










本文英文原文由本人在个人博客发表于2024年2月1日。在此我们在AI翻译的基础上做了少量编辑。点击“阅读原文“或者复制以下原文链接到浏览器即可浏览原文。
原文链接: https://harrywang.me/gpt-labeling
摘要
数据标注是大语言模型(LLMs)的一个重要应用。在这篇文章中,我将分享使用ChatGPT(API版本3.5和4)进行Aspect-Based Sentiment Analysis(ABSA)即基于方面的情感分析之后获得的一些见解和知识。我选择ABSA作为示例,是因为它是一个具有挑战性的任务,并且我之前在没有依赖LLMs的情况下,已经在一些研究和行业项目中处理过类似任务。例如,我的团队曾经训练并提供了一个基于BERT的ABSA 模型,您可以通过以下链接访问。
https://huggingface.co/tezign/BERT-LSTM-based-ABSA
本文的关键要点:
-
LLMs可以有效地执行数据标注任务,其表现水平类似于人类,且无需人工数据标注和模型训练,从而可能节省时间和成本。
-
使用 GPT4 来标注 200 万条评论,配合使用长的 few-shot 提示词,大约花费$30K。
-
Supervised Fine-tuning(SFT)即监督微调,更便宜且更快,但性能远不如 GPT4(注意:这可能是由于微调数据的问题 – 这边没有花太多时间调整微调数据集)。
主要议题包括:
-
不同的标注过程:人工 vs. 基于LLM
-
不同的方法(提示词工程 vs. 小批量处理 vs. 微调)及其时间/成本影响
-
不同方法的性能比较
ABSA任务和数据集
基于方面的情感分析(ABSA)是一项自然语言处理任务,旨在识别和提取产品或服务特定方面的情感。在这个领域有许多论文、数据集和比赛(参见https://paperswithcode.com/task/aspect-based-sentiment-analysis)。
例如,以下是一条餐厅评论,其中包含四个方面的情感(参见此repo:https://github.com/harrywang/openai-api-starter来获取一个简单的代码示例):
这个地方非常酷,装饰也很棒。饮料还可以,但有点贵。
-
氛围:正面
-
食物:中性
-
价格:负面
-
服务:未提及
我们为一个研究项目创建了一个酒店评论的ABSA数据集,该数据集包含大约200万条酒店评论,涉及三个方面:
-
员工服务
-
服务机器人的服务
-
人机互动
我们雇用了数据标注员手动标注了约2.5万条评论,并训练了一个模型来标注其余的数据集。
传统过程
一个ABSA任务通常包括以下步骤:
-
手动标注一部分数据,分两步进行:首先定义方向,然后标注相应的情感。检查标注的一致性,如果人手不够则需要更多的标注员。
-
使用标注的数据训练一个模型并检查性能(如有需要则标注更多数据)。
-
使用训练好的模型预测其余的数据。
这个过程非常耗费人力和成本,例如,我们手动标注了约2.5万条评论,几位标注员花了几周时间完成。
基于LLM的过程:
使用LLM进行ABSA的过程如下:
-
手动标注一个小的测试数据集,例如几百条评论。
-
编写一个few-shot标注提示词(详见下文)并标注100条评论。
-
审查初步的标注结果,将任何错误标注的示例,特别是有挑战性的案例,作为补充示例加入few-shot提示词。根据需要重复此过程。
-
使用最终提示词标注其余的数据集。
提示词工程
提示词按照之前概述的步骤构建,最终如下所示:
You are an experienced data labeling engineer with extensive experience in labeling hotel reviews. Your task is to classify a review based on three dimensions, with four categories: positive, negative, neutral, and not mentioned.`` ``The definitions and examples of the three dimensions are as follows:`` ``Dimension 1: Quality of hotel staff service`` ``Definition: customer perceptions directly related to staff behavior or attitude, such as timely service, skilled, knowledgeable, professional, polite, caring, understanding, sincere, helpful, etc.`` ``Examples:`` ``Review: The cleaning lady cleans in a timely manner.``Sentiment: Positive`` ``Review: Staff were testing robots in the hallway, the noise was very loud and annoying, and the front desk did nothing about it!``Sentiment: Negative`` ``[more examples]...`` `` ``Dimension 2: Quality of robot service`` ``Definition: customer perceptions of robot functionality or perceptions of the service result after using the robot`` ``Examples:`` ``Review: The robot is very convenient``Sentiment: Positive`` ``Review: The robot delivers too slowly``Sentiment: Negative`` ``[more examples]...`` ``Dimension 3: Human-robot interaction perception`` ``Definition: customer perceptions other than robot functionality, such as robot social intelligence (communication understanding ability), robot social existence (making one feel it has human characteristics or experiences a human can bring), robot design and novelty (voice, and posture freshness, curiosity, advanced, coolness.`` ``Examples:`` ``Review: The little robot speaks adorably, too cute``Sentiment: Positive`` ``Review: The robot's voice is too loud and noisy;``Sentiment: Negative`` ``[more examples]...`` `` ``Now, classify the sentiment of the following review into three dimensions using a JSON object as the output method, with "employee_service", "robot_service", "human_robot_interaction" as the keys and the value is one of positive/negative/neutral/unknown.`` ``Here is the hotel review:
性能比较
最新的API定价如下(GPT4大约是GPT3.5的20倍贵,但是 OpenAI现在最新的GPT-4o的比之前的GPT4便宜了一半):

上述提示词相当长(在此我们使用了tiktoken来计算token数量),大约1400个token。连同实际评论,输入OpenAI API大约1500个token。
所以,标注一条评论的成本大致如下(考虑到输出很短,我们可以忽略输出的成本估计):
-
GPT-4:$0.015
-
GPT-3.5:$0.00075
-
GPT-4o:$0.0075
对于200万条评论,总成本如下:
-
GPT-4:$30K美元 —— 相当贵!
-
GPT-3.5:$1.5K美元
-
GPT-4o:$15K美元
为了降低成本,我们尝试了以下方法:
-
小批量处理:将100条评论(而不是1条)附加到提示词中,以减少API调用的总次数。注意:如果每批次放入太多评论,输出可能会超过最大4096个token。
-
监督微调(SFT):尝试使用100条评论微调GPT 3.5,去掉上述few-shot提示词中的示例以减少输入token(从约1500减少到约500)。
然而,小批量处理和SFT的标注性能都要差得多,如下所示。

不同方法标注100条评论的时间如下:
-
~ 5分31秒用于100次单独API调用
-
~ 6分19秒用于1个批次100条评论
-
~ 1分28秒用于使用简短提示词的微调模型进行100次单独API调用(快得多)
总之,GPT 4在ABSA任务中表现良好,但可能很昂贵。SFT方法似乎更便宜和更快,但性能需要改进,例如准备好质量更高的数据集和数据工程。
PS. 本文的配图是使用DALLE 3生成的。
塔金AI(takin.ai)是生成式AI教育领域的引领者, 将生成式AI技术融入教育,为学习者、教育工作者以及教育爱好者带来卓越的教育体验与前沿洞察。
题外话
黑客&网络安全如何学习
今天只要你给我的文章点赞,我私藏的网安学习资料一样免费共享给你们,来看看有哪些东西。
1.学习路线图
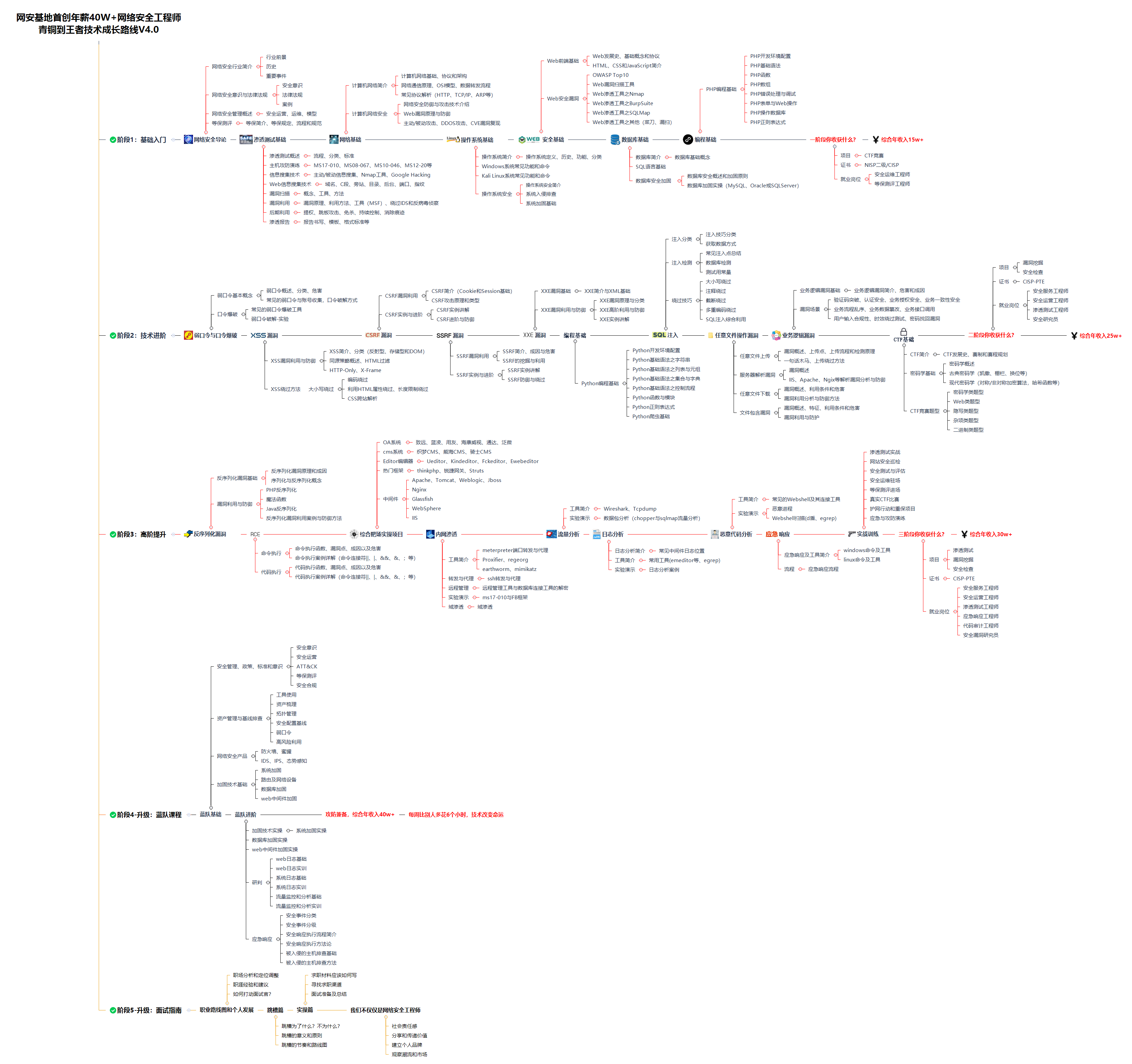
攻击和防守要学的东西也不少,具体要学的东西我都写在了上面的路线图,如果你能学完它们,你去就业和接私活完全没有问题。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己录的网安视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
内容涵盖了网络安全法学习、网络安全运营等保测评、渗透测试基础、漏洞详解、计算机基础知识等,都是网络安全入门必知必会的学习内容。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
3.技术文档和电子书
技术文档也是我自己整理的,包括我参加大型网安行动、CTF和挖SRC漏洞的经验和技术要点,电子书也有200多本,由于内容的敏感性,我就不一一展示了。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
4.工具包、面试题和源码
“工欲善其事必先利其器”我为大家总结出了最受欢迎的几十款款黑客工具。涉及范围主要集中在 信息收集、Android黑客工具、自动化工具、网络钓鱼等,感兴趣的同学不容错过。
还有我视频里讲的案例源码和对应的工具包,需要的话也可以拿走。
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
最后就是我这几年整理的网安方面的面试题,如果你是要找网安方面的工作,它们绝对能帮你大忙。
这些题目都是大家在面试深信服、奇安信、腾讯或者其它大厂面试时经常遇到的,如果大家有好的题目或者好的见解欢迎分享。
参考解析:深信服官网、奇安信官网、Freebuf、csdn等
内容特点:条理清晰,含图像化表示更加易懂。
内容概要:包括 内网、操作系统、协议、渗透测试、安服、漏洞、注入、XSS、CSRF、SSRF、文件上传、文件下载、文件包含、XXE、逻辑漏洞、工具、SQLmap、NMAP、BP、MSF…

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
🐵这些东西我都可以免费分享给大家,需要的可以点这里自取👉:网安入门到进阶资源
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。

















 2982
2982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









