







 PreFLMR是剑桥大学信息工程系人工智能实验室开源的预训练多模态知识检索器,它改进了FLMR结构,并在M2KR上进行了大规模预训练。该模型能提升多模态大模型在知识密集型任务中的表现,通过细粒度后期交互处理图文信息,提高了检索效率和准确性。
PreFLMR是剑桥大学信息工程系人工智能实验室开源的预训练多模态知识检索器,它改进了FLMR结构,并在M2KR上进行了大规模预训练。该模型能提升多模态大模型在知识密集型任务中的表现,通过细粒度后期交互处理图文信息,提高了检索效率和准确性。
PreFLMR模型是一个通用的预训练多模态知识检索器,可用于搭建多模态RAG应用。模型基于发表于 NeurIPS 2023 的 Fine-grained Late-interaction Multi-modal Retriever (FLMR) 并进行了模型改进和 M2KR 上的大规模预训练。
-
论文链接:https://arxiv.org/abs/2402.08327
-
DEMO 链接:https://u60544-b8d4-53eaa55d.westx.seetacloud.com:8443/
-
项目主页链接:https://preflmr.github.io/
-
论文标题:PreFLMR: Scaling Up Fine-Grained Late-Interaction Multi-modal Retrievers
背景
尽管多模态大模型(例如 GPT4-Vision、Gemini 等)展现出了强大的通用图文理解能力,它们在回答需要专业知识的问题时表现依然不尽人意。即使 GPT4-Vision 也无法回答知识密集型问题(图一上),这成为了很多企业级落地应用的瓶颈。
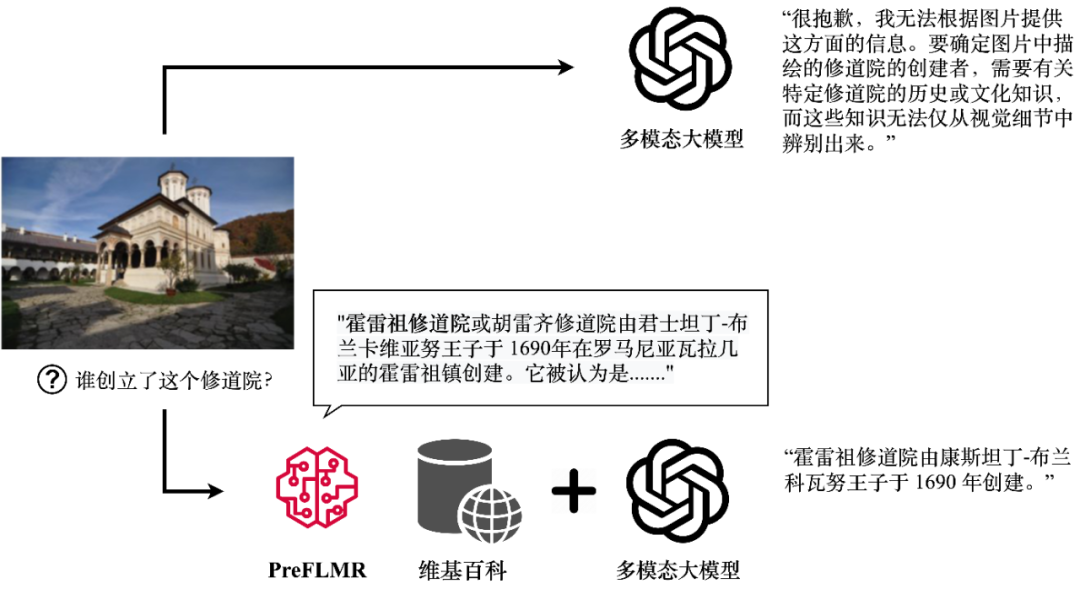
图 1:GPT4-Vision 在 PreFLMR 多模态知识检索器的帮助下可以获得相关知识,生成正确的答案。图中展示了模型的真实输出。
针对这个问题,检索增强生成(RAG,Retrieval-Augmented Generation)提供了一个简单有效的让多模态大模型成为” 领域专家” 的方案:首先,一个轻量的知识检索器(Knowledge Retriever)从专业数据库(例如 Wikipedia 或企业知识库)中获得相关的专业知识;然后,大模型将这些知识和问题一起作为输入,生成准确的答案。多模态知识提取器的知识 “召回能力” 直接决定了大模型在回答推理时能否获得准确的专业知识。
近期,剑桥大学信息工程系人工智能实验室完整开源了首个预训练、通用多模态后期交互知识检索器 PreFLMR (Pre-trained Fine-grained Late-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









