







最近看了百度的Deep Speech,看到语音识别使用的损失函数是CTC loss。便整理了一下有关于CTC loss的一些定义和推导。由于个人水平有限,如果文章有错误,还恳请各位指出,万分感谢~
附上我的github主页,欢迎各位的follow~~~献出小星星~
1. 背景介绍
在传统的语音识别的模型中,我们对语音模型进行训练之前,往往都要将文本与语音进行严格的对齐操作。这样就有两点不太好:
- 严格对齐要花费人力、时间。
- 严格对齐之后,模型预测出的label只是局部分类的结果,而无法给出整个序列的输出结果,往往要对预测出的label做一些后处理才可以得到我们最终想要的结果。
虽然现在已经有了一些比较成熟的开源对齐工具供大家使用,但是随着deep learning越来越火,有人就会想,能不能让我们的网络自己去学习对齐方式呢?因此CTC(Connectionist temporal classification)就应运而生啦。
想一想,为什么CTC就不需要去对齐语音和文本呢?因为CTC它允许我们的神经网络在任意一个时间段预测label,只有一个要求:就是输出的序列顺序只要是正确的就ok啦~这样我们就不在需要让文本和语音严格对齐了,而且CTC输出的是整个序列标签,因此也不需要我们再去做一些后处理操作。
对一段音频使用CTC和使用文本对齐的例子如下图所示:
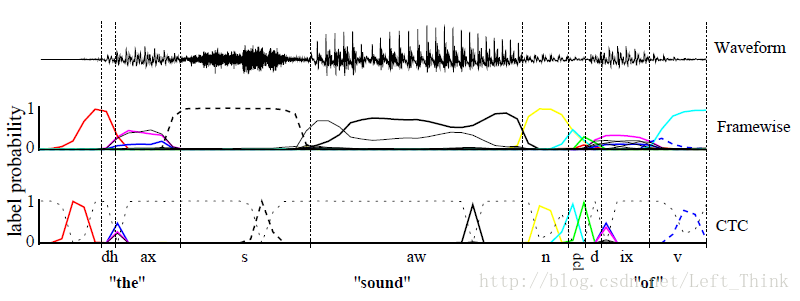
2. 从输出到标签
2.1符号的表示
接下来,我们要对一些符号的定义进行介绍。由于水平有限,看这部分定义介绍的时候绕在里面很久,可能有些理解有误,还恳请各位大大及时指出~
ytk :代表输出序列在第t步的输出为k的概率。举个简单的例子:当输出的序列为(a-ab-)时, y3a 代表了在第3步输出的字母为a的概率;
p(π∣x) :代表了给定输入x,输出路径为 π 的概率;
由于假设在每一个时间步输出的label的概率都是相互独立的,那么 p(π∣x) 用公式来表示为 p(π∣x)=∏Tt=1(ytk) ,可以理解为每一个时间步输出路径 π 的相应label的概率的乘积。
F :代表一种多对一的映射,将输出路径 π 映射到 标签序列 l 的一种变换
举个简单的例子
F(a−ab−)=F(−aa−−abb)=aab (其中-代表了空格)p(l∣x) :代表给定输入x,输出为序列 l 的概率。
因此输出的序列为
l 的概率可以表示为所有输出的路径 π 映射后的序列为 l 的概率之和,用公式表示为p(l∣x)=∑π∈F−1(l)p(π∣x)
2.2 空格的作用
在最开始的CTC设定中是没有空格的, F 只是简单的移除了连续的相同字母。但是这样会产生两个问题:
- 无法预测出连续两个相同的字母的单词了,比如说hello这个单词,在CTC中会删除掉连续相同的字母,因此CTC最后预测出的label应该是helo;
- 无法预测出一句完整的话,而只能预测单个的单词。因为缺乏空格,CTC无法表示出单词与单词之间停顿的部分,因此只能预测出单个单词,或者将一句话中的单词全部连接起来了;
因此,空格在CTC中的作用还是十分重要的。
3. 前向传播与反向传播
3.1前向传播
在对符号做了一些定义之后,我们接下来看看CTC的前向传播的过程。我们前向传播就是要去计算
p(l∣x)
。由于一个序列
l
通常可以有多条路径经过映射后得到,而随着序列
有一种类似于HMM的前向传播的算法可以帮助我们来解决这个问题。它的key就是那些与序列 l 对应的路径概率都可以通过迭代来计算得出。
在进行计算之前,我们需要对序列
对于一个特定的序列
l
,我们定义前向变量
其中,
V(t,u)={π∈A′t:F(π)=l1:u/2,πt=l′u}
代表了所有满足经过
F
映射之后为序列
l
,长度为t的路径集合,且在第t时间步的输出为label:
所有正确路径的开头必须是空格或者label
l1
,因此存在着初始化的约束条件:
α(1,2)=y1l1
α(1,u)=0,∀u>2
也就是当路径长度为1时,它只可能对应到空格或者序列
l
的第一个label,不可能对应到序列
因此,
p(l∣x)
可以由前向变量来表示,即为
其中
α(T,U′)
可以理解为所有路径长度为T,经过
F
映射之后为序列
l
,且第T时刻的输出的label为:
怎么去理解它呢?我们不妨先看看它的递归图
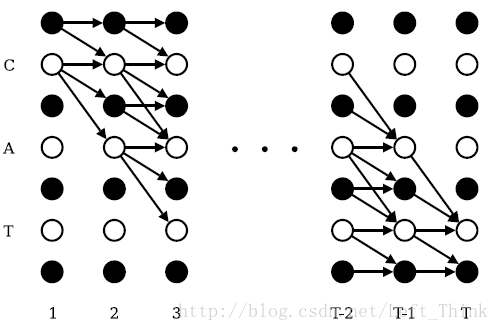
上图中,白色的点表示一个label,黑色的点表示空格,纵向每一列表示的是路径的长度T(或者时刻T?),箭头代表了路径下一个时刻可以输出到哪个label去。如果在时刻 1 的 label 为空格,那么路径在下一时刻只有两个选择,第一个还是输出空格,第二个就是输出序列 l 中对应的空格的下一个label:C;如果在时刻2的 label 为 C,那么在时刻3,它可以有三种选择:第一种就是输出还是 C,第二种是输出为空格,第三种是直接输出A。
从上图可以看出长度为T的输出路径映射到序列
现在我们要来引出它的递推公式啦,具体公式如下所示:
其中
如何理解这个递推公式呢,很简单,我们可以看上面递推图,就以时刻T为空格的前向变量为例,由于我们之前讲过了如果当前时刻的输出为空格,下一时刻路径输出只有两种可能性,而如果我们当前时刻是空格,上一时刻的输出从图中可以看出也是由两种可能性,一种是在T-1时刻输出为空格,另外一种是在T-1时刻输出为T。因此我们只要计算出T-1时刻输出为空格的所有正确路径的概率之和以及在T-1时刻输出为T的所有路径的概率之和,再乘上T时刻输出为空格的概率 yTl′u ,就可以得到前向变量 α(t,u) 啦。时刻T为label:T的前向变量的求法和空格的类似,只是它由三种可能情况求和再乘上 yTl′u 得到的。
3.2反向传播
与前向传播类似,我们首先定义一个反向变量
β(t,u)
,它的含义是从t+1时刻开始,在前向变量
α(t,u)
上添加路径
π′
,使得最后通过
F
映射之后为序列
l
的概率之和,用公式表示为:
其中 W(t,u)={π∈A′T−t:F(π′+π)=l,∀π′∈V(t,u)}
按照前向传播的图举例说明:假设我们在T-2时刻路径输出为label:A,那么此时的反向变量的求法就是在T-2时刻开始,所有能到达T时刻输出为空格或者label:T的“剩余”路径 π′ 的概率之和。
反向传播也有相对应的初始化条件:
β(T,u′)=0,∀u′<U′−1
它的递推公式如下所示
其中
3.3对数运算
不论是在计算前向变量还是反向变量时,都涉及到了大量的概率的乘积。由于这些乘积都是小于1的,在大量的小数相乘时,最后得到的结果往往都会趋向于0,更严重的是产生underflow。因此在计算时对其做了取对数的处理,这样乘法就会转化为加法了,不仅避免了underflow,还简化了计算。但是,原来的加法计算就不是太方便了。不过这里有一个数学的trick:
4.损失函数
CTC的损失函数定义如下所示
其中 p(z|x) 代表给定输入x,输出序列 z 的概率,S为训练集。损失函数可以解释为:给定样本后输出正确label的概率的乘积(这里个人不理解为啥要做乘积运算,求和的话不应该好解释一点么?可能是因为要取对数运算,求和可能不太方便,所以是做乘积运算),再取负对数就是损失函数了。取负号之后我们通过最小化损失函数,就可以使输出正确的label的概率达到最大了。
由于上述定义的损失函数是可微的,因此我们可以求出它对每一个权重的导数,然后就可以使用什么梯度下降、Adam之类的算法来进行优化求解啦~
下面我们就要把上一节定义的前向变量与反向变量用到我们的损失函数中去,让序列
而
p(π∣x)=∏Tt=1(ytk)
,因此进一步转化可以得到
因此,对于任意的时刻t,我们给定输入x,输出序列
z
的概率可以表示成
也就是在任意一个时刻分开,前向变量与反向变量的乘积为在该时刻经过label: l′u 的所有概率之和,然后再遍历了序列 l′ 的每一个label,因此就得到了所有输出为序列 l′ 的概率之和。
损失函数就可以进一步转化为
4.1损失函数梯度计算
损失函数关于网络输出
ytk
的偏导数为:
而
p(z∣x)=∑|z′|u=1α(t,u)β(t,u)=∑π∈X(t,u)∏Tt=1ytπt
,我们记label:k出现在序列
z′
的所有路径的集合为
B(z,k)={u:z′u=k}
,因此可以得出
因此损失函数关于输出的偏导数可以写为
最后,我们可以通过链式法则,得到损失函数对未经过sofmax层的网络输出的
atk
的偏导数:
又有
因此可以得到损失函数对未经过sofmax层的网络输出的
atk
的偏导数:
5.参考文献
1.《Supervised Sequence Labelling with Recurrent Neural Networks》 chapter7















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









