







夜间追踪数据集(LLOT):涵盖269个场景,13.2万帧数据
Abstract
近年来,随着大规模训练数据集的应用,视觉跟踪领域取得了显著进展。这些数据集支持了复杂算法的发展,提高了视觉物体跟踪的准确性和稳定性。然而,大多数研究主要集中在有利的光照环境下,忽视了低光照条件下的跟踪挑战。在低光照场景中,光线可能发生剧烈变化,目标可能缺乏明显的纹理特征,在某些情况下,目标甚至可能无法直接观察到。这些因素会导致跟踪性能严重下降。为了解决这一问题,我们引入了LLOT,这是一个专门为低光照物体跟踪设计的基准。LLOT包含了269个具有挑战性的序列,总共超过13.2万帧,每一帧都精心标注了边界框。这个特别设计的数据集旨在促进低光照条件下物体跟踪技术的创新与进步,解决现有基准未能充分覆盖的挑战。为了评估现有方法在LLOT上的表现,我们对39种最先进的跟踪算法进行了广泛的测试。结果显示,低光照跟踪性能存在显著差距。对此,我们提出了一种名为H-DCPT的新型跟踪器,该跟踪器结合了历史和黑暗线索提示,设立了一个更强的基准。在我们的实验中,H-DCPT超越了所有39种评估方法,展示了显著的改进。我们希望我们的基准和H-DCPT能够激发在低光照条件下跟踪物体的新颖且精确的方法的发展。
代码地址:https://github.com/OpenCodeGithub/H-DCPT
Introduction
视觉物体跟踪(VOT)是计算机视觉的基础任务,用于估计图像序列中目标的位置和尺度。这项技术广泛应用于视频监控、自动驾驶等领域。尽管物体跟踪技术已取得进展,但在低光照条件下的物体跟踪仍是一个挑战,因为这种环境下的图像通常具有高噪声、颜色失真、低对比度和低可见度等特点。
低光照条件下的物体跟踪对于提高交通监控、救援行动、野生动物观察和军事边境安全等领域的效率和安全性至关重要。例如,在交通监控中,低光照可能导致图像质量下降,影响车辆和行人的检测与跟踪。在救援行动中,无人机或机器人可能需要在低光照环境中导航和执行任务。在野生动物观察中,夜间活动频繁但光照条件差,需要低光照成像设备和跟踪算法来监测动物行为。在军事和边境安全领域,低光照物体跟踪技术可以增强夜间监控效果。
由于低光照环境带来的挑战,如光照变化和运动模糊,现有的主流跟踪算法在这些条件下表现不佳。因此,需要深入研究低光照环境中物体跟踪的特点,并设计专门的基准和优化算法来应对这些挑战。
新的基准数据集:LLOT
本节详细描述了LLOT的构建过程,包括低光视频的收集方法、注释程序和12个挑战属性。我们的目标是开发一个高质量的基准数据集,以供低光视觉目标跟踪研究使用。

A. 收集
与良好照明的视频相比,适合目标跟踪的低光视频资源在互联网上相对稀缺。因此,我们只在线上收集了少量的候选视频,并花费了大量时间和精力亲自拍摄了数百个候选视频。在对适合低光目标跟踪的视频进行排序和筛选时,我们要求视频具备以下五个基本特征:1) 足够的时长,以便评估算法的跟踪性能;2) 背景具有一定程度的变化,以模拟真实场景的复杂性;3) 目标具有足够的相对运动,以提供多样化的跟踪场景;4) 整个视频处于低光环境中;5) 跟踪目标不应占据图像的过大部分。在这些基本标准的基础上,我们特别关注包含额外挑战因素的视频序列。这些挑战可能包括部分遮挡、运动模糊、光照变化或尺度变化等。在收集、处理和标注视频数据后,我们最终为LLOT基准选择了269个序列。这些序列包括低光的室内和室外场景,涵盖了多种目标类别,包括人类(如跑步者、行人、篮球运动员、足球运动员)、动物(如狗、鸡)、刚性物体(如包、盆、篮球、自行车、垃圾桶、船、书、瓶子、扫帚、车、椅子、立方体、杯子、电动自行车、地球仪、指示牌、吹风机、鞋子、手提箱、旅游巴士、玩具、三轮车、卡车、伞)以及人类与车辆的组合(如人&自行车、人&电动自行车)。图1展示了LLOT数据集中低光场景的样本图像。

B. 注释
LLOT中的所有帧都由熟悉目标跟踪的专业人员手动注释。鉴于许多图像难以凭肉眼识别,我们在注释前先对原始图像应用低光图像增强。为了获得高质量的低光增强图像,我们比较了五种最新的低光增强算法:PairLIE 、EnlightGAN、GSAD、URetinex 和SCI 。比较表明,SCI方法在处理LLOT数据集时整体上表现出显著优势:增强后的图像显示出更清晰的目标边缘轮廓;图像噪点相对较少;增强效果更接近于人类的自然视觉感知。图3展示了这些算法的视觉比较示例。此外,SCI处理的图像不会消耗过多的内存,这对于实际应用尤为重要。综合考虑这些因素,SCI算法在视觉质量和实用性方面均显示出明显优势,使其成为LLOT数据集预处理的最佳选择。我们的注释过程遵循[67]中提出的指南,并涉及两个主要方面:注释可见目标和标记遮挡情况。当目标可见时,沿坐标轴绘制或编辑每个序列中的每一帧的边界框,从给定的初始目标开始,确保边框紧紧包围目标的所有可见部分。当目标不可见时,将其标记为视野外(OV)、部分遮挡(POC)或完全遮挡(FOC)。为了确保LLOT的高质量和可靠性,我们采用了严格的三步注释过程。首先,每个视频由专业人员(从事视觉跟踪研究的学生)进行初步注释。然后,验证团队对这些初步注释进行了全面的视觉检查,重点关注其准确性和一致性。最后,验证团队对有争议的注释返回原始注释者进行边界框的修正和精炼。这种注释方法不仅提高了LLOT的整体质量,还确保了注释的一致性和准确性。图4显示了LLOT中的框注释示例。

C. 属性
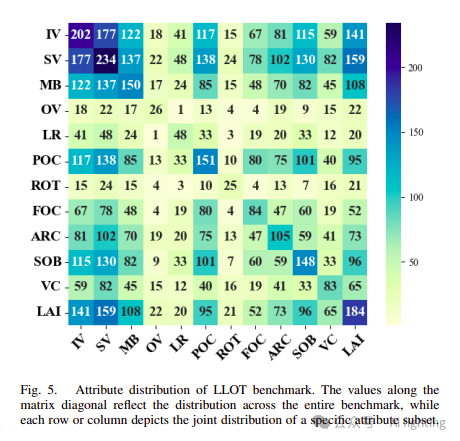
为了进一步分析跟踪性能,LLOT为每个序列提供了11个常见属性:光照变化(IV)、尺度变化(SV)、运动模糊(MB)、视野外(OV)、部分遮挡(POC)、旋转(ROT)、完全遮挡(FOC)、视角变化(VC)、相似物体(SOB)、纵横比变化(ARC)和低分辨率(LR)。此外,还有一个与低光条件相关的属性——低环境强度(LAI)。表I详细说明了每个属性的定义。值得注意的是,ARC、SV、LR和LAI属性是根据目标的注释结果计算的,而其余属性则是手动标注的。总的来说,图5展示了各属性之间关系的热图。经常一起出现的属性对用较深的颜色表示,而不常见的组合则用较浅的颜色表示。矩阵对角线上的值特别反映了整个基准的分布情况,而每行或每列则描述了特定属性子集的联合分布。我们观察到,IV、SV和LAI在LLOT数据集中最为常见。紧随其后的是MB、POC和SOB,这些属性的出现频率也相对较高。其中,IV、SV、MB、POC和SOB是传统跟踪任务中的常见挑战,而LAI则是[53]中专门设计的新属性,用于研究光照对跟踪器的影响。

新的基准方法:H-DCPT
在我们的评估中,我们发现HIPTrack 通过利用精确且更新的历史提示信息显著提高了跟踪性能,在LLOT数据集上表现优于其他最先进的跟踪器。然而,HIPTrack的性能仍有进一步提升的空间,因为它并未专门应对低光环境的独特挑战。另一方面,DCPT 是为夜间场景设计的最先进的跟踪器,通过黑暗提示(DCP)提高了其在低光环境下的表现。然而,它未能充分利用前几帧中的重要目标信息,导致在LLOT数据集上的整体性能不佳。基于这些观察,我们提出了一种创新的方法来整合这两个跟踪器的优势。
A. 整体架构
H-DCPT基于HIPTrack的基本架构,由三个核心组件组成,如图6(a)所示。H-DCPT中的特征提取网络有两个主要功能:1) 从搜索区域提取目标模板匹配信息,同时有效地过滤掉背景干扰;2) H-DCPT在特征提取网络中引入了一个专门为低光环境设计的DCP模块。通过整合黑暗提示技术,H-DCPT显著增强了其在低光条件下的特征表示能力,同时保留了处理历史提示信息的能力。历史提示网络由历史提示编码器和解码器组成。编码器将当前的目标状态转换为历史特征以供存储,而解码器利用这些信息生成对应的历史提示用于搜索区域,随后与压缩特征融合。H-DCPT保留了HIPTrack的头部网络结构。H-DCPT与HIPTrack的区别在于它们的特征提取网络。HIPTrack采用了一个包含早期候选消除模块的视觉变换器(ViT)架构,类似于OSTrack [52]中使用的方法,作为其特征编码器。相反,我们的H-DCPT引入了一种新的聚合编码器,如图6(b)所示,它通过门控特征聚合(GFA)机制自适应地聚合黑暗提示和基础特征。通过这一设计,H-DCPT有效结合了HIPTrack利用历史提示信息的优势与DCPT [14] 适应低光条件的能力,实现了在各种光照环境下的高效跟踪,尤其在低光环境中表现出色。在接下来的部分中,我们详细介绍了所提出的DCP编码器。
B. DCP编码器
我们基于HIPTrack的变换器架构开发了DCP编码器。具体而言,它采用了视觉变换器(ViT)框架,并额外引入了早期候选消除模块。该结构由堆叠的CEBlocks组成,如图6(b)所示。主要区别在于增加了DCP模块和门控特征聚合(GFA)策略。具体而言,我们在每个CEBlock之前放置了一个独立的DCP模块。这些模块计算并生成黑暗提示信息。随后,类似于DCPT,我们的编码器利用GFA机制动态调整CEBlocks生成的特征与黑暗提示之间的权重组合。这种设计使得模型能够更灵活地整合来自不同来源的信息,从而显著提升其在低光条件下的性能。
注入到第i层特征门中的黑暗提示的计算过程可以表示为:
[ P_i = (G_i)Φ(H_{i-1}) + (1 - G_i)P_{i-1}, ]
其中,Φ表示DCP提取操作,(H_{i-1}) 是第i层的模板和搜索特征的拼接。门控权重(G_i) 控制当前和之前提示的组合。所提出的DCP编码器的效果可以形式化为:
[ F_{ha} = H_{xn} + ρ_nP_n, ]
其中,(H_{xn} = CBlock_n(H_{n-1}), ) 门控聚合权重(ρ_n) 代表第n层黑暗提示的不同注意力权重。
Experiments
在本研究中,我们采用了三种广泛使用的定量指标来评估跟踪器的性能:成功率(SAUC)、精度(P)和归一化精度(PNorm)。使用标准的一次通过评估(OPE)协议 ,我们在269个序列上测量了这些指标。S 基于边界框的重叠来评估性能。重叠分数定义为 S = |Btr∩Bgt| / |Btr∪Bgt|,其中 Btr 是跟踪结果,Bgt 是地面真值,衡量跨越 0 到 1 重叠阈值的成功帧的比例。使用特定阈值(例如 τ = 0.5)处的单一成功率值来评估跟踪器可能不公平或不具代表性。因此,我们通过曲线下面积(AUC)排名总体性能,称为 SAUC,这提供了跨所有阈值的更全面评估。P = ||Ctr − Cgt|| 通过测量跟踪结果(Ctr)和地面真值目标标注(Cgt)之间的欧几里得距离来评估跟踪精度。为了减轻跟踪器在丢失目标时的潜在偏差,我们使用 20 像素距离阈值,遵循已建立的做法 [104]。而 PNorm 是一种尺度不变的指标,它相对于地面真值大小对精度进行归一化,公式为 PNorm = ||diag(Btr, Bgt)(Ctr − Cgt)||。该指标在不同的对象大小和尺度下特别稳健,并使用在 0 到 0.5 之间计算的 AUC 来对跟踪器进行排名。这些指标共同提供了全面的评估,使不同的跟踪算法能够进行准确的比较和评估。
A. 比较的跟踪器
我们对 H-DCPT 及其 39 种顶尖跟踪算法在 LLOT 数据集上的性能进行了评估。这些跟踪算法被划分为两大类:24 种基于深度学习(DL-based)的跟踪算法和 15 种基于相关滤波(DCF-based)的跟踪算法。具体来说,DL-based 跟踪算法涵盖了 HIPTrack、ProContEXT、ARTrack、DropTrack、AQATrack、ROMTrack、DCPT、OStrack、GRM、Stark、SeqTrack、ZoomTrack、SimTrack、CSWinTT、Aba-ViTrack、UDAT、SiamGAT、AVTrack、SAM-DA、ETTrack、JointNLT、HiFT、TCTrack 和 SiamAPN++。而 DCF-based 跟踪算法则包括了 STRCF、SRDCFdecon、SRDCF、BACF、ECO-HC、ARCF、AutoTrack、Staple CA、Staple、DSST、KCC、SAMF、fDSST、KCF 和 SAMF CA。值得注意的是,DCF-based 跟踪算法的代码库均来源于官方。为确保评估过程的一致性和公正性,我们采用了所有跟踪算法作者提供的原始代码实现,包括他们推荐的预训练模型和参数配置。通过这一全面的对比分析,我们得以在充满挑战的 LLOT 环境中,验证我们提出的 H-DCPT 算法与其他现代跟踪算法相比的有效性。
B. 评估结果
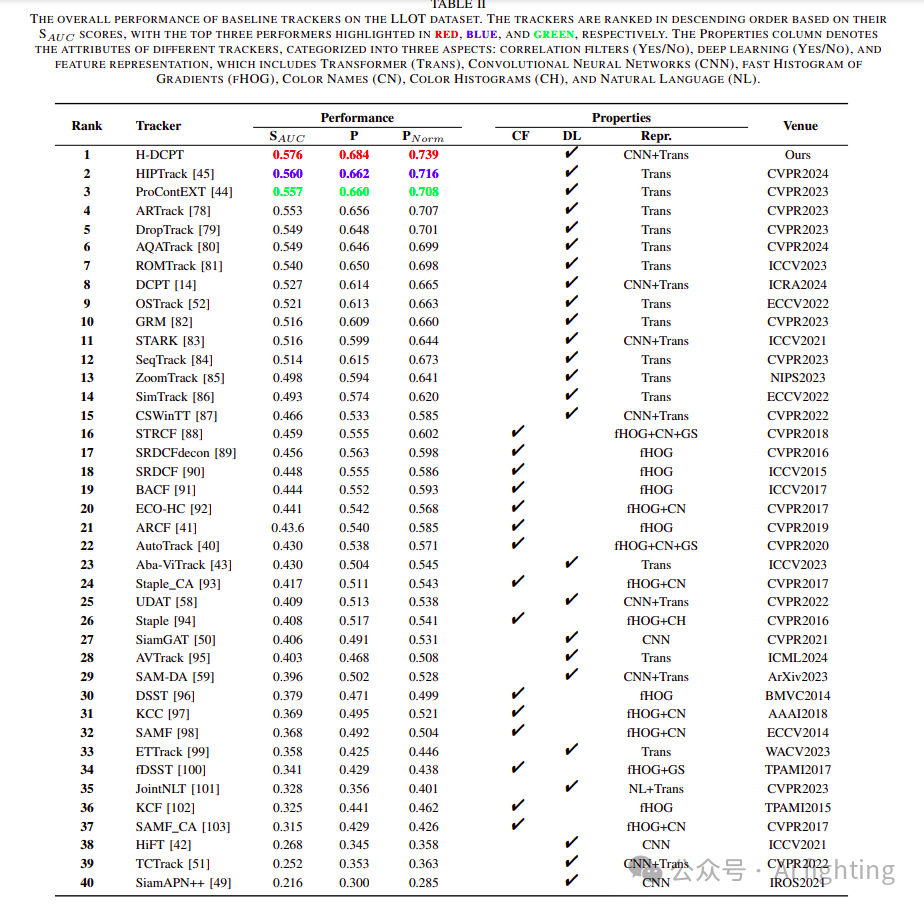
在 LLOT 数据集上,我们对包括我们的 H-DCPT 在内的 39 种顶尖跟踪算法进行了全面的评估。表 II 汇总了这些跟踪算法的评估结果,并根据它们的 SAUC 分数进行了排序。大体来看,排名靠前的 15 种算法均采用了基于深度学习(DL-based)的方法。排名中等的算法则展现了方法的多样性,既有基于相关滤波(DCF-based)的,也有基于深度学习的。引人注意的是,排名垫底的三种算法同样是基于深度学习的。这表明,在低光照条件下进行目标跟踪时,DL-based 方法通常具有明显的优势,因为它们在特征提取和表示方面的强大能力使得它们能够更好地适应复杂的低光照环境。
例如,在所有 40 种评估的跟踪算法中,包括 39 种现有的先进算法和新提出的 H-DCPT,实验结果显示 H-DCPT、HIPTrack 和 ProContEXT 位列前三。尽管 HIPTrack 和 ProContEXT 主要依赖于 Transformer 架构来进行特征表示,H-DCPT 却通过结合 Transformer 和 CNN 的混合方法而脱颖而出。H-DCPT 在 SAUC、P 和 PNorm 三项指标上分别以 0.576、0.684 和 0.739 的得分位居榜首,分别比排名第二的 HIPTrack 高出 1.6%、2.2% 和 2.3%。HIPTrack 以 0.560、0.662 和 0.716 的得分位列第二。ProContEXT 紧随其后,得分为 0.557、0.660 和 0.708。
然而,一些在日间数据集上表现出色的 DL-based 算法在 LLOT 基准测试中并未超过某些 DCF-based 跟踪器。在仅使用手工特征的传统跟踪器中,STRCF、SRDCFdecon、SRDCF、BACF 和 ECO-HC 在性能评估中排名前五。值得注意的是,尽管这些方法没有采用深度学习特征,但它们在整体性能上与一些 DL-based 跟踪器相当,甚至在三个评估指标上超过了专门为夜间跟踪设计的跟踪器,如 UDAT 和 SAM-DA。
在评估的 39 种顶尖跟踪器中,DL-based 算法 HiFT、TCTrack 和 SiamAPN++ 在 LLOT 低光照数据集上的表现相对较差。具体来说,HiFT 在成功率(SAUC)、精度(P)和归一化精度(PNorm)上的得分分别为 0.268、0.345 和 0.358。TCTrack 在相同指标上的得分为 0.252、0.353 和 0.363。SiamAPN++ 的表现最差,得分仅为 0.216、0.300 和 0.285。这种情况的一个可能原因是,这三个跟踪器都是为了无人机场景设计的。为了保持实时跟踪能力,这些算法可能在复杂的光照条件下牺牲了一定的鲁棒性,这可能是它们在低光照环境中表现不佳的原因。

综上所述,实验结果表明H-DCPT在成功率(SAUC)、精度(P)和归一化精度(PNorm)方面表现优异。这证实了H-DCPT通过整合暗提示和历史提示信息,在应对低光照目标跟踪挑战方面表现出显著的有效性,与现有的最先进跟踪器相比表现更好。这些发现还揭示了一个关键问题:以往的跟踪方法主要关注在光照充足的场景中实现稳健的跟踪,而忽视了在低光照环境中的表现。在这些更复杂和苛刻的条件下,这些跟踪器往往面临性能下降甚至失败的风险。随着对低光照跟踪需求的增加,这一领域的研究和创新将变得越来越重要。开发能够在各种光照条件下保持高性能的鲁棒跟踪算法将成为计算机视觉和目标跟踪领域的一个关键挑战和机遇。
属性基础的性能:
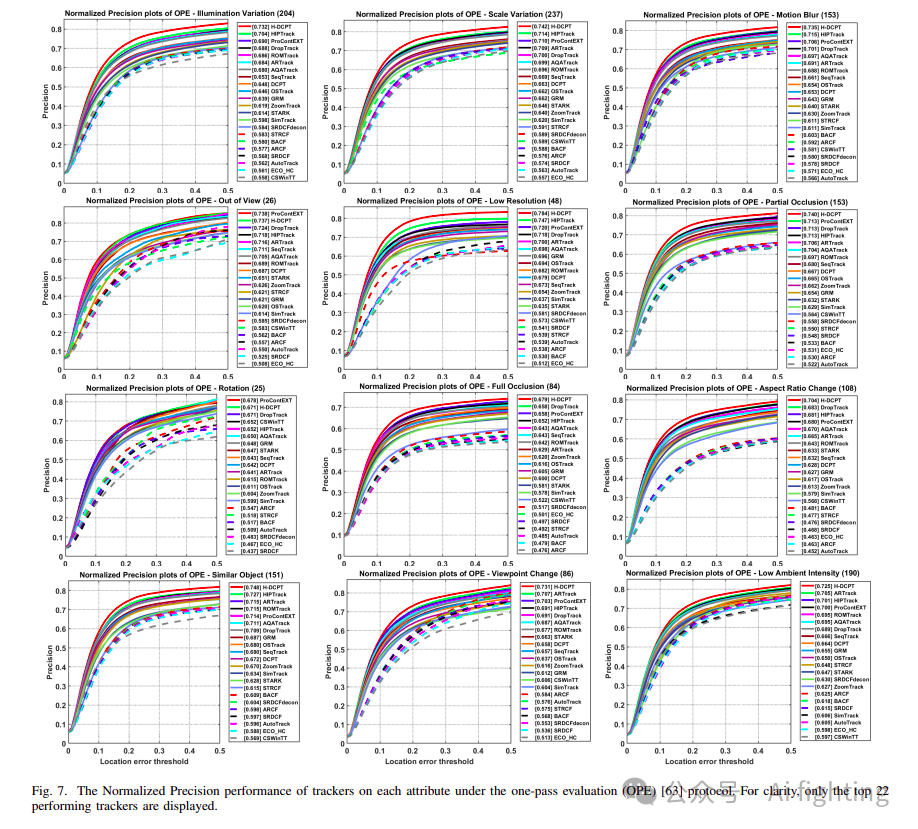
为了深入探究各跟踪器在 LLOT 数据集上的性能,我们对 12 个属性进行了全面的评估。图 7 展示了在单次通过评估(One-Pass Evaluation, OPE)协议下,各跟踪器的归一化精度(PNorm)表现。为了增强图表的清晰度,图中仅展示了排名前 22 的跟踪器,这包括了 21 种尖端跟踪器,如 HIPTrack、ProContEXT、DropTrack、ROMTrack、ARTrack、AQATrack、SeqTrack、DCPT、OStrack、GRM、ZoomTrack、Stark、SimTrack、CSWinTT、STRCF、SRDCFdecon、SRDCF、BACF 等。
C. 消融研究
可视化。如图 9 所示,我们展示了 H-DCPT 及其基线模型 HIPTrack 的置信度图。在低光照环境下,基线模型难以在不利的光照条件下有效地聚焦于物体。相比之下,H-DCPT 显著增强了基线模型在夜间的感知能力,从而在低光照场景中实现了令人满意的跟踪性能。H-DCPT 的优越性能可以归因于其创新性地整合了黑暗线索提示和历史提示信息,这使得在低光照场景中能够更加稳健地表示特征。这些结果强调了我们提出的方法在解决低光照目标跟踪挑战中的有效性。

黑暗线索提示模块层数的影响:为了研究 H-DCPT 在 LLOT 数据集上的性能受黑暗线索提示模块层数的影响,我们逐步将该模块的层数从 1 增加到 12,并观察其对跟踪器性能的影响。实验结果呈现在表 III 中。从表中可以看出,随着层数的增加,黑暗线索提示模块的贡献逐渐增强,导致 H-DCPT 的 SAUC、P 和 PNorm 指标整体呈上升趋势。这一发现表明,增加黑暗线索提示模块的层数可以有效提高 H-DCPT 在低光照条件下的跟踪性能,证明了将黑暗线索提示与历史提示信息结合的有效性。然而,我们也观察到,当层数达到一定数量后,SAUC 的提升趋势趋于平稳。值得注意的是,当层数为 12 时,H-DCPT 达到了最佳性能,SAUC、P 和 PNorm 的值分别为 0.576、0.684 和 0.739。基于这些结果,我们选择 12 层作为 H-DCPT 的默认配置。
总结:
本文的主要贡献如下:
-
引入了LLOT(低光照物体跟踪),这是第一个专门为低光照条件下的通用物体跟踪设计的综合基准。LLOT数据集包含269个精心标注的室内外视频序列,涵盖32个物体类别。这个综合数据集旨在推进低光照物体跟踪的研究和应用。
-
对39种最先进的跟踪算法进行了全面评估。此评估突显了当前跟踪算法的局限性,建立了新的性能基准,并激励了未来在低光照物体跟踪领域的研究努力。
-
提出了一种新颖的跟踪器H-DCPT,该跟踪器巧妙地结合了历史和黑暗线索提示以提高性能。H-DCPT在LLOT上表现优于现有的最先进跟踪器,为未来的低光照物体跟踪研究提供了更强的基准。
引用文章
Low-Light Object Tracking: A Benchmark
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
关注我的公众号auto_driver_ai(Ai fighting), 第一时间获取更新内容。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术,关注我,一起学习自动驾驶感知技术。

















 2348
2348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









