







使用Mamba运动互补(MV-MOS): 多视角实现3D动态物体分割
Abstract
高效地总结稠密的3D点云数据并提取运动物体的运动信息(运动物体分割,MOS)对于自动驾驶和机器人应用至关重要。如何有效利用运动和语义特征并在3D到2D投影过程中避免信息丢失仍然是一个关键挑战。本文提出了一种新的多视角MOS模型(MV-MOS),通过融合来自点云不同2D表示的运动-语义特征来解决这一挑战。为了有效利用互补信息,所提出模型的运动分支结合了鸟瞰图(BEV)和距离视图(RV)表示中的运动特征。此外,还引入了一个语义分支,为运动物体提供补充的语义特征。最后,使用Mamba模块将语义特征与运动特征融合,为运动分支提供有效指导。通过全面的实验验证了所提出的多分支融合MOS框架的有效性,并且我们提出的模型在SemanticKITTI基准测试中优于现有的最先进模型。
代码地址:https://github.com/Chengjt1999/MV-MOS
Introduction
准确识别周围的运动物体对于自动驾驶和机器人应用至关重要,因为它直接影响系统的安全性和可靠性。此外,运动物体的属性和状态信息对于许多下游任务(如高精度地图构建、场景理解和决策制定)至关重要。3D MOS任务旨在通过分割感知到的LiDAR点云来区分运动物体和静态实体。
现有的多目标跟踪系统(MOS)模型主要分为两大类:基于3D体素的方法和基于2D投影的方法。3D体素方法将点云数据转换为3D网格,便于在空间中处理,但计算成本高,不利于实时应用。而2D投影方法通过将3D数据映射到2D视图,简化了卷积操作,但可能因信息丢失影响精度。例如,依赖距离视图或鸟瞰图(BEV)的模型可能因忽略物体的垂直信息而丢失关键的运动轮廓,导致误判。因此,如何在不同表示方式中有效结合运动和语义特征,是提升3D MOS模型性能的关键挑战。
为了解决这一挑战,我们提出了多视角特征融合MOS(MV-MOS),这是一种新的3D LiDAR MOS模型,具有双视角和多分支结构,以实现有效的特征融合。所提出的模型在使用3D点云的2D表示时,能够有效保留丰富且互补的运动和语义信息,同时利用成熟的2D神经网络模型进行轻量级和高效的特征处理。
3.Method
3.1 数据预处理
原始的LiDAR点云数据(x, y, z)首先被转换为范围视图(Range View,RV)和鸟瞰图(Bird’s Eye View,BEV)表示,以生成投影映射
![]()
和
![]()
其中
![]()
和
![]()
表示二维图像中的坐标,i表示点云数据的第i帧。
![]()
也将用作语义分支的输入
![]()
。
第k帧和第0帧的范围视图和鸟瞰图残差图表示如下公式:
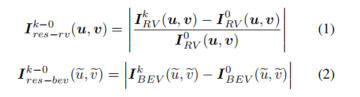
其中,
![]()
和
![]()
也将用作运动分支的输入和。为了提高鲁棒性,本文使用叠加帧表示
![]()
来替代上述公式中的
![]()
:
![]()
其中,
![]()
表示在k帧窗口内的所有高程信息。
由于范围视图
![]()
和鸟瞰图
![]()
的投影视图都源自于3D点云空间中的坐标(x, y, z),我们可以基于这一关系推导转换矩阵(记为Matrixr2b和Matrixb2r)。将范围视图表示
![]()
转换为鸟瞰图视图表示
![]()
可以通过以下公式简单实现:
![]()
使用公式1-3构建的BEV和RV残差图可以输入到所提出模型的运动和语义分支中,以进一步提取特征。
3.2 网络结构
1.基于多视图残差图融合的运动分支结构:由于UNet模型的轻量化设计,它可以减轻多分支网络引入的额外开销。因此,我们在UNet的骨干上构建了所提出的模型,如图2所示。所提出的运动焦点网络骨干由两个主要子分支组成,通过构建来自BEV视图和范围视图的两个残差图来提取运动特征。通过分析点云3D坐标系(x, y, z)的两个二维表示,可以得出BEV视图中的运动信息来自于
![]()
和的数值差异。相比之下,范围视图中的运动信息可以通过同一方位角和极角下深度值的差异来得出,以LiDAR为原点。两个二维视图表示的残差图从不同的角度捕捉了运动信息,且来自BEV和RV的信息相互补充。因此,所设计的MBR-MOS运动分支结合了这两个视角,以有效地实现互补信息的获取。为了构建输入的RV残差图,顺序使用循环卷积进行下采样,公式如下:
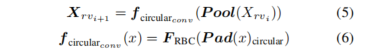
其中,
![]()
表示使用步幅为2的最大池化层进行下采样。
![]()
表示使用循环方法填充特征图。表示依次通过3x3卷积操作、批量归一化层和ReLU激活函数进行处理。
对于相同尺度的BEV残差图和RV残差图,通过公式4获得转换后的视图
![]()
。然后我们将它们融合,并利用多通道注意机制抑制无效信息,使网络仅关注重要表示。过程如下:
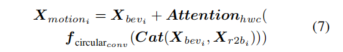
其中,Cat(·)表示沿通道维度连接特征图。Attention_{hwc}表示在通道和空间维度上执行注意力计算:
![]()
从上述运动分支过程获得的运动特征图
![]()
捕捉了来自两个视角的运动信息。这些特征图将被整合到后续与语义分支的特征交互和融合中,接下来的小节将描述这一过程。
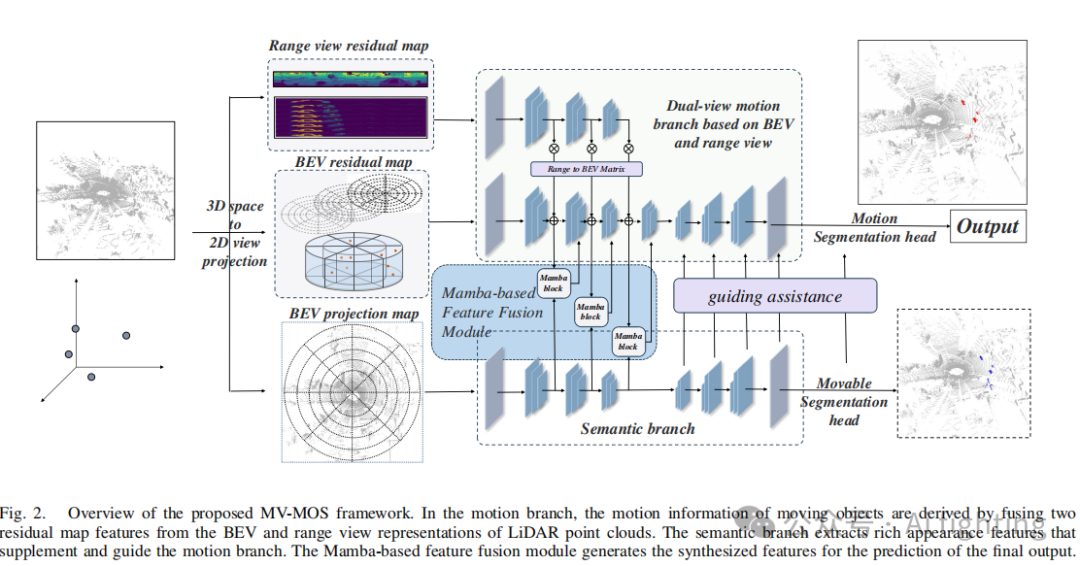
2.基于BEV视角投影的语义分支结构:所提出的语义分支在MV-MOS中有两个目的。首先,对于运动分支,残差图包含了物体运动状态的信息。因此,在骨干网络的下采样阶段,语义分支中的点云投影特征图为运动分支添加了丰富的物体外观语义信息,使得骨干网络对运动物体特征的提取更加准确。此过程公式如下:
![]()
其次,语义分支负责预测物体的可移动属性,并使用相同大小的语义特征图作为运动分支的指导,使得主要运动分支能够专注于检测可移动物体。此过程涉及两个步骤。首先,语义分支使用
![]()
的各种大小进行上采样:
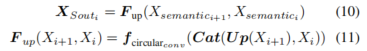
其中,Up(·)表示PixelShuffle上采样操作。最终预测输出
![]()
与物体的可移动标签一起用于计算损失以训练运动分支,并增强其辨别物体可移动性的能力。此外,语义分支上采样层的输出
![]()
与骨干网络输出的特征图
![]()
结合,为运动分支的上采样阶段提供指导。此过程公式如下:
![]()
最终输出不仅结合了来自双视图残差图的运动信息,还在下采样和上采样阶段分别整合了物体的语义信息。这样的设计有效增强了模型充分利用运动物体特征的能力。
3.密度感知自适应特征融合模块:在所提出的双分支运动-语义特征融合结构中,我们将运动流作为主要分支,语义信息作为辅助分支。所提出的融合模块依次对语义和运动信息输入进行空间和通道维度的注意力计算。通过这种方式,语义信息可以作为辅助激活运动特征图中的有效运动信息,同时补充在残差图计算中可能丢失的重要轮廓信息。此过程公式如下:
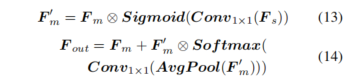
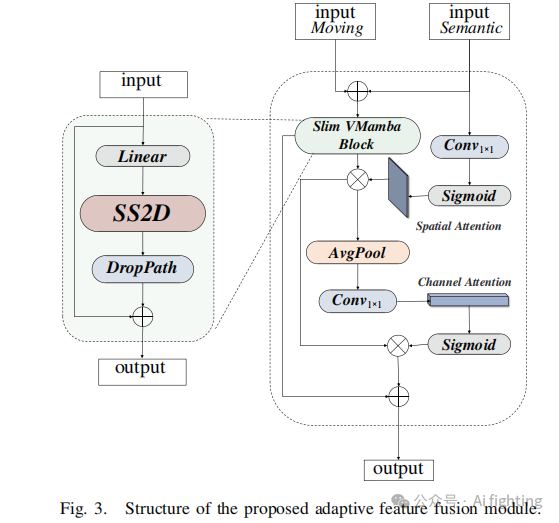
与语义特征图相比,从残差图中获得的运动特征图更加稀疏。因此,直接融合这两种类型的特征图会导致稠密的语义特征在合成特征中占主导地位,这可能会恶化最终的MOS性能,因为语义特征本应作为辅助信息。为了解决这种特征不平衡问题,我们设计了一种基于Mamba结构的自适应特征融合机制,该机制可以根据模型当前的输入动态调整其状态,并有选择地保留序列中的重要信息。考虑到当前的信息流是以2D图像表示的,由Vmamba提出的SS2D机制(包括扫描扩展、S6块和扫描合并)更适合应用于本工作。因此,我们引入了基于SS2D的Mamba机制,并将其嵌入到语义-运动双分支融合模块中,如图3所示:
![]()
其中,是由和 的连接得到的,
![]()
将替代公式(13)和(14)中的。通过这种方式,所提出的特征融合过程可以专注于关键元素,忽略无信息的冗余特征。
3.3损失函数
在训练过程中,我们引入了两组标签:运动物体和可移动物体,并分别训练运动分支和语义分支。总损失表示为:
![]()
其中,
![]()
和
![]()
分别代表移动物体和可移动物体的分割损失函数。
![]()
和
![]()
都由交叉熵损失函数LCE和 Lovász-Softmax 函数LLS组成,并结合相关标签进行计算:
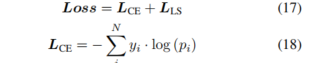
其中,𝑁是样本数,yi是第𝑖个样本的真实标签(0 或 1).pi是第𝑖个样本为正类的预测概率。Lovász-Softmax 损失定义为:
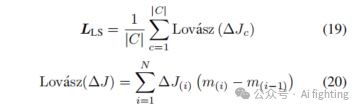
其中,∣C∣ 是多分类问题中类别的数量。是与类别𝑐相关的 Jaccard 损失子集,代表每个类别的 IoU 损失变化。
![]()
是在按预测误差概率降序排序后,第𝑖个样本的 IoU 损失变化。是排序后第𝑖个样本的累计误差。
Experiment
1.评估结果与对比
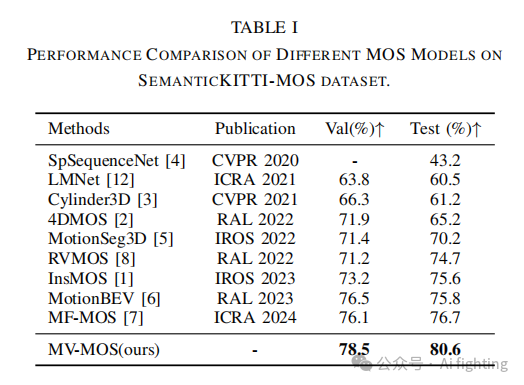
表I展示了MV-MOS与其他先进方法在MOS任务中的对比结果。可以看到,基准模型LMNet仅使用单一运动分支,在验证集上的准确率只有63.8%。相比之下,结合运动和语义分支的最新SOTA模型MotionBEV和MF-MOS的IoU值均超过76%,超越了基于体素的方法。这表明基于2D投影方法的模型具有显著潜力。我们提出的MV-MOS通过整合多种视角和分支来增强2D投影方法在从3D点云数据中捕捉运动信息的能力。所提出的MV-MOS在验证集上达到了78.5%的最高准确率,超过了所有其他基准MOS模型。此外,我们还在官方的SemanticKITTI-MOS基准服务器上测试了所提出的模型,结果显示,MV-MOS在所有开源模型中排名第一,IoU达到了80.6%。
2.消融研究
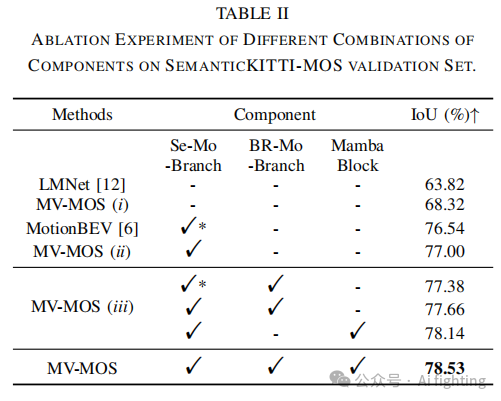
第一组实验评估了语义信息的益处。由结果(表II)可见,结合语义和运动分支的MV-MOS(ii)和MotionBEV的分割准确率比仅使用语义的LMNet和MV-MOS(i)高出约10%。此外,与基准模型MotionBEV相比,所提出的MV-MOS中的运动-语义多分支结构设计提供了辅助特征指导,使得IoU提高了近0.5%。
第二组实验旨在展示将RV和BEV视图残差分支组合到MV-MOS运动分支中(以下简称B(EV)R(ange View)-Motion-Branch)的有效性,以及自适应融合机制的作用。如表II所示,MV-MOS(iii)的第一行显示,将BR-Motion-Branch引入类似于MotionBEV的运动-语义双分支结构中,准确率从76.54%提高到77.38%。将BR-Motion-Branch引入MV-MOS(ii)后,准确率提高到77.66%。此外,在运动分支和语义分支之间的连接点引入我们提出的Mamba Block,准确率提高到78.14%,比MV-MOS(ii)提高了1.14%。
3.定性分析
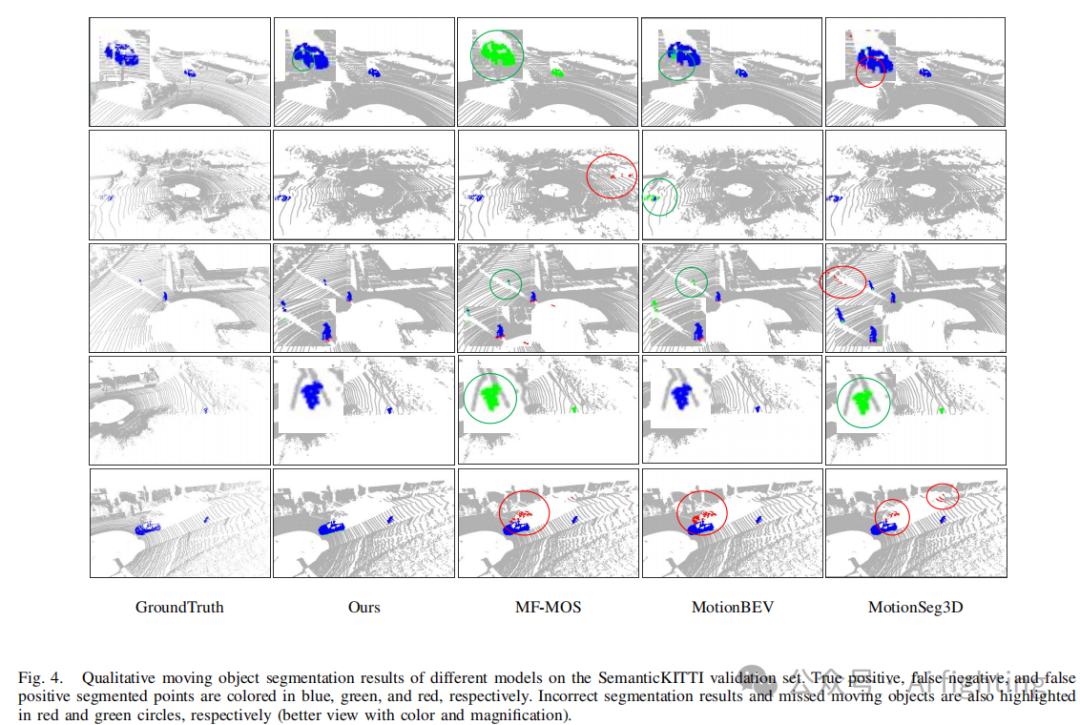
为了更直观地展示MV-MOS的有效性,我们通过可视化进行了定性分析。图4比较了MV-MOS与几个先进模型在SemanticKITTI验证集上的性能结果。如图所示,我们的模型正确推断了更多的点,物体的分割也更完整(由蓝色点表示)。
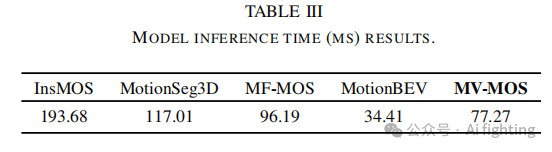
4.计算效率
如表III所示,我们将MV-MOS与过去两年的四个先进模型进行了比较。在推理时间方面,MV-MOS显著优于InsMOS 和MotionSeg3D ,并且比MF-MOS 提高了近20%。
结论
本研究的主要贡献总结如下:
1.设计了一个多分支结构,有效利用了来自点云的BEV和距离视图表示中的运动物体的运动特征。
2.提出了一种新的特征综合神经网络结构,全面利用运动和外观互补信息进行运动物体分割,有效生成丰富的语义引导的运动特征。此外,设计了一个基于Mamba的自适应特征融合框架,能够稳健地生成用于精确分割的最终特征,同时解决了融合过程中特征密度不均的问题。
3.所提出的方法在SemanticKITTI-MOS基准测试的验证集和测试集上分别达到了78.5%和80.6%的IoU,超越了最先进的开源MOS模型。
文章引用:
MV-MOS: Multi-View Feature Fusion for 3D Moving Object Segmentation
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术,关注我,一起学习自动驾驶感知技术。















 4557
4557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









