







 本文介绍了PyTorch神经网络的基础知识,包括为何使用tensor,自动求导的重要性,以及神经网络的构建过程。文章通过逻辑回归模型展示了线性模型的训练和优化,探讨了梯度下降算法和学习率的影响,并逐步解释了多层神经网络的搭建。此外,还提到了模型的保存和加载方法。
本文介绍了PyTorch神经网络的基础知识,包括为何使用tensor,自动求导的重要性,以及神经网络的构建过程。文章通过逻辑回归模型展示了线性模型的训练和优化,探讨了梯度下降算法和学习率的影响,并逐步解释了多层神经网络的搭建。此外,还提到了模型的保存和加载方法。
pytorch简介
为什么神经网络要自定义数据类型torch.tensor?
tensor可以放在gpu上训练,支持自动求导,方便快速训练,同时支持numpy的运算,是加强版,numpy不支持这些
为什么要求导?
导数是真实值和预测值的误差函数下降最快的地方,根据求导可以快速降低误差值,让真实值和预测值贴合


pytorch0.4版本之后,variable的功能已经被整合进入tensor,不再需要被显示声明了
# 创建一个 Variable,并设置 requires_grad=True
x = autograd.Variable(torch.tensor([1.0]), requires_grad=True)
# 创建一个 Tensor,并设置 requires_grad=True
x = torch.tensor([1.0], requires_grad=True)

神经网络基础
监督学习:已经打标记的样本进行训练,然后预测
非监督学习:对一些无标记数据进行结构化分类,发现潜在的规律
强化学习:一个机器不断根据新的输入做出决策,然后根据结果进行奖惩来学习
线性模型:y=wx+b,w就是要优化的值,我们要根据损失值来不断优化w让他的预测贴近真实值
这需要知道loss函数,(真实值和预测值之间的误差),然后根据loss函数的反馈优化w降低loss
当loss求和最小的时候可以得出预测越来越准
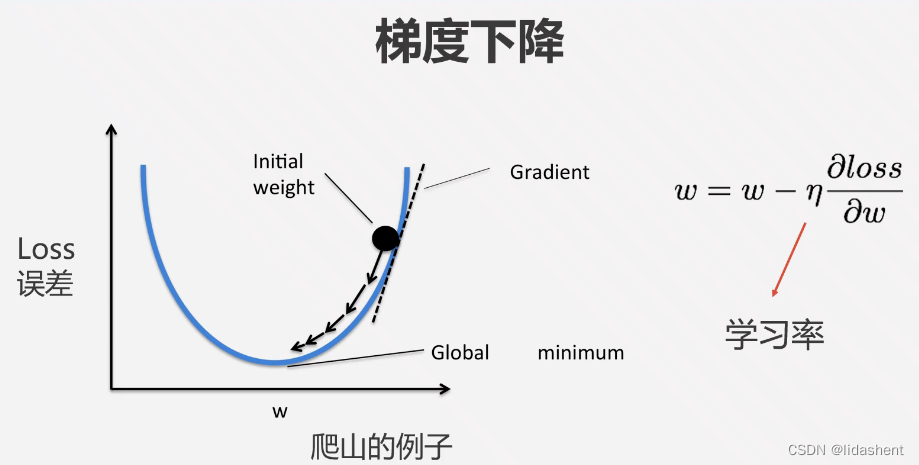
为了减少loss就需要知道loss在哪个方向下降的最快,这就是求导,梯度下降算法

更直观一点是让loss下降的更快,以至于降到最低,让真实值和预测值无限贴合,
学习率代表了斜率变化的步长,合理的设置会方便于我们找到最优w,错误的设置过大过小会导致预测值无法贴合真实值
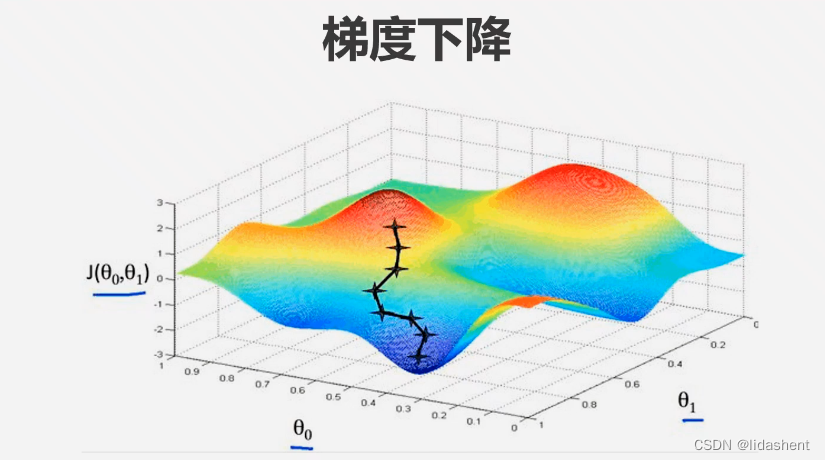
在三维和多维度图象上更容易理解这一点
当有三个维度的数据时更加直观
那么构建模型流程如下
定义参数,定义损失函数,定义网络模型,这里为线性模型,然后根据损失函数优化参数w让线性模型拟合的更好
理解线性模型对未来的深层模型构建有很大帮助
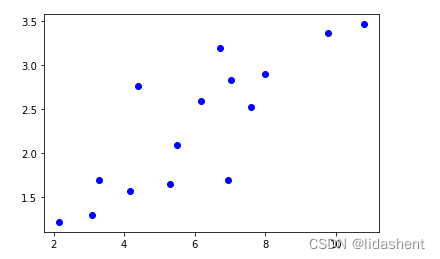
我们定义一些点,然后用线性模型拟合这些数据
x_train np.array([[3.3],[4.4],[5.5],[6.71],[6.93],[4.168],[9.779],[6.182],[7.59],[2.167],[7.042],[10.791],[5.313],[7.997],[3.1]],dtype=np.float32)
y_train =np.array([[1.7],[2.76],[2.09],[3.19],[1.694],[1.573],[3.366],[2.596],[2.53],[1.221],[2.827],[3.465],[1.65],[2.904],[1.3]],dtype=np.float32)
然后将这些数据转化为tensor类型,定义参数wb,使用正态分布随机初始化数据wb,定义网络模型,损失函数模型
损失函数模型计算误差方式为求平方差之和
x_train =torch.from_numpy(x_train)
y_train =torch.from_numpy(y_train)
w=Variable(torch.randn(1),requires_grad=True)
b=Variable(torch.zeros(1),requires_grad=True)
def linear_model(x):
return x*w1+b1
def get_loss(y_,y):
return torch.mean((y_-y_train)**2)
y_=linear_model(x_train)
loss=get_loss(y_,y_train)
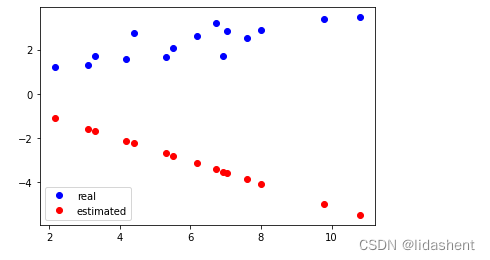
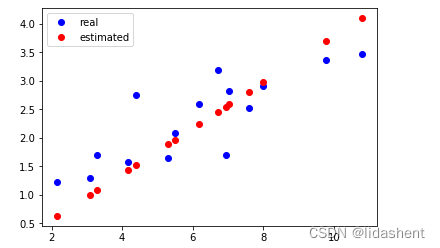
画出初始化后的预测图形为:这肯定不对的,然后对其进行优化
plt.plot(x_train.data.numpy(), y_train.data.numpy(), 'bo', label='real')
plt.plot(x_train.data.numpy(), y_.data.numpy(), 'ro', label='estimated')
plt.legend()
进行10次迭代
获得预测值,计算误差,将之前的梯度归零,计算新的梯度,根据新的梯度对参数wb进行优化
for e in range(10): # 进行 10 次更新
y_ = linear_model(x_train)
loss = get_loss(y_, y_train)
w.grad.zero_() # 记得归零梯度
b.grad.zero_() # 记得归零梯度
loss.backward()
w.data = w.data - 1e-2 * w.grad.data # 更新 w
b.data = b.data - 1e-2 * b.grad.data # 更新 b
print('epoch: {}, loss: {}'.format(e, loss.data[0]))
使用的是科学计数法,1e相当于10,科学记数法以x*10^n将所有数据进行分解,1e-2就是10的负二次方.0.01
梯度归零的意义在于得到新的梯度前清空上一次计算的梯度,对新的梯度进行优化
完整代码
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import numpy as np
import torch
import matplotlib.pyplot as plt
# 数据准备
x_train = np.array(
[[3.3], [4.4], [5.5], [6.71], [6.93], [4.168], [9.779], [6.182], [7.59], [2.167], [7.042], [10.791], [5.313],
[7.997], [3.1]], dtype=np.float32)
y_train = np.array(
[[1.7], [2.76], [2.09], [3.19], [1.694], [1.573], [3.366], [2.596], [2.53], [1.221], [2.827], [3.465], [1.65],
[2.904], [1.3]], dtype=np.float32)
x_train = torch.from_numpy(x_train).requires_grad_(False) # 不需要 x_train 的梯度
y_train = torch.from_numpy(y_train).requires_grad_(False) # 不需要 y_train 的梯度
# 定义参数
w1 = torch.randn(1, requires_grad=True)
b1 = torch.zeros(1, requires_grad=True)
# 定义线性模型
def linear_model(x):
return torch.mul(x, w1.expand_as(x)) + b1.expand_as(x)
# 定义损失函数
def get_loss(y_, y):
return torch.mean((y_ - y) ** 2)
# 初始预测
y_ = linear_model(x_train)
initial_loss = get_loss(y_, y_train)
print(f'Initial loss: {initial_loss.item()}')
def drawY(y_):
plt.plot(x_train.numpy(), y_train.numpy(), 'bo', label='real')
plt.plot(x_train.numpy(), y_.detach().numpy(), 'ro', label='estimated')
plt.legend()
plt.show()
drawY(y_)
loss = get_loss(y_, y_train)
loss.backward() # 反向传播
# 优化器(这里我们使用简单的 SGD)
optimizer = torch.optim.SGD([w1, b1], lr=1e-2)
for e in range(100): # 进行 100 次更新(通常更多次迭代)
y_ = linear_model(x_train)
loss = get_loss(y_, y_train)
# 手动归零梯度
w1.grad.zero_() # 记得归零梯度
b1.grad.zero_() # 记得归零梯度
loss.backward() # 反向传播
# 手动更新参数
with torch.no_grad(): # 不需要计算梯度
w1 -= 1e-2 * w1.grad
b1 -= 1e-2 * b1.grad
print('epoch: {}, loss: {}'.format(e, loss.item()))
y_ = linear_model(x_train)
drawY(y_)
然而实际上,参数点往往分布的并不规律,也不可能仅仅用wx+b就可以拟合,
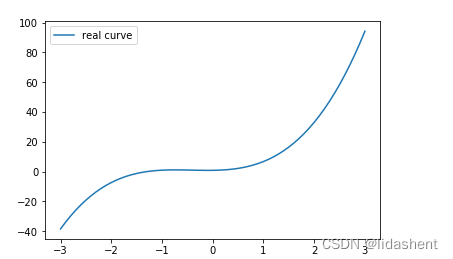
我们来设计一个新的图像
y = x+x2+x3+b
# 画出这个函数的曲线
x_sample = np.arange(-3, 3.1, 0.1)
y_sample = b_target[0] + w_target[0] * x_sample + w_target[1] * x_sample ** 2 + w_target[2] * x_sample ** 3
plt.plot(x_sample, y_sample, label='real curve')
plt.legend()
然后设置一些训练数据x和y
x为一个多行3列矩阵
x_train = np.stack([x_sample ** i for i in range(1, 4)], axis=1)
x_train = torch.from_numpy(x_train).float() # 转换成 float tensor
y_train = torch.from_numpy(y_sample).float().unsqueeze(1) # 转化成 float tensor
定义wb参数和神经网络模型,这里依旧为线性模型,损失函数,损失函数同wx+b模型依旧求平常差之和
# 定义参数和模型
w = Variable(torch.randn(3, 1), requires_grad=True)
b = Variable(torch.zeros(1), requires_grad=True)
# 将 x 和 y 转换成 Variable
x_train = Variable(x_train)
y_train = Variable(y_train)
de 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1318
1318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









