







This repository contains pre-trained models and sampling code for the 3D Generative Adversarial Network (3D-GAN) presented at NIPS 2016.
Prerequisites
论文介绍
3D-GAN which generates 3D objects from a probabilistic space by leveraging recent advances in volumetric convolutional networks and generative adversarial nets. The benefits of our model are
three-fold: first, the use of an adversarial criterion, instead of traditional heuristic
criteria, enables the generator to capture object structure implicitly and to synthesize high-quality 3D objects; second, the generator establishes a mapping from
a low-dimensional probabilistic space to the space of 3D objects, so that we can
sample objects without a reference image or CAD models, and explore the 3D
object manifold; third, the adversarial discriminator provides a powerful 3D shape
descriptor which, learned without supervision, has wide applications in 3D object
recognition.
a generative model should be able to go beyond memorizing and
recombining parts or pieces from a pre-defined repository to produce novel shapes; and for objects to
be realistic, there need to be fine details in the generated examples.
随着large 3d cad数据集的引入,如ShapeNet,产生了一些有趣的想法:如基于体素的深度表示;不同于检索式,它是用深层表示来合成3d 物体的。即隐形编码2d图片,用于产生其深度特征表示,再利用其深度特征产生3d图像;本文方法将深度对抗网络和体元卷积网络融合,通过判别器来判断3d object is synthesized or real.
作者用高斯或者均值分布来生成3d object,并且利用无监督的方式。判别器和传统的3d物体判别其一样,可以用来判别一个输入是否为真实的3d物体。另外,作者实验了利用VAE,将2d图像作为输入,先产生其向量表示,再生成其对应的3d物体,其中当然有一定的限制,即输入图像的范围式一定的,不可任意输入。
近年来一些工作如:学习联合学习嵌入的3d shape和合成图像;学习判断3d object的判别式表达;利用循环网络进行3d重构;尝试生成3d图像;有些将图像用于3d像2d投射的过程中;大多数这些都是监督训练的,可以用来3d shape检索、分类、重构;
Network structure Inspired by Radford et al. [2016], we design an all-convolutional neural
network to generate 3D objects. As shown in Figure 1, the generator consists of five volumetric fully
convolutional layers of kernel sizes 4 × 4 × 4 and strides 2, with batch normalization and ReLU
layers added in between and a Sigmoid layer at the end. The discriminator basically mirrors the
generator, except that it uses Leaky ReLU [Maas et al., 2013] instead of ReLU layers. There are no
pooling or linear layers in our network.
Training details A straightforward training procedure is to update both the generator and the
discriminator in every batch. However, the discriminator usually learns much faster than the generator,
possibly because generating objects in a 3D voxel space is more difficult than differentiating between
real and synthetic objects [Goodfellow et al., 2014, Radford et al., 2016]. It then becomes hard
for the generator to extract signals for improvement from a discriminator that is way ahead, as all
examples it generated would be correctly identified as synthetic with high confidence. Therefore,
to keep the training of both networks in pace, we employ an adaptive training strategy: for each
batch, the discriminator only gets updated if its accuracy in the last batch is not higher than 80%. We
observe this helps to stabilize the training and to produce better results. We set the learning rate of
G to 0:0025, D to 10−5, and use a batch size of 100. We use ADAM [Kingma and Ba, 2015] for
optimization, with β = 0:5.
实验部分主要是:1、可视化判别器;2、比较生成器,是否记住数据;3、插值,有一类物体线性插值到另一类物体,如从汽车逐渐变化到船
4、算术运算,即物体可以做bool运算,一个东西减去另一个东西得到其剩余部分,两个东西相加得到两个物体的和。

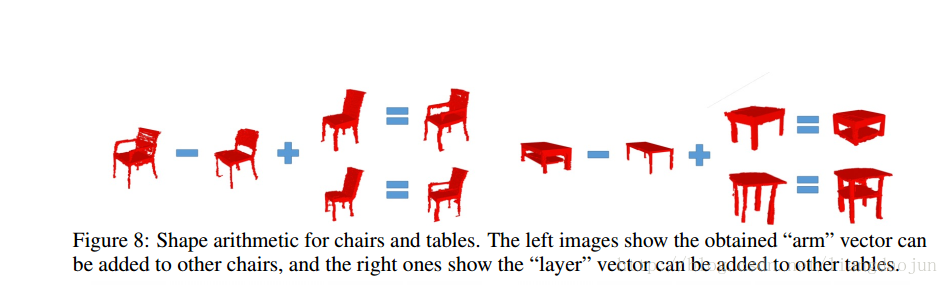
最后一个分是如何训练2d图像到3d物体的映射,如下图:

文章多处强调无监督学习,但没有提如何进行无监督训练。
















 1044
1044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









