







 近期研究的BitNetb1.58展示了1-bit大语言模型的新进展,其在保持与全精度模型相近的性能同时,显著降低延迟、内存需求和能耗。通过量化、特定组件和从头训练,BitNetb1.58开启了一种新的计算范式,为低功耗AI硬件设计提供了可能。
近期研究的BitNetb1.58展示了1-bit大语言模型的新进展,其在保持与全精度模型相近的性能同时,显著降低延迟、内存需求和能耗。通过量化、特定组件和从头训练,BitNetb1.58开启了一种新的计算范式,为低功耗AI硬件设计提供了可能。
The Era of 1-bit LLMs: All Large Language Models Are in 1.58 Bits
摘要
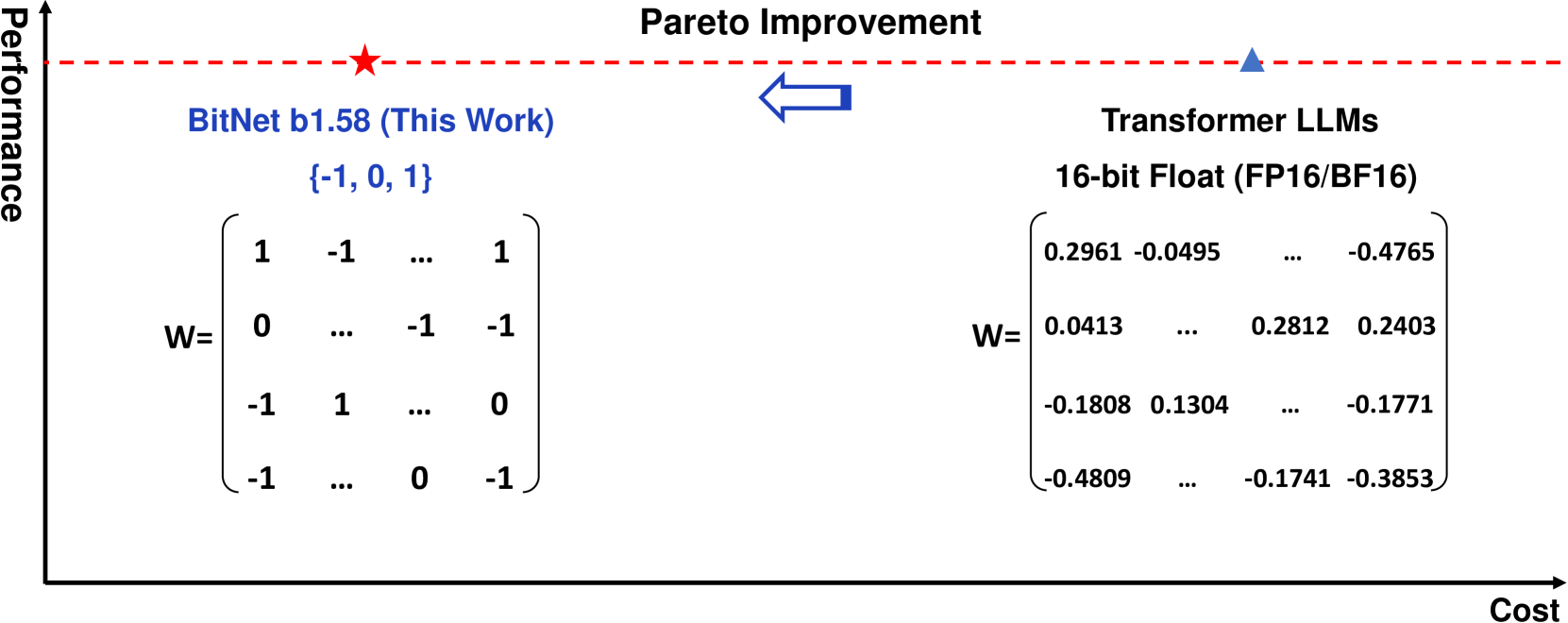
近期的研究,例如BitNet,正在为1-bit大型语言模型(LLMs)的新时代铺平道路。在本工作中,我们介绍了一个1-bit LLM的变体——BitNet b1.58,其中LLM的每一个参数(或称为权重)均为三值{-1, 0, 1}。BitNet b1.58在复杂度和末端任务性能上与同等模型大小和训练令牌的全精度(即FP16或BF16)Transformer LLM匹敌,同时在延迟、内存、吞吐量和能源消耗等方面成本更低。更深层次地,1.58-bit LLM定义了一个新的规模法则和训练新一代LLMs的配方,这些模型既高性能又具成本效益。此外,它还启用了一种新的计算范式,并为设计优化1-bit LLM的专用硬件打开了大门。
核心方法
BitNet b1.58的关键方法包括:
- 量化函数:采用绝对值均值(absmean)量化函数对权重进行约束至{-1, 0, +1},激活采用与BitNet相似的量化方式进行处理,将激活缩放到[-Q,Q]以拜托零点量化。
- LLaMA-alike组件:模型结构采用LLaMA相似的组件,如RMSNorm、SwiGLU和rotary embedding,使得BitNet b1.58容易集成到流行的开源软件。
- 从头开始训练:使用1.58-bit权重和8-bit激活,从头开始训练。
实验说明
效果对比
我们使用markdown表格形式来表示实验结果,以便于观察比较:
| Models | Size | Memory (GB)↓ | Latency (ms)↓ | PPL↓ |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2.08 (1.00x) | 1.18 (1.00x) | 12.33 |
| BitNet b1.58 | 700M | 0.80 (2.60x) | 0.96 (1.23x) | 12.87 |
| LLaMA LLM | 1.3B | 3.34 (1.00x) | 1.62 (1.00x) | 11.25 |
| LLaMA LLM | 1.3B | 1.14 (2.93x) | 0.97 (1.00x) | 11.29 |
| LLaMA LLM | 3B | 7.89(1.00x) | 5.07(1.00x) | 10.04 |
| BitNet b1.58 | 3B | 2.22(3.55x) | 1.87(2.71x) | 9.91 |
| BitNet b1.58 | 3.9B | 2.38(3.32x) | 2.11(2.40x) | 9.62 |
表格1:BitNet b1.58与LLaMA LLM在不同模型大小下的复杂度及效果对比。
| Models | Size | ARC-e | ARC-c | HellaSwag | Winogrande | PIQA | OpenbookQA | BoolQ | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54.7 | 23.0 | 37.0 | 60.0 | 20.2 | 68.9 | 54.8 | 45.5 |
| BitNet b1.58 | 700M | 51.8 | 21.4 | 35.1 | 58.2 | 20.0 | 68.1 | 55.2 | 44.3 |
| LLaMA LLM | 1.3b | 56.9 | 23.5 | 38.5 | 59.1 | 21.6 | 70.0 | 53.9 | 46.2 |
| BitNet b1.58 | 1.3B | 54.9 | 24.2 | 37.7 | 56.7 | 19.6 | 68.8 | 55.8 | 45.4 |
| LLaMA LLM | 3B | 62.1 | 25.6 | 43.3 | 61.8 | 24.6 | 72.1 | 58.2 | 49.7 |
| BitNet b1.58 | 3B | 61.4 | 28.3 | 42.9 | 61.5 | 26.6 | 71.5 | 59.3 | 50.2 |
| BitNet b1.58 | 3.9B | 64.2 | 28.7 | 44.2 | 63.5 | 24.2 | 73.2 | 60.5 | 51.2 |
表格2:BitNet b1.58与LLaMA LLM在不同终端任务中的零样本准确率对比。
这些实验中,模型在RedPajama数据集上预训练了1000亿个令牌,并在多种语言任务中评估了零拍照性能。此外,比较了BitNet b1.58和LLaMA LLM在不同模型大小下的GPU运行内存和延迟,并测量了吞吐量、能源消耗。
效率对比
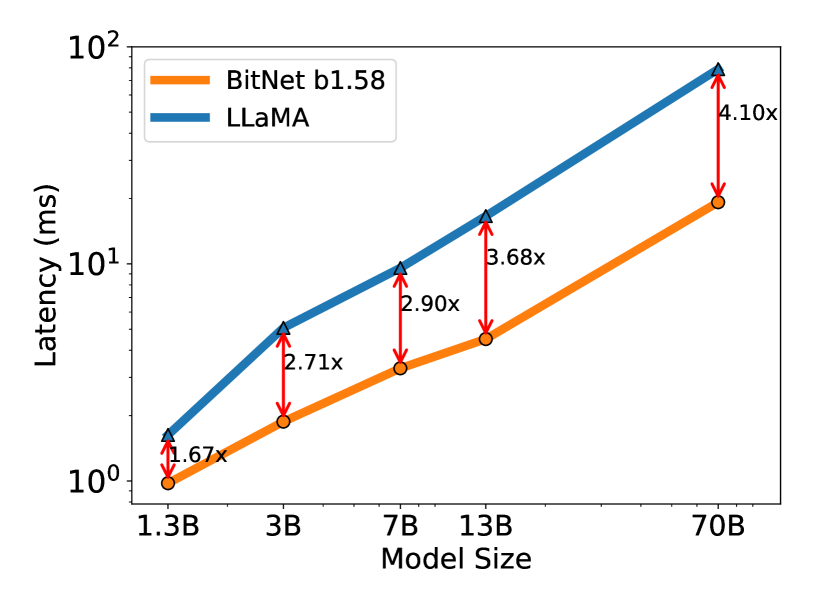
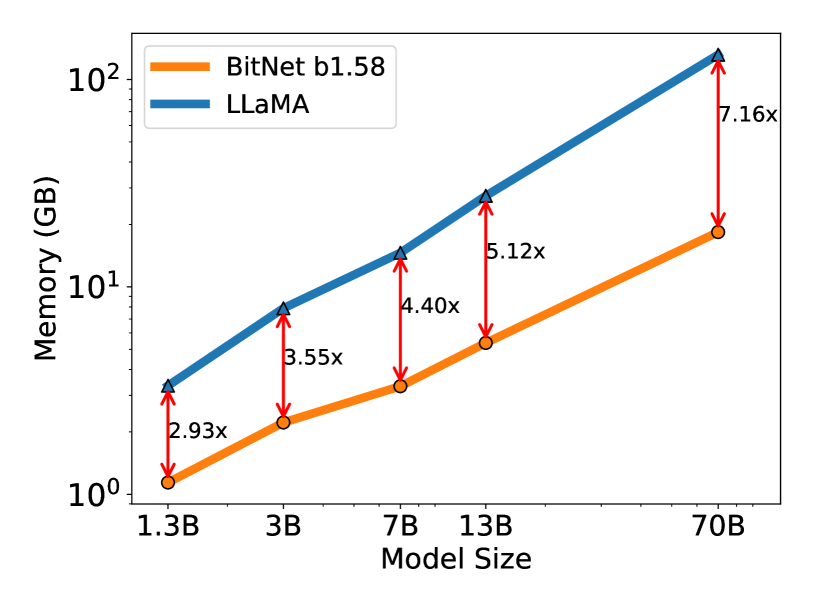
图2:解码延迟与内存消耗因模型大小而异
| Models | Size | Max Batch Size | Throughput (tokens/s) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1.0x) | 333 (1.0x) |
| BitNet b1.58 | 70B | 176 (11.0x) | 2977 (8.9x) |
| 表格3:吞吐率与batch_size的比较 |
结论
BitNet b1.58开辟了一条新的关于模型性能与推理成本的规模法则。我们可以根据结果确定,在延迟、内存使用和能耗方面,13B BitNet b1.58比3B FP16 LLM更高效,30B BitNet b1.58比7B FP16 LLM更高效,70B BitNet b1.58比13B FP16 LLM更高效。2T令牌的训练显示,BitNet b1.58在所有终端任务上优于3B模型,显示出1.58-bit LLM也具有强大的泛化能力。



















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











