







1、端到端的发展驱动力
1.1 对标驱动:特斯拉FSD的标杆作用吸引行业关注
大部分行业专家表示,特斯拉FSD v12的优秀表现,是端到端自动驾驶这一技术路线快速形成大范围共识的最重要的推动力;而在此之前,从来没有一个自动驾驶产品可以让从业者和用户如此便捷地感受到技术带来的体验提升。
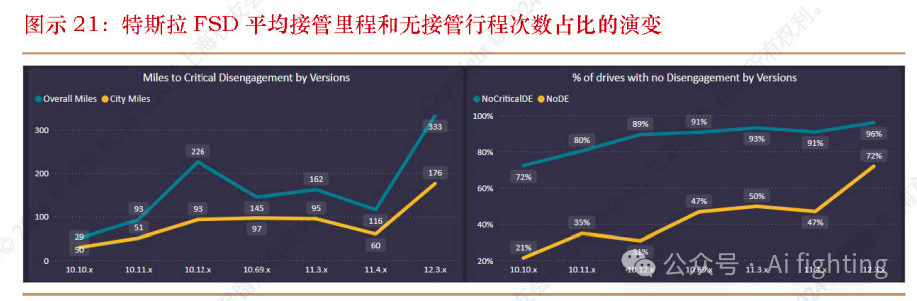
由第三方网站FSDTracker统计的特斯拉车辆接管里程数据也表明了FSD v12的巨大性能提升。在此前很长一段时间,FSD的版本迭代处于瓶颈期,自2022年初FSD v10更新以来,其接管里程数据保持在稳态波动,行业普遍认为这是传统架构的工程优化陷入瓶颈的表现;但FSD v12更新后,较之此前版本,用户完全无接管的行程次数占比从47%提升到了72%,平均接管里程(Miles Per Intervention,MPI)从116英里提高到了333英里,性能的大幅提升代表着端到端技术突破了原有的技术瓶颈,推动自动驾驶系统的能力再上台阶。
作为自动驾驶行业最重要的标杆企业之一,特斯拉的技术路线一直备受关切。从Elon Musk在2023年5月首次公开提出“特斯拉FSD v12是一个端到端AI”,到2024年3月特斯拉开始大范围推送v12,特斯拉端到端技术不断演进和成熟的过程,也是中国自动驾驶行业逐渐凝聚共识的过程。很多业内专家表示,公司下决心投入端到端自动驾驶,与特斯拉的进展密不可分。
1.2 用户体验驱动:端到端解决长尾场景的安全性和动态博弈的拟人化程度
第一是提升了系统的安全性。自动驾驶的很多长尾场景是“只可意会,不可言传”的,意即对于人类驾驶来说可以靠直觉“搞定”,但很难用规则化的语言来表述,这类问题是传统技术路径依赖的专家系统很难解决的。某自动驾驶芯片公司AI负责人提到,诸如“道路上一滩正在起火的油”与“道路上的积水”、“正面飘来的空塑料袋”和“前车落下的钢筋”这类需要常识推理的场景,以及“不同地区的不同红绿灯外观和路口等待规则”这类需要复杂环境理解能力的场景,要么很难用规则准确描述,要么其开发工程量太大(因为专家无法总结所有规律)。这类场景对于端到端系统来说,可以被训练为隐式的中间表示,从实践上表现出很强的应对能力。
第二是驾驶风格的拟人化。当前的自动驾驶功能在车道保持、定速巡航这类简单场景下的表现已经和人类司机相当,但是在拥堵跟车、加塞响应、变道超车等需要博弈的场景,其驾驶风格通常与乘客的预期不一致。究其原因,是因为基于规则的决策规划系统需要海量的工程优化才能报合出人类的高动态驾驶策略。相比之下,端到端系统能够表现得更像人类司机,这有利于自动驾驶系统与用户建立信任。
1.3 组织价值驱动:简化研发流程,优化组织效率
目前,大多数自动驾驶公司在量产落地阶段都会面临大量的研发人员投入的挑战。传统技术架构下ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









