







PD-LTS:使用多层图卷积将点云映射到潜在空间进行点云去噪
Abstract
点云数据常常包含噪声和离群点,这给下游应用带来了障碍。在这项工作中,我们引入了一种新的点云去噪方法。通过利用潜在空间,我们可以明确地揭示噪声组件,从而提取出干净的潜在代码。这进一步促进了通过逆变换恢复干净点的过程。我们网络的一个关键组件是一个新的多层图卷积网络,用于捕捉从局部到全局的各种尺度上的丰富几何结构特征。这些特征随后被集成到可逆神经网络中,该网络双射地映射潜在空间,以指导噪声解耦过程。此外,我们采用了可逆单调算子来建模变换过程,有效地增强了集成几何特征的表示。这种增强使得我们的网络能够准确区分潜在代码中的噪声因素和固有的干净点,通过将它们投影到不同的通道上。定性和定量评估表明,我们的方法在各种噪声水平下都优于最先进的方法。
代码地址:https://github.com/yanbiao1/PD-LTS
Introduction
点云在3D视觉任务中是一种流行的数据格式,因为其适应性和效率。它们在自动驾驶、机器人技术、地形测绘和3D城市模型开发等领域得到了广泛应用。这些点云通常使用LiDAR或结构光系统进行捕获。然而,所收集的数据往往包含噪声和异常,这可能阻碍随后的3D重建和渲染过程。因此,去噪是管理和利用3D点云数据中的一个关键问题。
本文提出了一种新型的点云去噪方法,该方法在高维潜在空间中操作,代表了对传统位移基方法的偏离。我们的方法以可逆神经网络为基础。我们采用功能分析中的可逆单调算子来建模我们的可逆神经网络。这种方法通过强制实施Lipschitz约束,为编码过程提供了双射映射,同时保持了灵活和富有表现力的架构设计。为了增强我们可逆神经网络的能力,特别是在扩展感受野和增强点云形状感知方面,我们设计了一个多层图卷积(MLGC)模块。该模块利用EdgeConv有效捕捉局部形状结构。通过密集连接每个EdgeConv层的多层特征,我们促进了上下文语义信息的逐步累积。结果丰富的特征集随后被集成到可逆神经网络中。
我们的方法引入了一个先验潜在空间,其中噪声和固有的干净点被明显地分隔到不同的维度中。我们利用集成的MLGC特征在可逆神经网络中参数化欧几里得空间与先验潜在空间之间的双射映射。这种策略有效地揭示了噪声卷积的点云分布。在潜在空间中隔离噪声后,我们屏蔽了与噪声相关的维度,从而生成干净的潜在代码。通过逆变换这些代码,我们获得了无噪声的点云。
值得注意的是,我们的方法与传统的位移基方法 fundamentally不同,后者通常依赖于特征回归。通过利用MLGC的几何特征,我们的方法在由可逆神经网络提供的高维潜在空间中实现了更具表现力的表示。此外,我们的去噪策略专注于在潜在空间中显式提取噪声,而不是直接操纵欧几里得空间中的点。这种对潜在空间处理的关注不仅提高了去噪的有效性,还保留了原始点云数据的结构完整性。
3. Method
3.1 动机
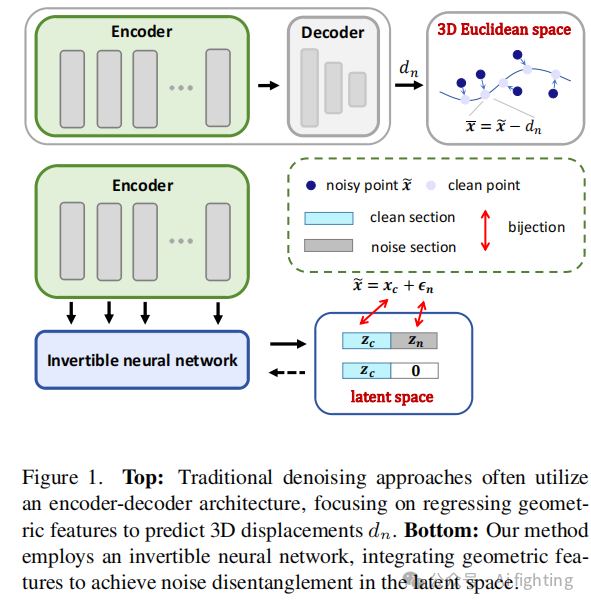
我们将深度学习去噪方法分为两种类型。第一种是通过直接移动点在3D欧几里得空间中进行去噪,也称为位移估计方法,其一般过程如图1(上)所示。这些方法回归几何特征到3D位移以去除噪声点,去噪目标是
![]()
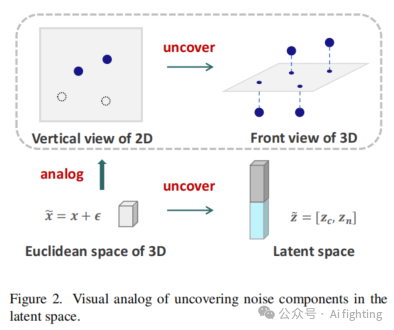
。这一过程非同小可,限制了特征的表达能力,因为直观上把握复杂的形状结构总是需要高维特征空间。受到第二种方法的启发,该方法在高维特征空间中进行去噪,我们旨在利用潜在空间来揭示噪声组件并提取干净的潜在代码。为了直观描述这个过程,我们将去噪问题类比为将异常点投影到平面上(见图2)。观察3D欧几里得空间中的噪声点云可以类比为平面的2D垂直视图,其中点与平面之间的空间关系不明确,因为噪声成分隐藏在3D坐标中,形式为加法:
![]()
。因此,我们可以改变视觉角度,从3D的正视图中获得明确的空间关系。这一过程可以类比为在高维潜在空间中找到点云的表示,其中噪声组件被显式地分离和揭示。如图2的右下角所示,噪声成分和固有的干净点被分离到不同的潜在代码通道中:
![]()
,然后我们可以将噪声通道设为0,以获得干净的潜在代码。通过形成双射映射,在潜在空间中将设为0 可以准确地反映坐标空间中的双射变化:
![]()
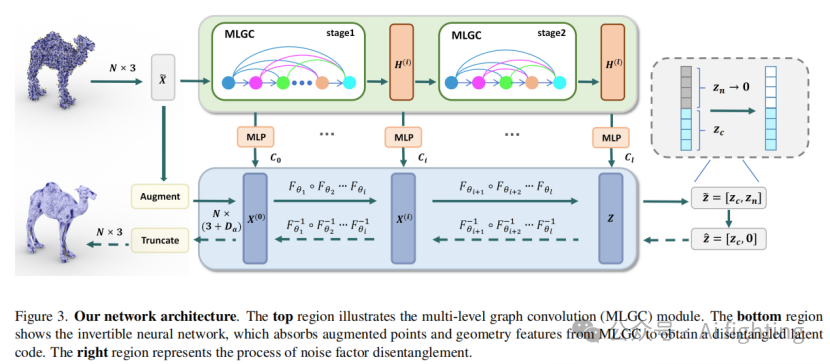
。因此,我们的方法的训练目标是匹配潜在空间,以便揭示噪声。为此,我们首先基于可逆单调算子的理论建模一个可逆神经网络,然后设计一个多层次图卷积(MLGC)模块,以提取形状结构特征,并将其整合到可逆神经网络中,以指导噪声的分离过程。整体网络架构如图3所示。
3.2 可逆神经网络
在偏微分方程和泛函分析领域,单调算子具有丰富的函数空间和可逆属性。受此启发,我们引入了一种基于单调算子的可逆神经网络来建模双射映射。
3.2.1 可逆变换
设
![]()
是一个Lipschitz连续函数,其Lipschitz常数。基于的前向变换定义为:
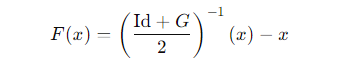
其中,Id 表示恒等函数。根据可逆单调算子的理论,𝐹是单调的当且仅当𝐺是1-Lipschitz的(L<1),并且严格单调的连续函数𝐹:
![]()
是可逆的。因此,对于公式 (1),我们有逆变换公式:
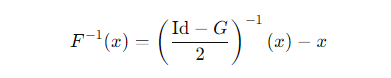
有关可逆变换的证明和更多细节,请参阅相关文献。此外,根据Banach不动点定理,(Id + G)具有唯一的逆,为了计算公式 (1) 中的逆函数
![]()
的结果,我们迭代y=x−G(y) 经过一定步骤以收敛到𝑦,满足精度要求,公式 (2) 也是如此。
3.2.2 建模可逆神经网络
为了使用神经网络块实现公式 (1) 中的1-Lipschitz函数𝐺,我们将线性映射与1-Lipschitz激活函数组合。对于简单情况,设
![]()
,其中是1-Lipschitz激活函数,我们有:
![]()
其中, 表示谱范数。因此,我们可以对
𝑊进行谱正则化,以强制.然后,我们将多个满足
![]()
的块组合在一起,来建模公式 (1) 中的1-Lipschitz函数𝐺,它具有非约束和表达性强的架构,因为与基于仿射耦合层的INN相比,它不需要维度分区,这使得我们的INN能够有效地与多层次图卷积网络结合,以实现去噪的可逆编码过程。
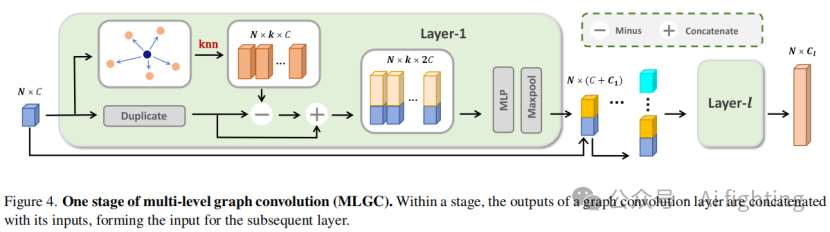
3.3 多层次图卷积
DGCNN 提出了一个动态图卷积框架,以捕捉点云的丰富几何属性。它动态地构建点之间的有向图,并通过 EdgeConv 提取边缘特征,这些特征恢复了涉及的拓扑,并反映了邻近点之间的关系。因此,我们引入了 DGCNN 框架来进行几何特征提取,并在每个 EdgeConv 层之间添加密集连接,以捕捉上下文语义信息。具体来说,我们首先基于点之间的3D欧几里得距离构建k最近邻(k-NN)图G=(V,E),其中
![]()
和
![]()
分别表示顶点和边,然后在随后的每个 EdgeConv 层中固定图。给定点云
![]()
,初始特征向量通过以下方式生成:
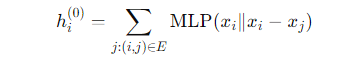
其中𝑖是图上的一个顶点,(i,j) 表示一条边,∥表示拼接。然后,在每个后续层 𝑙中,我们通过 EdgeConv 生成新的特征:
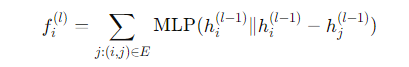
这从
![]()
中捕捉局部和全局几何结构。为了实现密集连接,从第1层 EdgeConv 开始,我们将所有先前层的输出作为每一层的输入,并将它自己的输出作为所有后续层的输入。因此,使用第𝑙层 EdgeConv 的作为第 层的输入,描述如下:
![]()
其中表示拼接。我们在两个阶段分别执行密集连接,从而构建了分层的多层次图卷积(MLGC)网络。一个阶段的架构如图4所示。
3.4 可逆编码过程
编码过程的目标是获得噪声点云的潜在表示
![]()
其中噪声和干净部分分别分离到和。为实现这一目标,我们的编码过程需要满足两个要求:
-
编码过程是可逆的,允许从干净的潜在表示恢复原始的干净点云,无需额外的解码器学习。
-
有效地捕捉局部形状结构,这对于准确预测和分离干净表示至关重要。我们从公式 (1) 推导出,F(x) 的神经网络不能汇聚邻近特征来提供局部区域的感受野,这导致了局部形状感知的丧失。因此,我们将MLCG网络的特征整合到基于公式 (1) 的可逆神经网络(INN)中。为此,我们首先分层构建可逆网络。根据公式 (1),单块前向变换的函数族是:
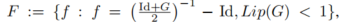
最终,整个可逆变换是多个前向层的组合。因此,利用公式(4)中的密集连接的EdgeConv特征
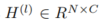
,我们首先通过以下方式进行维度适应和多层次特征融合:
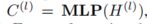
然后我们在每个变换之前通过加法整合:
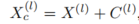
其中第l个前向层的增强变换可以表示为:
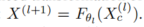
。由于INN的无约束且表达能力强的架构,它可以在保持可逆性的同时进一步增强MLGC特征的表示能力,使得INN和MLGC网络相辅相成,并有效地编码和获取解缠的潜在表示,如图3所示。
3.5 维度增强
根据公式(1),单个前向变换F必须输出与输入数据相同维度的结果。因此,如果我们直接将原始的3D点输入到F中,各前向块之间的特征维度将与3D点一致,这限制了变换能力。因此,为了在编码过程中保持高维特征空间,我们在输入之前对每个点的维度进行了增强。给定一个点xi,我们首先通过以下公式提取其增强特征:
![]()
,其中
![]()
表示的n个最近邻居,f和g由MLP参数化。然后我们将它们连接起来以获得第一个可逆变换层的输入:
![]()
其中
![]()
我们使用增强后的作为可逆编码过程第一层的输入,在各前向块之间保持(3 + Da)维度,并为进一步的MLGC特征表达和噪声成分揭示创建高维空间。
3.6 训练目标
重建损失。我们采用地球移动距离(EMD)来为监督每个去噪点分配干净点,其计算公式为:
![]()
其中Φ是去噪点云与真实值X之间的双射映射,与我们可逆神经网络的双射特性一致。我们发现基于位移的方法通常为每个噪声点分配真实值中的最近点,以计算损失函数中的目标位移。然而,这可能导致在监督过程中丢失大量干净点,而其他干净点可能会监督多个去噪点,这对均匀性有显著影响。而EMD通过保持双射监督很好地解决了这个缺点。
Experiment
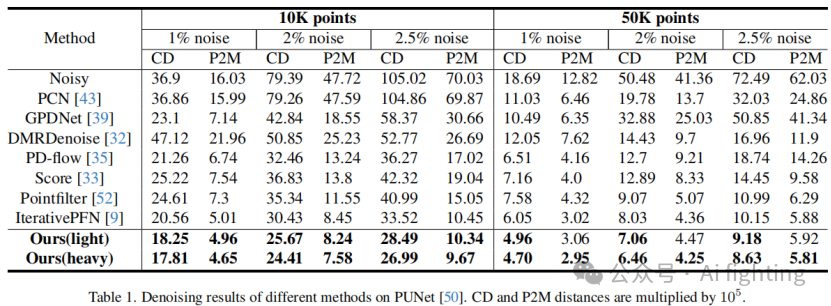
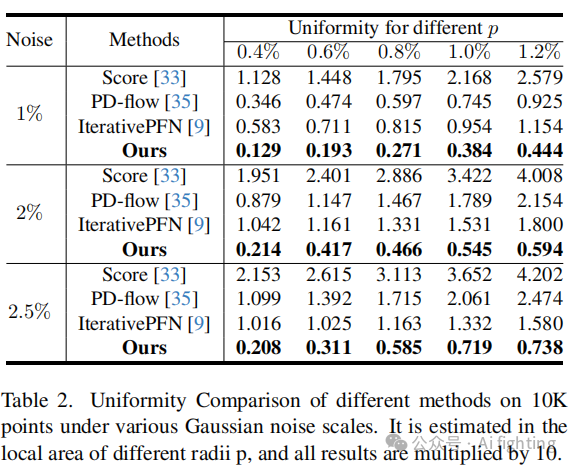
1.定量结果。我们在Chamfer距离(CD)和点到网格(P2M)距离度量上评估了我们的方法,如表1所示。我们的框架在CD方面显示出显著的优势,并在P2M上取得了最先进的结果。我们在表2中进一步比较了我们的重版本网络与最先进方法在均匀性度量上的表现,结果显示我们的方法在均匀性方面具有显著优势。
2.定性结果,图5展示了SOTA(最先进)工作和我们的方法在PUNet上使用10K点和2%高斯噪声的定性结果,其中每个点的颜色深度取决于P2M值。从颜色分布中可以观察到,我们的重版本方法在所有方法中生成了最干净的点云,而第一列显示了噪声输入。此外,观察细节时,我们可以看到我们去噪后的点均匀分布在网格表面上。而其他方法去噪后的点常常聚集在一起,并伴随着许多空洞区域,这影响了均匀性。图6展示了在RueMadame数据库场景中的去噪结果。我们的重版本方法不仅有效恢复了窗台和汽车等物体,还消除了激光扫描造成的线性痕迹。


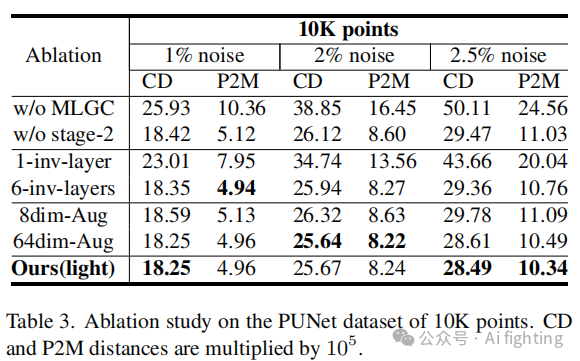
3.消融研究。为了展示各模块的有效性,我们在表3中对轻量版本框架进行了消融研究,研究了以下几个方面:(1)MLGC网络。去掉整个MLGC网络后的结果非常差,这表明其局部形状信息在噪声解离中的极端重要性,去掉MLGC的第二阶段也证明了第二阶段的高级几何特征的积极影响。(2)可逆神经网络。我们将可逆变换缩短为1层和6层。可以从结果中发现,如果没有由足够深的可逆变换提供的高级潜在空间,仅靠图卷积特征难以解离噪声成分。(3)增强维度Da。与使用Da = 48的轻量版本框架相比,Da = 8的特征空间在每个前向层之间不足以表达几何特征和解离噪声,而更高的维度如Da = 64仅带来最小的改进,其在2.5%噪声上的泛化性能甚至恶化。
结论
文章主要有如下贡献:
1.提出了一种基于先验潜在空间的点云去噪算法,其中噪声组件被解耦。通过建模双射映射,通过在先验潜在空间中屏蔽未揭示的噪声,间接地去噪欧几里得空间中的点云。
2,对于双射映射,引入了可逆单调算子来建模一个强大且轻量的可逆神经网络,该网络通过强制Lipschitz约束具有一个无约束和富有表现力的架构。
3.为了改善点云形状结构的捕获和表示,设计了一个多层图卷积模块,采用了EdgeConv和密集连接,并将这些特征集成到可逆神经网络中,以进一步在高维特征空间中表达。
文章引用自:
Denoising Point Clouds in Latent Space via Graph Convolution and Invertible Neural Network
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









