






 本文介绍了大模型指令对齐训练的各种方法,包括RLHF、SFT、RRHF、LIMA、DPO和RAFT等。RLHF通过AI模型间的相互评估和微调实现对齐;RRHF通过排名损失实现人类偏好对齐;LIMA假设对齐主要发生在预训练阶段;DPO提出直接优化语言模型以匹配人类偏好;RAFT涉及模型的自我指令创建和自我奖励,以迭代方式提升模型能力和奖励建模效果。
本文介绍了大模型指令对齐训练的各种方法,包括RLHF、SFT、RRHF、LIMA、DPO和RAFT等。RLHF通过AI模型间的相互评估和微调实现对齐;RRHF通过排名损失实现人类偏好对齐;LIMA假设对齐主要发生在预训练阶段;DPO提出直接优化语言模型以匹配人类偏好;RAFT涉及模型的自我指令创建和自我奖励,以迭代方式提升模型能力和奖励建模效果。
原文地址:大模型指令对齐训练原理
- RLHF
- SFT
- RM
- PPO
- AIHF-based
- RLAIF
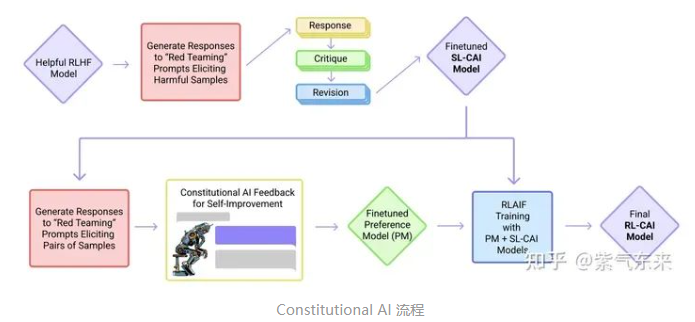
- 核心在于通过AI 模型监督其他 AI 模型,即在SFT阶段,从初始模型中采样,然后生成自我批评和修正,然后根据修正后的反应微调原始模型。在 RL 阶段,从微调模型中采样,使用一个模型来评估生成的样本,并从这个 AI 偏好数据集训练一个偏好模型。然后使用偏好模型作为奖励信号对 RL 进行训练
- RR
- RLAIF

原文地址:大模型指令对齐训练原理


 1526
1994
1397
1526
1994
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























