








不仅需要考虑计算能力,还需要关注所用内存和 GPU
这不仅影响 GPU 推理大型模型的能力,还决定了在训练集群中总可用的 GPU 内存,从而影响能够训练的模型规模。
大模型推理的内存计算只需考虑模型权重即可。
大模型训练的内存计算往往会考虑包括模型权重、反向传播的梯度、优化器所用的内存、正向传播的激活状态内存。
接下来以ChatGLM-6B为例,它的参数设置为隐藏层神经元
数量(hidden_size)为 4096,层数(num_layers)为 28,token 长度为 2048,注意力头数
(attention heads)为 32,讲解怎么计算推理内存和训练内存。
推理内存
模型权重
- 对 int8 而言,模型内存 =1 * 参数量 (字节)
- 对 fp16 和 bf16而言,模型内存=2 * 参数量(字节)
- 对 fp32 而言,模型内存= 4 * 参数量(字节)
因为 1 GB ≈ 1B字节,也正好和1B参数量的数据量级一致,估算时就比较简单了。
所以对于一个ChatGLM-6B而言,就是:
- 对 int8 而言,模型内存=1 * 6GB=6GB
- 对 fp16 和 bf16 而言,模型内存=2 * 6GB=12GB
- 对 fp32 而言,模型内存=4 * 6GB=24GB
推理总内存
除了用于存储模型权重的内存外,在实际的前向传播过程中还会产生一些额外的开销。根据经验,这些额外开销通常控制在总内存的20%以内。
因此,推理总内存≈1.2×模型内存
训练
模型权重
可以使用纯 fp32 或纯 fp16 训练模型:
- 纯 fp32,模型内存=4 * 参数量(字节)
- 纯 fp16,模型内存=2 * 参数量(字节)
除了常规推理中讨论的模型权重数据类型,训练阶段还涉及混合精度训练。
混合精度 (fp16/bf16 + fp32), 模型内存=2 * 参数量(字节)
对于一个ChatGLM-6B而言,就是:
- 纯 fp32,模型内存=4 * 6GB=24GB
- 纯 fp16,模型内存=2 * 6GB=12GB
- 混合精度 (fp16/bf16 + fp32), 模型内存=2 * 6GB=12GB
优化器状态
- 对于纯 AdamW,优化器内存=12 * 参数量(字节)
- 对于像 bitsandbytes这样的 8 位优化器,优化器内存=6 * 参数量(字节)
- 对于含动量的类 SGD 优化器,优化器内存=8 * 参数量(字节)
对于一个ChatGLM-6B而言,就是:
- 对于纯 AdamW,优化器内存=12 * 6GB=72GB
- 对于像 bitsandbytes 这样的 8 位优化器,优化器内存=6 * 6GB=36GB
- 对于含动量的类 SGD 优化器,优化器内存=8 * 48GB=36GB
梯度
梯度可以存储为 fp32 或 fp16 (梯度数据类型通常与模型数据类型匹配。因此在 fp16 混合精度训练
中,梯度数据类型为 fp16)
- 对于 fp32,梯度内存=4 * 参数量(字节)
- 对于 fp16,梯度内存=2 * 参数量(字节)
对于一个ChatGLM-6B而言,就是:
- 对于 fp32,梯度内存=4 * 6GB=24GB
- 对于 fp16,梯度内存=2 * 6GB=12GB
激活状态
在进行LLM(大语言模型)训练时,现代GPU通常会遇到内存问题,而不是算力问题。因此,激活重计算(也称为激活检查点)变得非常流行,它是一种以计算力为代价来减少内存使用的方法。激活重计算/检查点的主要思路是重新计算某些层的激活,而不将它们存储在GPU内存中,从而降低内存使用量。具体来说,减少内存的多少取决于我们选择重新计算哪些层的激活。
接下来,假设激活数据类型为 fp16,没有使用序列并行
- 无重计算的激活内存=token 长度 * batch size * hidden layer 的神经元数量 * 层数(10+24/t+5 * a * token 长度/hidden layer 的神经元数 * t) 字节
- 选择性重计算的激活内存=token 长度 * batch size * hidden layer 的神经元数量 * 层数(10+24/t) 字节
- 全部重计算的激活内存=2 * token 长度 * batch size * hidden layer 的神经元数量 * 层数 字节
其中:
- a 是 transformer 模型中注意力头 (attention heads) 的个数
- t 是张量并行度 (如果无张量并行,则为 1)
对于一个ChatGLM-6B而言,就是:
- token 长度 * batch size * hidden layer 的神经元数量 * 层数 = 2048 * 1 * 4096 * 28 ≈ 0.23GB
- 无重计算的激活内存 = 0.23GB * (10+24/1+5 * 32 * 2048/4096 * 1) = 0.23 * 114 = 26.22G
- 选择性重计算的激活内存 = 0.23GB * (10+24/1) = 7.8G
- 全部重计算的激活内存 = 2 * 0.23GB = 0.46GB
总结
因为训练大模型时通常会采用AdamW优化器,并用混合精度训练来加速训练,所以训练一个ChatGLM-6B所需的训练总内存为:
训练总内存=模型内存+优化器内存+激活内存+梯度内存 = 12GB + 72GB + 12Gb + 7.8GB = 103GB
ChatGLM-6B使用了八台TPU v3-8
机器训练,共使用内存为 128 GB,和我们计算的基本一致。
推理总内存 ≈1.2×模型内存 = 1.2 * 12 GB = 14.4GB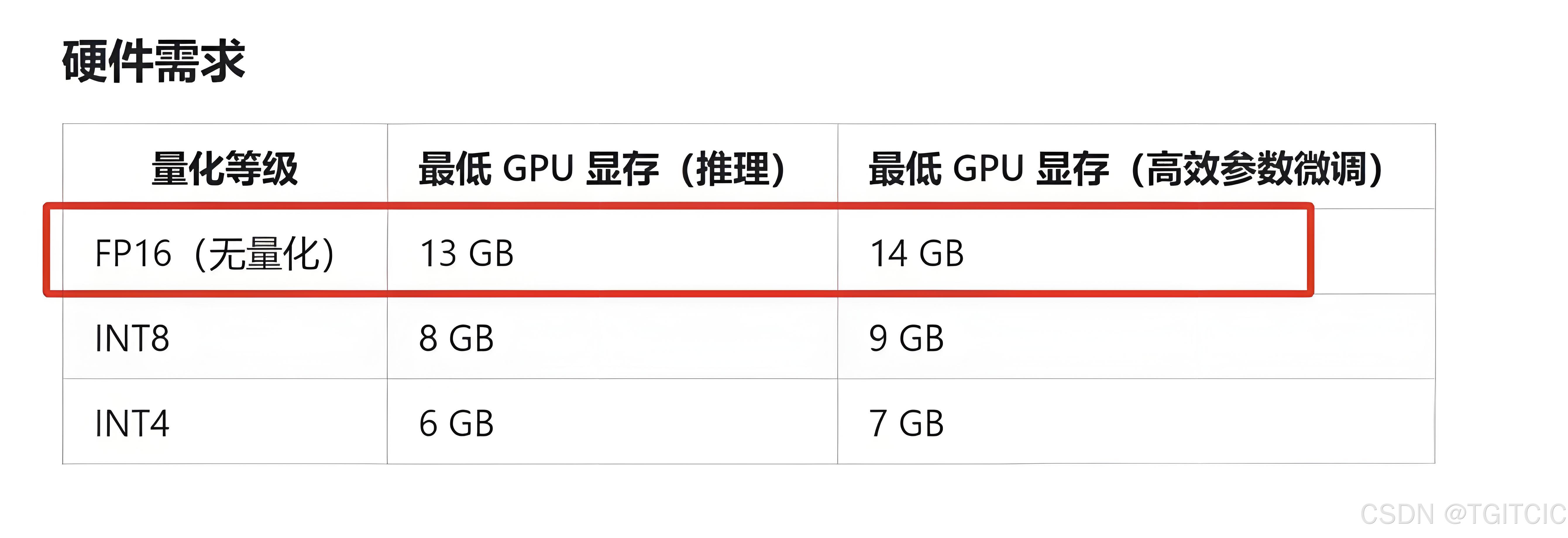
推理总内存的值基本上和ChatGLM-6B官方文档一致。


















 937
937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











