







城市空间结构,主要被定义为就业和居住地的空间分布。本次我们给大家带来一篇SCI论文的全文翻译。该论文提出了一种非参数方法,该方法结合了Jenks自然断裂法和Moran’s I,以利用兴趣点密度来识别城市的多中心结构。
【论文题目】
Identifying subcenters with a nonparametric method and ubiquitous point-of-interestdata: A case study of 284 Chinese cities
【题目翻译】
基于非参数方法和无所不在的兴趣点数据的子中心识别——以284个中国城市为例
【期刊信息】
Computers, Environment and Urban Systems;Volume 49, Issue 1, March 1, 2021
【作者信息】
Ying Long,建筑学院和恒隆房地产中心,生态规划与绿色建筑重点实验室, 教育部,清华大学, 中
Yimeng Song,土地测量和地理信息学系, 香港理工大学;智慧城市研究所, 香港理工大学, 香港, 中国
Long Chen,清华大学,中国
【关键词】
城市空间结构,子中心,兴趣点,中国。
【本文亮点】
- 提出了一种非参数方法,该方法结合了Jenks自然断裂法和Moran’s I,以利用兴趣点密度来识别城市的多中心结构
- 以中国城市为研究对象,最终在中国284个地级市中识别出了70个具有多中心结构的城市,进行回归分析以揭示这些城市多中心性的预测因素
- 回归结果表明,城市的总人口、GDP、平均工资和城市土地面积均显著预测多中心性
- 提供了一种识别城市中主要中心和子中心的替代性和可转移的方法,并揭示了多中心性的共同预测因素
- 避免了传统方法中可能出现的一些问题,例如阈值设置的任意性和对空间尺度的敏感性
- 由于输入数据(如兴趣点数据)广泛公开且其有效性可以通过实地考察或其他传统数据源(如土地利用图或人口普查)高效检验
【摘要】
城市空间结构,主要被定义为就业和居住地的空间分布,一直以来都是城市经济学家、地理学家和规划师们持续关注的焦点,这并非没有道理。本文提出了一种非参数方法,该方法结合了Jenks自然断裂法和Moran’s I,以利用兴趣点密度来识别城市的多中心结构。具体来说,一个多中心城市由一个主中心和至少一个子中心组成。一个合格的(子)中心应该在其周边地区中具有显著更高的人类活动密度(局部高密度),并且其密度相对整个城市的其他子区域而言也更高(全局高密度)。以中国城市为研究对象,我们最终在中国284个地级市中识别出了70个具有多中心结构的城市。此外,还进行了回归分析,以揭示这些城市多中心性的预测因素。回归结果表明,城市的总人口、GDP、平均工资和城市土地面积均显著预测多中心性。总的来说,本文提供了一种识别城市中主要中心和子中心的替代性和可转移的方法,并揭示了多中心性的共同预测因素。该方法避免了传统方法中可能出现的一些问题,例如阈值设置的任意性和对空间尺度的敏感性。由于输入数据(如兴趣点数据)广泛公开且其有效性可以通过实地考察或其他传统数据源(如土地利用图或人口普查)高效检验,该方法也可以相当方便地复制。
【引言】
城市空间结构,主要定义为就业和居住地的空间分布,一直以来都是城市经济学家、地理学家和规划师们关注的重点,这是有充分理由的。一方面,紧凑的城市形态(即高就业和居住集中度)或城市蔓延(即紧凑城市形态的反面)意味着城市面临不同的利益和成本。另一方面,去中心化和多中心形态,即存在多个集中的就业中心和分散的人口分布,逐渐成为越来越多城市的常态,而不是例外。例如,在美国,已经出现了“边缘城市”甚至“超多中心”地区(Garreau,1992;Gordon和Richardson,1996)。这些新现象对经济、社会、能源和环境产生了深远影响,并揭示了治理城市或地区的基本动态正在发生巨大变化。因此,学术界和实践者都需要更多的研究来更好地理解这些变化;这种理解已成为我们更好地规划和管理城市和区域形态与发展的前提条件。
现有研究在理解城市空间结构变化方面取得了进展,基本上是通过定义和识别城市子中心来实现的。然而,定量测量多中心性的研究主要集中在以下几方面:(a)需要本地知识或多步计算的测量方法,如密度阈值选择和密度函数与残差的计算;(b)使用传统的人口或就业数据,这些数据通常来自人口普查和家庭出行调查,更新周期为5年或10年,严重滞后于城市和区域的快速发展和不断变化;(c)同时只关注一个或少数几个城市,如洛杉矶(例如Giuliano和Small,1991;Pfister等,2000)、芝加哥(例如McDonald,1987;McMillen和McDonald,1998)、休斯顿(例如Craig和Ng,2001;McMillen,2001)、北京(例如Huang等,2015;Qin和Han,2013;Sun等,2012;Cai等,2017)、杭州(例如Wen和Tao,2015;Yue等,2010)和广州(例如Wu,1998)。上述限制对准确描述不断变化的城市空间结构构成了挑战,缺乏可比案例也削弱了我们探索城市系统中影响多中心性的因素的能力。
在过去十年中,新型、开放和大数据(NOBD)的概念被提出并迅速发展,这也为城市研究带来了机会。大多数NOBD代表了通过新型(传感器)技术和新型社交媒体实时收集的海量数据流。例如,Long和Thill(2015)以及Zhou等(2017)转向了新兴的NOBD,如地铁智能卡数据,以克服传统数据在分析大都市内移动中的限制。Li等(2018)使用兴趣点(POI)数据来估算通勤模式。NOBD在城市研究中的使用为决策者和分析师提供了额外的用户和/或空间信息来源(Batty,2012)。这些NOBD的特点可能会改变我们量化、规划、管理和/或监测城市的方式(Batty,2013)。许多例子(例如参见Alexiou等,2016;Batty,2016;Glaeser等,2018;Miller和Tolle,2016;Song等,2018a)已经表明了这种潜力可以实现。然而,只有少数学者研究了使用NOBD或结合传统数据的城市空间结构。
在上述背景下,本文旨在开发一种使用NOBD研究城市空间结构的通用程序和方法。具体来说,我们提出了一种非参数方法,该方法结合了Jenks自然断裂法和局部Moran’s I,定量识别城市中的主中心和子中心。采用POI数据,而非传统的人口或就业数据,来衡量中国284个城市的城市多中心性。我们发现2011年有70个中国城市具有多中心结构。为了验证这一发现,我们将结果与现有研究中常用的数据和方法进行了比较。在知道每个城市的子中心数量后,我们进一步探讨了多中心结构的决定因素。遵循以往的研究(例如Li等,2016;Liu和Wang,2016;McMillen和Smith,2003;Sun和Lv,2020;Sun等,2017),我们进行了回归分析,以揭示多中心性与城市特征之间的关联。回归结果表明,样本城市的总人口、GDP、平均工资和城市面积与子中心数量显著相关。
【文献综述】
2.1 城市空间结构、子中心和多中心城市
20世纪80年代,研究人员提出了一种观点,即现代大都市的特征是存在多个活动节点,而不是单一的主导核心(Lee,2007)。这些活动节点或就业和人口集群被命名为“郊区市中心”(哈特肖恩和穆勒,1989年)、“边缘城市”(加罗,1991年)、“技术中心”(斯科特,1990年)或“就业子中心”(朱利亚诺和斯莫尔,1991年)。由于这些研究者的开创性工作,子中心和多中心城市的概念得到了广泛的讨论。研究人员提出并应用了各种标准来定义子中心,如就业规模、办公室和/或零售空间、通勤流量、就业-住房比率和土地使用组合(Cervero,1989;朱利亚诺和斯莫尔,1991年)。此后,研究在定义多中心城市的子中心时越来越依赖于就业密度(克雷格和吴,2001;McMillen,2001;Pfister et al.,2000)。城市就业子中心的主要属性是其就业密度明显高于周边地区(麦克唐纳,1987年),以及它对附近地区甚至整个地区的密度的影响(朱利亚诺和斯莫尔,1991年;Gordon等人,1986年;麦克米伦,2001年)。然而,与上述对子中心的定义不同,Li et al.(2016)认为,人类活动的水平提供了最准确的城市功能的表示,而城市中心或子中心应该是一天中某个小时的人类活动集群。Zhang等人(2017)还认为,多中心结构可以通过人口、工业和基础设施来预测。这一新的思想浪潮需要重新思考子中心识别。
虽然对城市空间结构的研究主要集中在定义和测量多中心度上,但很少有人明确概述这样做的重要性。Meijers(2008)是第一个强调在欧洲国家城市系统中描述功能性城市区域对于测量多中心度的重要性的人之一。后来,张和德鲁dder(2019)的一项研究在中国城市地区发现了类似的结果,并认为城市地区的多中心度对计算中确定和包含的中心数量很敏感。他们的两项研究都表明,中心识别本身并不是目的,但对理解城市和区域系统具有重要意义。例如,在多中心城市区域的背景下,研究倾向于通过检查城市中心之间的功能联系来分析空间组织(例如,Burger等人,2014年;Vasanen,2012年)。对于研究多中心城市系统的研究,多中心结构已被用来解释经济生产力(Wang et al.,2019)和贫困的分散化(Zhang和Pryce,2020)。
2.2 用常规数据和NOBD识别子中心
20世纪80年代,学者们开始认识到城市空间结构正在发生变化,这主要是交通成本下降和城市扩张快速增长的结果。人们已经努力量化这些变化,特别是子中心的出现。麦克唐纳(1987)使用了从与芝加哥中央商务区(CBD)的距离上的就业密度回归的正残差作为子中心的衡量标准。Giuliano和Small(1991)定量地将洛杉矶的一个子中心定义为一个连续的区域集群,每英亩至少有10名员工,至少有10,000名员工。从那时起,就业密度被广泛用于确定子中心(例如,鲍嘉和费里,1999;克雷格和吴,2001;麦克唐纳和麦克米伦,1990;麦克米伦,2001;麦克米伦和麦克唐纳,1998;Pfister等人,2000)。最近,对子中心识别的研究仍然对学者们很有吸引力,但他们使用的数据已经变得更加多样化。例如,Nasri和Zhang(2018)使用了来自亚特兰大和凤凰城的细粒度土地使用数据来确定区域就业子中心。Liu等人(2018)利用1990年和2000年人口普查运输计划包数据和2006-2010年美国社区调查,探讨了休斯顿和达拉斯就业中心的变化。
在上述研究中,有许多关于子中心识别的方法可以被推广起来。这些方法根据其密度标准进一步分为两组。在在线补充材料中提供了一个总结现有方法的表(见表S1)。一组方法基于绝对密度准则确定子中心,这意味着使用最小密度阈值来定义子中心。例如,朱利亚诺和斯莫ll(1991)将城市子中心定义为一组连续的区域,每英亩至少10名员工,至少10,000名员工。从那时起,绝对密度标准在现有的研究中被广泛应用,通过数值调整以适应不同的环境(例如参见安德森和鲍嘉,2001;鲍嘉和费里,1999;黄等,2017;刘和王,2016;Pfister等,2000)。该方法的关键参数是最小密度阈值;但这也是其在应用时的主要缺陷和相应的技术困难。最小密度有些武断,其合理性在很大程度上依赖于个体研究人员对研究区域的知识和观察(Huang,2015;李,2007)。这使得在时间和空间上扩大研究范围或在另一种背景下复制一项研究很困难,如果不是不可能的话。
另一组是基于相对密度标准,包括使用各种就业密度函数,无论是参数的还是非参数的(表S1)。麦克唐纳(1987)首次提出了一种更客观的方法,将一个子中心定义为从就业密度对CBD距离的简单回归。麦克唐纳和麦克米伦(1990)随后使用同样的方法来确定了芝加哥的就业子中心,他们的结果得到了当地知识的验证。类似地,Craig和Ng(2001)和McMillen(2001)都根据就业密度函数在美国样本城市中确定了子中心。后来,Sun等人(2012)和Huang等人(2015)也对北京的子中心的研究进行了密度回归。
在信息时代,技术的发展产生了大量来自多个来源的数据,这反过来又鼓励和触发了多个学科的快速发展和创新。在城市研究中,NOBD有能力填补传统研究方法和数据的空白,并建立自下而上的规划和设计道路(Li et al.,2016)。目前在城市研究中使用最广泛的NOBD包括poi、手机信号数据、公共交通智能卡交易、社交媒体帖子和来自智能手机应用程序的基于位置的服务(LBS)数据。NOBD有一些共同的属性,包括更精细的分辨率、更广泛的覆盖范围和更高的更新频率,所有这些都使它们成为分析我们的城市系统的优秀数据。对城市空间结构的研究也采用了NOBD。POI或类似的LBS数据(如百度热图和滴滴出租车记录)已用于量化城市多中心度(段等,2018年;郭等,2015年;李等,2016年),划定城市边界(陈等,2020年;2010年;霍伦斯坦和紫色,2010年;宋等,2020年;徐和高,2016年),以及识别人口流动(Becker等,2011年;宋等,2019年)。然而,与传统的城市空间结构研究相比,使用NOBD的新兴研究仍然相当有限。
2.3 影响城市多中心性的因素
承认多中心城市正在世界范围内出现,学者们已经开始探索这种进化背后的机制。越来越多但有限的文献研究了城市多中心性之间的关系,这通常代表了子中心的数量,以及城市的物理和社会经济特征。因此,这些研究旨在产生关于多中心城市形成的初步但重要的假设。例如,在对62个美国大型城市地区,McMillen和Smith(2003)的泊松回归中发现,子中心数量的关键解释变量是人口和通勤成本。Liu和Wang(2016)发现,在中国东部地区,较高程度的多中心度与分散景观中的城市相关,根据地形特征和土地总面积,人均GDP与高多中心度呈正相关。Li等人(2016)、Sun等人(2017)、Sun和Lv(2020)也进行了类似的分析,尽管在不同的城市地区使用了不同的预测因子。这些研究丰富了城市空间结构演化的理论基础;然而,实证证据仍然不足。
综上所述,我们的文献综述表明,中心和子中心识别仍然是现有城市空间结构研究的主流。大多数现有的研究仍然使用传统的人口统计数据(不能准确地反映空间结构,也不允许历时性比较研究)和传统的方法来识别有限数量的城市的子中心,这极大地限制了其发现的意义。虽然NOBD已被用于相关研究,但仍有改进的空间。此外,对影响多心的因素讨论不够(Lan et al.,2019)。为了填补这些空白,本文试图以中国284个城市为研究对象,采用POIs和一种新的非参数中心/子中心识别方法来扩展文献。这使我们能够同时识别数百个城市的主要中心和子中心(如果有的话),并调查这些城市的多中心性的可能决定因素。
【研究区域和数据】
3.1 研究区域和分析单位
在本文中,我们主要关注地级市(中文中的“地级市”)及以上的中文语境。总共有284个这样的城市。
值得注意的是,“城市”的定义自最早的人类住区集中地以来一直在不断变化。一个被广泛接受的城市定义是由行政边界划定的区域,由政府为行政目的划分,如税收、治理和人口普查。由行政边界定义的城市的一个共同属性是,它们经常覆盖一些非城市地区,这一属性近年来引起了城市规划者和研究者的关注。他们认为,行政边界可能会给城市研究带来挑战,因为大多数人类活动只发生在城市化地区。我们如何定义“城市”,实际上会影响到我们如何理解和解决城市问题。新兴的研究已经开始重新定义“城市”。例如,Long(2016)根据新出现的大的、开放的数据,应用了渗透理论,提出了另一种基于道路交叉口的城市定义。Song等人(2018b)利用POI数据和道路网络重新定义了中国城市的功能区。
我们了解上述进展,但在本研究中,我们仍然采用行政边界来定义“城市”,原因有很多。首先,利用行政边界来定义一个城市或地区并不是中国独有的。类似的众所周知的概念是美国的大都市统计区(MSA)和县,这两个概念都包括了城市化地区周围的大部分农村地区。其次,以往关于城市空间结构和子中心识别的研究大多采用了行政城市,如Gordon等(1986)、麦克唐纳(1987)、Pfister等(2000)、戴等(2014)、于和吴(2016)和李等(2016)。如果我们使用相同的城市定义,我们的结果可以很容易地与这些研究进行比较。第三,一个城市的行政边界相对稳定,这极大地促进了历史比较和纵向分析,而过去缺乏NOBD仅仅使得不可能使用NOBD技术来定义老城市。第四,行政边界是必须制定规划或政策,这些规划或政策往往适用于某些行政边界内的地区或利益相关者。
3.2 数据
我们的文献综述表明,该城市的主要中心和子中心在历史上一直被定义和衡量为超过一定阈值的就业集群或住宅集群。然而,我们认为,一个中心或子中心应该能够提供多功能的城市功能,并支持各种人类活动,不仅包括住宅和就业,还包括娱乐、教育和社会互动。作为一个新兴的NOBD、POIs记录了城市中不同地点的位置信息和属性。这些地方与人们的日常生活高度相关,如餐馆、商场、办公楼、汽车站、银行等,这使得基于POI数据的指标是各种城市功能和人类活动的良好代理。为了定量识别和分析城市空间结构,我们从百度地图应用程序编程接口(http://lbsyun.baidu.com/)中收集了2011年中国大陆的5,281,382个poi。
【方法】
正如文献综述中所指出的,在识别副中心的过程中,绝对密度和相对密度标准都遵循一个共同的原则:副中心在大都市区内应表现为一个密度的局部峰值。在本文中,我们遵循同样的原则,将城市的主中心定义为人类活动水平最高的一个或多个街区组成的空间聚集区域,而副中心则是地理上与主中心分离、但人类活动水平相对较高的次区域。换句话说,一个合格的副中心应在其周围环境中具有显著较高的人类活动水平(局部高),并且在城市所有街区中具有相对较高的密度(整体高)。此外,我们认为一个好的识别方法应该能够在研究者不熟悉研究区域的情况下产生合理的结果,这意味着该方法应具有非参数性并且在时间和空间上具有可转移性。此外,该方法应相对易于操作,并且可以自动化以支持同时对多个城市副中心的分析。最后但同样重要的是,该方法应充分利用新型大数据(NOBD),这种数据不仅具有之前提到的优点,而且成本低廉且越来越容易获得。
鉴于上述考虑,我们采用了一种非参数方法,利用POI(兴趣点)密度这一典型的新型大数据来识别主中心和副中心。该方法的计算流程图可在在线补充材料(图S1)中找到。在我们的方法中,首先计算城市中每个街区的POI密度。然后,根据每个城市的街区数量,分别使用Jenks自然断点法或Anselin局部莫兰指数来分类和识别主中心和副中心。局部莫兰指数是一种基于概率理论的推断性空间模式分析工具,应用该工具需要有一个足够大的样本量,以满足大数定律(LLN)和中心极限定理(CLT)的要求,而样本量过小可能会导致推断错误(Bivand等,2019)。在学术界,样本量为30是广泛认可和接受的经验值,以满足LLN和CLT的最低要求(Ott和Longnecker,2015),因此在本研究中作为模型选择的阈值。
对于街区数量少于30的城市,使用Jenks自然断点法根据POI密度的分布将所有街区划分为多个类别,并以方差拟合优度大于0.8作为接受分类结果的通用阈值(Jenks,1967)。然后,将自然断点结果中属于前两类的街区识别为主中心和副中心候选者(如图1a所示)。接着,我们将POI密度最高的候选街区定义为城市的主中心。对于所有其他候选街区,如果某一街区在地理上与主中心相邻,它也将被识别为主中心的一部分,而与主中心地理上分离的街区将被定义为副中心(如图1a所示)。

图1.城市空间结构识别过程:(a)以黄山(小于30个分区)为例,演示Jenks自然断裂过程;(b)以沈阳(超过30个分区)为例,演示莫兰I和Jenks自然断裂过程。
对于拥有超过30个街区的城市,在使用上述方法选择POI密度较高的街区之前,首先计算局部莫兰指数(Anselin,1995)(如图1b所示)。局部莫兰指数是一种广泛用于经济学、资源管理、生物地理学、政治地理学和人口统计学中的空间统计工具,用于聚类和异常值分析。
空间关联的局部莫兰指数统计量为:
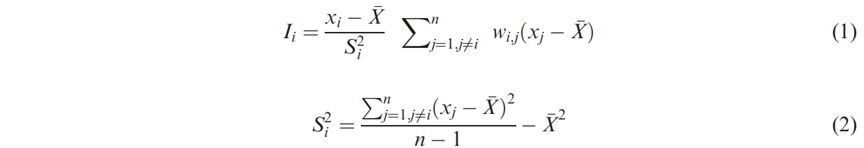
其中,xi和xj分别是特征i和j的属性,X是相应属性的均值,wi,j是特征i和j之间的空间权重,Sj2是全局样本方差,n是特征的总数。在这种情况下,xi指的是街区i的 POI 密度。
当局部莫兰指数(local Moran's I)结果为正值时,意味着一个街区及其周围的街区形成了一个高密度或低密度的聚类。负值结果表明,一个POI密度相对较高的街区被POI密度较低的街区包围,反之亦然。在本研究中,如果一个街区的局部莫兰指数值大于0(在95%的置信区间内),则该街区及其相邻的属于Jenks自然断点结果第一类的街区被定义为城市的主中心。如果一个街区的莫兰指数值为负,但其POI密度被分类为前三名,则将其定义为副中心,如图1a所示。
我们提出的方法不仅在识别局部峰值时考虑了不同街区的密度属性,还考虑了它们的空间关系。此外,这种非参数方法仅需要POI密度作为输入,不需要研究区域的本地知识,因此可以在不同背景下重复使用。
【结论和验证】
4.1 中国城市的子中心
我们在中国大陆发现了70个多中心城市,其中大多数位于中国中东部地区(图2)。这些多中心城市的人口范围从85万(铜川市)到3300万(重庆市),平均为500万,标准差为450万,表明城市之间存在极大的偏差。在这70个多中心城市中,2011年有31个城市人口超过500万,这意味着多中心性不仅存在于大城市中,也存在于小城市中。
在这70个多中心城市中,副中心的数量范围从1个到12个,其中57%的城市仅识别出一个副中心,而2011年只有10个城市有超过2个副中心。这70个多中心城市的主中心和副中心的空间分布在在线补充材料中展示(见图S2)。
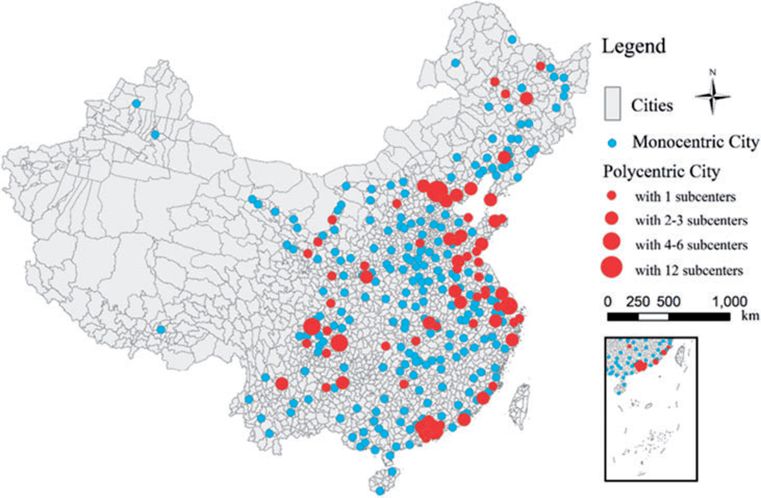
图2:中国多中心和单中心城市的分布情况。
4.2 子中心的空间格局
副中心的数量和主中心与副中心之间的平均距离提供了一种直接描绘城市空间结构的方法。这些距离因城市而异,并受多种因素的影响,如地形特征、城市土地面积和道路网络布局。在本研究中,我们将每个城市主中心和副中心多边形的重心定义为起点和终点,然后计算它们之间的平均线性距离(MD)。我们还采用MD与城市土地面积平方根的比率作为指标,以量化主中心和副中心的空间分布特征(SDCs)(详细信息见在线补充材料中的表S2)。
在考虑的70个城市中,最长的MD出现在兰州市,为93.69公里,而最短的是威海市,为5.72公里,大多数城市(62.9%)的MD在15至30公里之间。SDC考虑了城市的几何面积,反映了副中心的地理范围。较大的SDC通常表示副中心位于城市边界的外围,而较小的SDC则意味着副中心在主中心周围的分布更为紧凑。
4.3 结果验证
由于我们在中心和副中心识别中采用了新数据和方法,因此有必要验证我们的结果是否有效和稳健。为了进行验证,我们首先将结果(见“中文城市的副中心”部分)与基于现有方法和传统/普查数据的结果进行比较。以北京为例。在北京,我们幸运地获得了2000年、2005年和2009年三个不同年份的乡镇(街区)层面的就业数据。通过使用“方法论”部分中突出显示的现有方法,我们获得了这些年份北京基于工作密度的多中心结构(见图3a至c)。相比之下,图3d展示了本研究的结果。
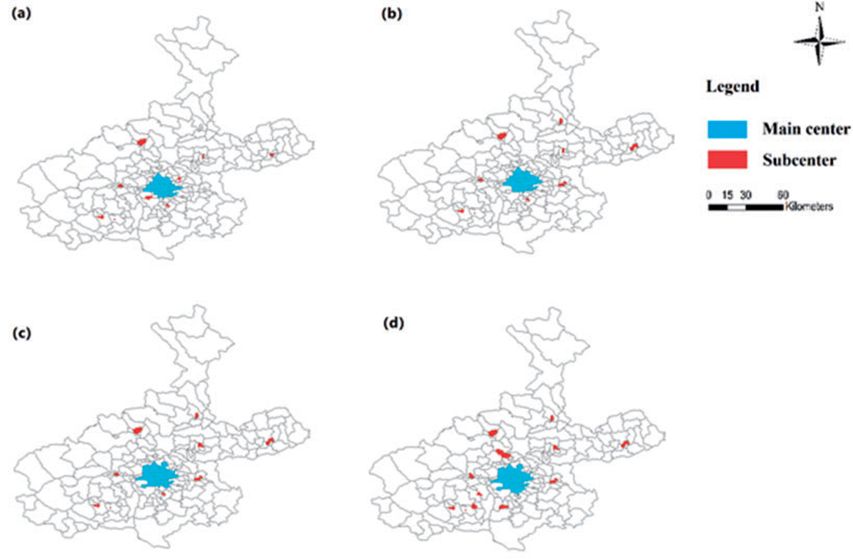
图3.北京中确定的主要中心和子中心:(a)使用2000年的工作密度数据;(b)使用2005年的工作密度数据;(c)使用2009年的工作密度数据;(d)使用2011年的POI密度数据。
图3a-d共享一个共同的副中心子集,这意味着这些副中心可能随着时间的推移保持不变。与图3a-c相比,显著的是图3d在西北和东南地区识别出了几个新的副中心。我们的本地知识和现场审计告诉我们,单纯的传统就业数据可能无法捕捉到具有多样开放空间、公共设施和商业店铺但办公楼稀少的高密度住宅社区。百度热力图作为一种广泛用于人类活动集中度的代理工具,也可以证实这一点。与Li等人(2016)使用百度热力图捕捉广泛的人类活动范围的研究结果相比,图3d中相对于图3a-c的额外副中心是可以辩护的。
除了上述交叉检查,我们还将本研究的结果(图4b和d)与McMillen(2001)提出的传统/现有方法的结果(图4a和c)进行比较。图4a和c改编自Sun等(2012)和Sun与Wei(2014)。比较结果表明:(a)我们的结果识别出的副中心数量多于其他学者的研究,这一点已在上文中强调;(b)我们结果中的一部分副中心与其他学者的结果相同。这表明,本研究的方法至少可以识别出与传统/现有方法相当的副中心,前者可能还会识别出后者无法识别的副中心。
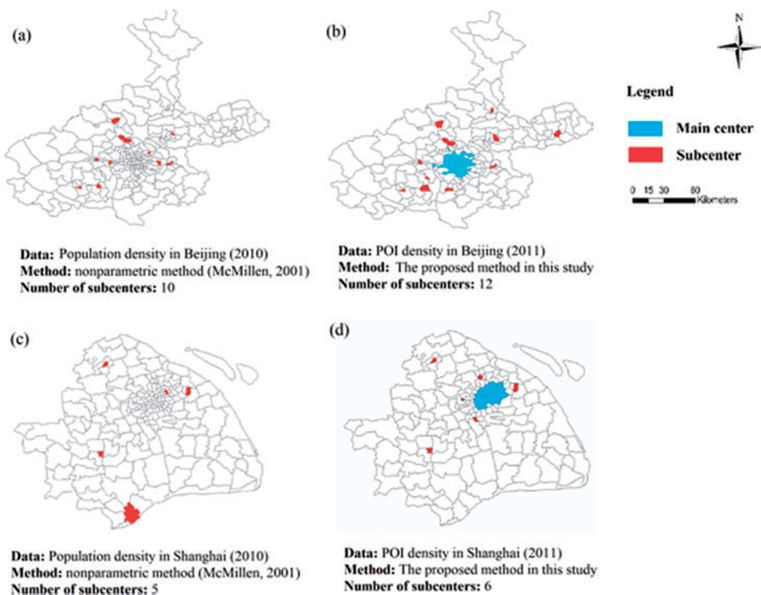
图4.通过现有研究和本研究确定的子中心。POI:兴趣点。
表1. OLS回归结果。

4.4 多中心性与城市特征关系的回归分析
当学者们找到识别副中心的方法时,影响城市多中心性的因素便成为研究的重点。虽然关于城市多中心性的研究数量增长但仍有限,这些研究通过回归城市特征来检查其相关性。在本研究中,我们识别出284个中国城市中的70个具有多中心结构,这为分析城市多中心性及其影响因素之间的关系提供了一个相当好的样本量。具体而言,本研究创建了一个多元回归模型,以检验副中心数量与城市的地理、社会经济和人口特征之间的相关性。鉴于现有研究中关于自变量选择并无一致意见,本文选择了文献中最广泛使用的变量(参见 Li et al., 2016; Liu 和Wang, 2016; McMillen 和 Smith, 2003; Sun 和Lv, 2020; Sun et al., 2017),并充分考虑了数据的可用性。最终,总人口、GDP、员工和工人的平均工资、建设用地面积、总城市土地面积和道路交叉口密度被用作回归分析中的预测变量。
每个自变量都通过最小-最大归一化进行标准化,以消除它们之间的维度差异。普通最小二乘(OLS)回归结果见表1。在0.05的显著性水平下,总人口与副中心数量呈显著负相关,这意味着在其他因素保持不变的情况下,人口较多的城市平均副中心数量较少。初看这一结果令人惊讶,因为我们注意到副中心较多的城市是如北京和上海这样的大城市。进一步检查发现,人口较少的城市中,大多数中西部城市人口相对较多,但只有一个副中心。这些城市仍处于城市多中心化的早期阶段,人口集中是推动其第一个副中心形成的动力(Zhao, Dang 和Wang, 2009)。总城市土地面积与副中心数量呈正相关,而建设用地面积则不显著。这一结果并不难预测,因为较大的城市可能为副中心的出现和发展提供了足够的空间。GDP 和员工平均工资反映了城市的经济发展水平,两者都与副中心数量显著相关。GDP 和平均工资的正系数验证了副中心通过聚集也可以产生规模经济,从而对经济做出贡献。尽管本研究采用了新的方法和数据来识别城市副中心,但我们在多中心性与城市特征之间的相关性方面的一些发现与以往研究一致,如总人口的负相关(Zhao, Dang 和Wang, 2009),以及城市土地面积(Liu 和Wang, 2016)和 GDP(Lip et al., 2018; Liu 和 Wang, 2016; Sun et al., 2017)的正面影响。
【讨论和结论】
本研究探讨了利用新提出的非参数方法,通过广泛可用的POI数据(在街区层面)识别城市副中心的可行性和可靠性。通过对284个中国地级市实施该方法,识别出2011年有70个城市至少有一个副中心。为了验证所提方法和数据的稳健性,将结果与采用传统方法和数据的现有研究进行比较。结果表明,新方法和POI数据都能有效地识别副中心。为了进一步阐述我们的结果,我们创建了一个回归模型,以分析副中心数量与城市某些选定的社会经济、地理和人口特征之间的关系。回归结果表明,城市的副中心数量与土地面积和经济表现正相关,但与人口规模负相关,尤其是在中国中西部城市。这些发现可以指导地方政府和规划官员识别城市的多中心化阶段,并为相关的城市空间结构变化做好准备。
总体而言,我们认为本文对城市空间结构(尤其是城市多中心性)文献做出了两个主要贡献。首先,引入POI数据用于副中心识别,为城市空间结构提供了一种替代思路,该方法考虑了多样化的城市功能,并支持各种人类活动。相比之下,大多数现有研究将副中心定义为就业或人口的聚集体。自那些研究以来,城市不断发展,人类活动,如物联网、共享经济、众包和智能手机的出现,使得活动变得更加多样和复杂。因此,城市的主中心和副中心支持更多样化的人类活动,不仅包括工作,还包括生活方式、休闲、随机遭遇、展览、会议和娱乐(参见 Li et al., 2016)。得益于NOBD的快速发展和广泛可用性,我们现在可以基于比以往更丰富、更连续、更及时(甚至实时)的信息重新定义和识别主中心和副中心(参见 Batty, 2016)。本研究展示了POI数据在识别主中心和副中心方面的潜力,这些特征可以帮助城市规划者和研究人员更深刻、高效和可靠地了解我们的城市,并理论上支持城市中更及时和积极的政策和决策。
其次,我们提出了一种使用Jenks自然断点和莫兰指数(Moran’s I)的非参数方法来识别和定位城市中的主中心和副中心。通过将相应结果与现有研究中的结果进行比较,验证了该方法的有效性和稳健性。我们的方法具有避免现有方法中某些潜在问题的优点,如设置人口和/或就业密度阈值的随意性、对空间尺度的敏感性以及计算密度表面的复杂性。此外,POI数据的广泛可用性和我们提出的可复制方法使研究人员能够在新的背景下重现他们的研究。
毫无疑问,未来的研究仍有改进空间。首先,使用POI作为点数据在描述对象的覆盖范围和规模方面存在局限。例如,从点数据中无法判断一个商业POI是本地杂货店还是连锁超市。与捕捉确切人数的传统就业或人口数据不同,POI数据提供了城市功能的代理和对人类活动聚合水平的一些描述。其次,我们在识别中国的多中心城市后尝试探讨可能与城市结构相关的因素。诚然,我们的回归分析样本量受到中国地级城市总数的限制。尽管回归结果在统计上显著,但其实际意义可能从样本量的扩展或进行多年度数据的面板分析中获益。最后,本研究的主要目的是展示非参数方法和NOBD在研究城市空间结构中的可行性和优势;因此,仅使用了2011年的数据,未能进行主中心和副中心的纵向研究。然而,我们知道在中心和副中心识别中没有单一最佳方法,所有优缺点应在特定背景下进行讨论。例如,本文提出了一种基于广泛POI数据的精细非参数方法,该方法在大规模分析和比较中具有优势。在未来的研究中,我们可以结合多种NOBD来源,如POI数据和LBS数据,包括但不限于汽车GPS、智能手表、安全摄像头和食品配送,以及多种地理和时间尺度的传统普查和调查数据。这种组合将使我们能够获得更多关于和对城市空间结构的洞察,回答以下问题:什么样的POI组合可以使副中心吸引稳定的人流?访客通常在副中心停留多久?人员流动如何影响不同副中心的吸引力。
















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









