







 本文提出了一种名为Faithfulness Enhanced Summarization (FES) 的模型,旨在解决神经网络摘要模型在提取文档摘要时忠实度不足的问题。FES模型采用多任务学习,结合问答系统(QA)来增强编码器理解输入文档的能力,并通过最大边际损失函数防止预训练语言模型的过度拟合。实验表明,FES在CNN/DM和XSum数据集上相对于其他基准模型提高了摘要的忠实度和质量。该模型对于提高内容摘要的准确性与原文一致性具有重要意义。
本文提出了一种名为Faithfulness Enhanced Summarization (FES) 的模型,旨在解决神经网络摘要模型在提取文档摘要时忠实度不足的问题。FES模型采用多任务学习,结合问答系统(QA)来增强编码器理解输入文档的能力,并通过最大边际损失函数防止预训练语言模型的过度拟合。实验表明,FES在CNN/DM和XSum数据集上相对于其他基准模型提高了摘要的忠实度和质量。该模型对于提高内容摘要的准确性与原文一致性具有重要意义。
全文摘要:受益于预训练语言模型的发展,应用神经网络模型提取内容摘要的技术也获得了长足进步。但目前还存在一个未被很好解决的问题:神经网络模型提取的摘要不能如实反映原文档的中心思想,没有做到忠实(not faithful)。可能的原因有两个,1)摘要模型未能理解或者抓取输入文档内容的要点;2)摘要模型过度依赖语言模型,产生了流畅但不达意的词语。本文提出了一个忠实度增强摘要模型,克服上述两个问题,并尽可能贴切地表达出原文的中心思想。针对存在的第一个问题,采用QA(question-answering)来评估编码器是否完全掌握了输入文档内容,并能够回答有关输入内容中关键信息的问题。这个对正确的输入词语保持注意力的QA系统也用于规定解码器应该怎么反映输入内容源。对于第二个问题,本文引入了语言模型和摘要模型之间差异的最大边际损失函数,以防语言模型的过度拟合。在CNN/DM和XSum这两个基准数据集上的实验表明,本文提出的模型效果显著优于比较的基准模型。一致性的评估也表明本文提出的模型能得到更加贴切的内容摘要。
背景概述
研究【1,2】指出很多内容摘要模型有不能如实反映原文思想的问题。Durmus等人【3】强调了摘要不能忠于原文的两种表现形式:1)内在因素,即篡改输入文档的信息;2)外在因素,即包含原文没有阐述的信息。篡改原文常常是由于摘要模型理解错了原文档,既有可能是Encoder部分没有理解到原文的语义信息,也有可能是Decoder部分无法从Encode部分获取相关和一致性的信息。增加多余信息是由于预训练语言模型的过度注意机制,导致了生成的摘要虽然流畅却不遵从原文。例如,预训练语言模型倾向于生成常见的的短语“score the winner(记录胜利者)”,而原文中正确的短语是使用较少的“score the second highest(记录次高分者)”。这种类型的错误在当前的摘要提取任务中还没有考虑到,但在神经网络机器翻译NMT任务【4】中已经进行了研究。
基于以上观察和原因分析,本文提出了一个忠实度增强摘要模型(Faithfulness Enhanced Summarization model,FES)。为了防止篡改原文问题,忠实度增强摘要模型FES中设计了多任务学习模式,一个完成摘要提取的编解码器任务和一个基于QA系统的忠实度评估任务。QA系统增加了编码器的额外推理要求,需要对输入文档的关键语义有更全面的理解,并且能学习到比单纯的概述更好的表示。同时QA对原文中关键实体的注意力使解码器和编码器的输出一致,从而让生成的摘要保持忠实度。第二,为了处理针对原文的无中生有问题,本文提出了一个最大边际损失函数来防止预训练语言模型过度拟合。详细来说,本文定义了一个判定预训练语言模型过度程度的指标。通过最小化这个程度指标,缓解了‘摘要提取无中生有’产生内容的风险。
通过在公共数据集CNN/DM【5】和XSum【6】上的大量实验证明了本文提出的忠实度增强摘要模型FES的有效性。实验结果也表明,本文模型FES在ROUGE评分上有更好的效果,而且对比几个新闻摘要生成基线模型也提高了忠实度。
研究方法
1、问题描述
设一系列输入文档,对应的真实摘要为
。令
个问答对
和
。在训练阶段,模型的输入为问答对
、
和文档-摘要对
、
。模型最优化提取问题的答案
和生成摘要
。在测试阶段,给定文档
和问题
,推理摘要和答案。最终生成一个总结原文并与原文信息一致的摘要。
接下来,详细拆解本文提出的模型FES。该模型基于Transformer【7】,分成3个子构件。1)多任务编码multi-task Encoder:通过添加的QA系统来检测文档编码表示的质量,提高了对输入文档的语义理解。因此编码器能捕捉到关键输入信息,从而做出忠实行的内容摘要。2)QA注意力增强解码器:来自多任务编码器的注意力能使解码器与编码器对齐,以便解码器能够获取更加准确的输入信息来生成摘要。3)最大边际损失函数:这个损失函数跟模型的最后输出损失函数是正交的,只反映预训练语言模型的准确性,用于克服摘要生成过程中的预训练语言模型的过度拟合。
2、多任务编码器
在摘要提取和QA联合训练阶段,多任务编码器对输入文档进行编码(图1(b))。不同于此前研究【2,3】将QA系统用于后处理来评估生成摘要的忠实度(图1(a))。本文让QA系统更接近编码器,并让编码器同时完成QA和内容摘要任务的训练。这种多任务编码器的联合训练,除了考虑摘要生成的质量,也将忠实度作为训练优化目标。QA系统中的答案来自输入文档中的关键实体,因此QA问答对能注意到输入文档中的关键信息。
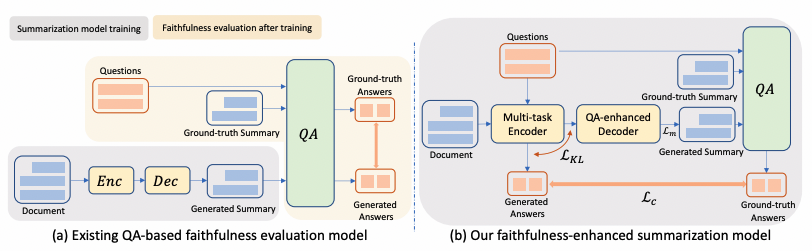
图1
如下图2所示,本文采用经典的Transformer体系结构获取文档和问题
的token级别表示,记为
和
,其中
表示文档中的token数目,
表示问题数目,
表示一个问题中的token数目,
表示特征维度数。最终的编码器能从实体级、句子级、问题级理解问题和输入文档。
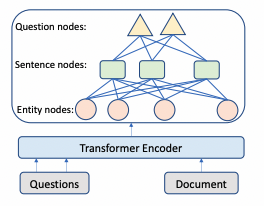
图2
本文通过不同的粒度表示学习来构建编码器。实体包含紧密和显著的文档信息,也是阅读理解问答的主要关注点,所以本文采用实体作为基本语义单元。由于每个问题一般很短,所以每个问题都会创建一个节点。从问题到句子和从句子到实体也都构建了双向边。这些节点作为句子与句子间的中介,丰富了跨句子间的关系。初始的有向边不足以学习到反向信息,本文添加了反向边和自环边。采用标记token级和词跨度级的均值池化处理来初始化节点表示【8】。给定构建好包含节点特征的图,本文用图注意力网络&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 413
413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









