络和平均教师范式结合起来,并创新性地构建模拟样本以促进训练。此外,在LGA的帮助下,SAFormer可以准确地为重叠区域预测伪标签,从而实现精确的弱监督3DIS结果。
(iii)在两个标准基准数据集ScanNetV2和S3DIS上进行了广泛的实验,验证了设计的优越性。
引用文章:
BSNet: Box-Supervised Simulation-assisted Mean Teacher for 3D Instance Segmentati
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









