







https://arxiv.org/pdf/1909.10666.pdf
基于检索的聊天机器人的多轮响应选择的三重注意力网络
Github:https://github.com/wtma/TripleNet
论文贡献:
- 使用triple attention来建模三元输入<context、query、response>,而不是传统的<context、response>。
- 提出了一种层次表征模型,实现从字符级到上下文级的完整会话建模。
基于检索的方法从庞大的存储库中检索多个候选结果,并选择最佳的一个作为答案;基于生成的方法使用编码器解码框架来生成响应,这与机器翻译类似。
定义任务:给定上下文C、当前查询Q、候选答案R,建模预测候选答案是正确答案的概率 score = g(C, Q, R)
四个层次:context、utterances、words、characters。令C = (u1, u2, ..., ui, ..., un),其中ui代表上下文C中第i个话语utterance,n是话语的总数,最后一个话语是查询:Q = Un;每个话语ui = (w1, ..., wj , .., wm),其中wj代表表达i中第j个单词,m是单词的总数;每个单词wj = (ch1, ..., chk , .., chl),其中chk代表单词j中第k个字母,l是字母的总数。
模型结构
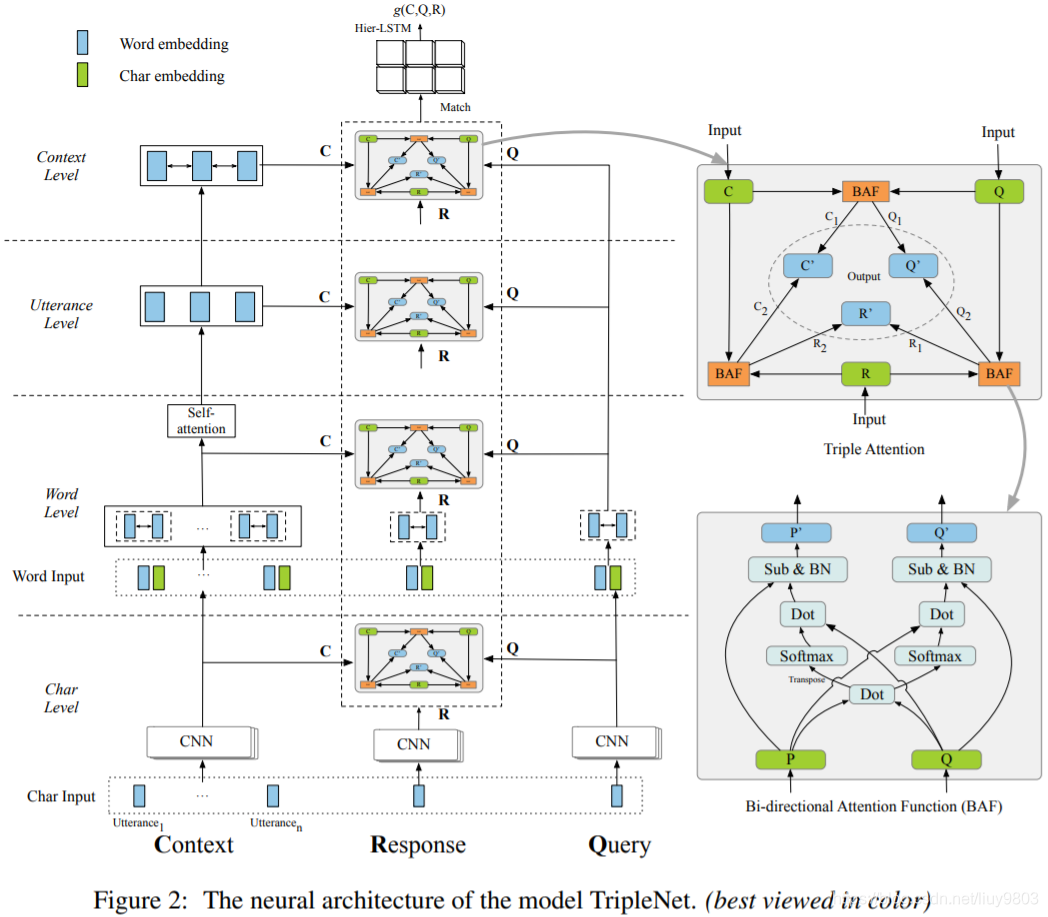
TripleNet自底向上为字符级直到上下文级,每层首先使用层次表征模块构造Q、R和Q的表征,然后用三重注意机制来更新表征,最后在关注R的同时将它们进行匹配,并融合结果做出预测。
Hierarchical Representation
(1)Char-level Representation
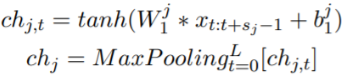
令xt:t+sj−1为embedding (xt, …, xt+sj−1)的concat,sj是第j个filter的size,使用CNN和池化得到每个单词的字符级嵌入矩阵ch。
(2)Word-level Representation
使用预训练好的词向量对词x进行嵌入,并引入词匹配特征MF,如果一个词同时出现在R和C或者Q中,MF设为1,否则设为0,使得模型对这种concurrent词更加敏感。令We为预训练的词向量,ch(x)为字符向量函数,得到词嵌入表征e(x):
![]()
使用共享的双向LSTM得到每个单词的单词级嵌入矩阵h(x)。
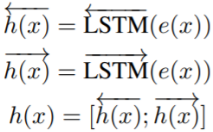
(3)Utterance-level Representation
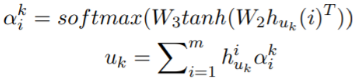
使用自注意力得到第k个话语的表征uk。
(4)Context-level Representation
![]()
将每个话语级表征输入另一个双向LSTM层中,得到第k个话语在上下文级的表征ck。
Triple Attention
BAF:双向注意力函数,计算两个序列之间的注意力并输出它们的新表征。为了建立<C, Q, R>关系的模型,将BAF应用于三者中的每一对,并为每个元素获得两个新表征,然后将它们相加作为最终表征。
对三者之间的潜在关系进行建模,将其两两输入到BAF中:
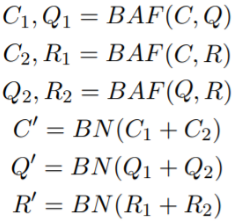
令Attpq、Attqp 为P和Q之间双向注意力,BAF对两个序列 (P, Q) 生成新的双向表征P`、Q` (Seo et al. 2016):
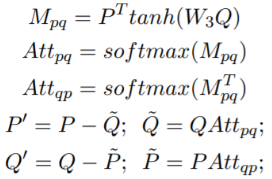
Triple Matching
使用三重注意力机制产生的表征,对每一层<C, Q, R>的余弦距离进行匹配。这时主要关注R,因为它是我们的目标。在字符级,令ch` 为三重注意力更新过的表征,得到字符级的匹配结果M1;单词级同理--得到M2;话语级和上下文级需要去掉最大池化步骤--得到M3、M4。
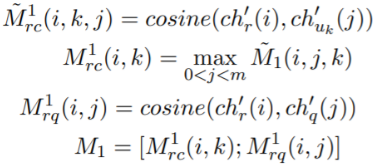
将4个结果拼接,输入层次RNN(bi-LSTM)并池化,将匹配结果编码为单个特征向量v,其中m∈M 为R中一个单词的匹配结果:
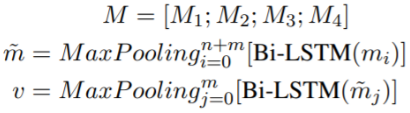
Final Prediction
可以将预测C、Q和R之间的匹配分数看作是一个二分类任务,最小化预测和真实值之间的交叉熵损失。
![]()
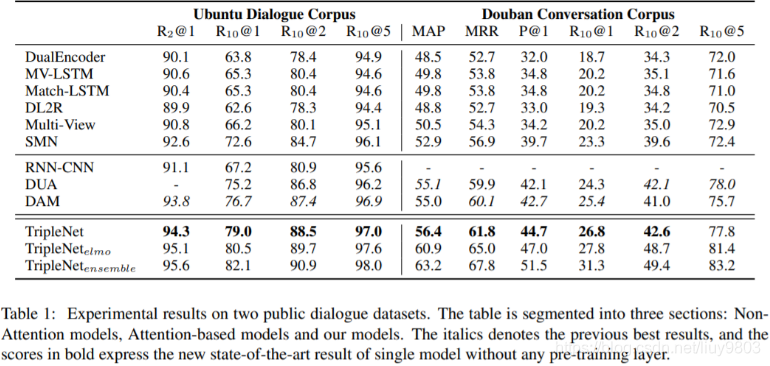
实验
多轮对话语料库:Ubuntu Corpus (Xu et al., 2017)
预训练词向量使用GloVe,字符级卷积核为尺寸为3、个数为200。所有biLSTM层的隐藏大小为200。使用Adamax优化器、初始学习率为0.002。对于集成模型,使用不同的随机种子为每个语料库生成6个模型,并通过投票合并结果。
消融实验表明层次表征和三重注意力对性能的提升都是有所贡献的。
注意力可视化(单词级别)
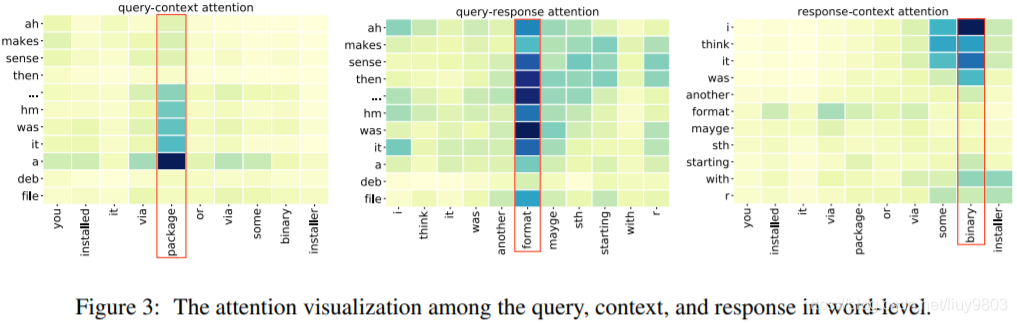
结论:
最后3个语句比其他9个语句更重要,而Query比其他任何话语都重要,因此对其单独建模要比以相同的方式处理所有12个语句的效果要好;更多地关注Query附近的话语,因为它们的重要性更高。

















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









