









文章目录
前面在介绍DETR时提到,DETR在小目标检测上不友好,而且DETR由于是在特征图上进行全局的self-attention 所以计算量很大,十分耗时间。那怎么解决上面两个问题?
1、小目标检测:首先想到的就是多尺度检测。
2、全局的self-attention 耗时问题:能不能使用局部特征的self-attention?
self-attention
O = s o f t m a x ( Q ∗ K T / d k ) ∗ V O = softmax(Q*K^T / \sqrt{d_k}) * V O=softmax(Q∗KT/dk)∗V
对于某个输入
x
x
x, 相对某个query
z
q
z_q
zq 多头注意力如下:
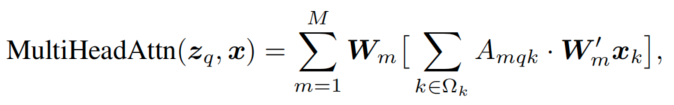
A m q k A_{mqk} Amqk 则是在k处的attention weight, 通过 Q K T Q K^T QKT计算得到, W m ‘ x k W^`_mx_k Wm‘xk则是value。从公式可以看到,任意一个 x x x都要遍历整个K空间。如果把K空间变成局部空间,那么就能简化计算。
deformable attention
deformable 来源deformable convolution可变形卷积。标准卷积选择周围n * n固定区域计算,可变形卷积在标准区域位置上增加偏移offset(offset 通过学习得到),这样卷积核在训练中可以有很大范围扩展。
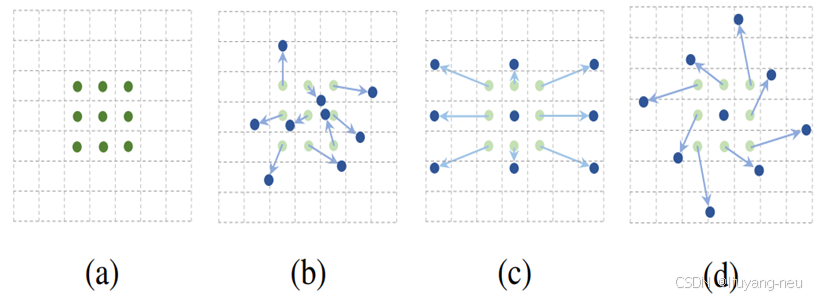
具体实现如下图所示:
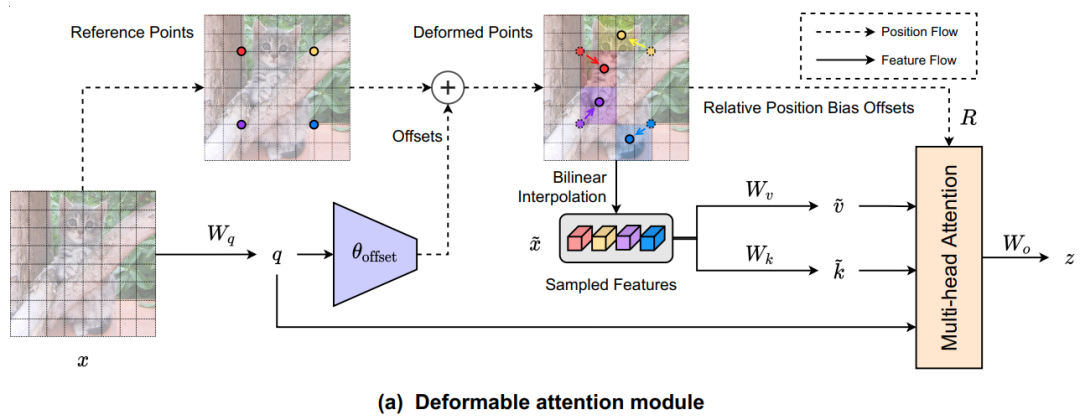
将当前特征x作为动态偏移网络输入,生成offset, 再根据offset + 原来参考点位置提取特征, 经过
W
k
,
W
v
W_k, W_v
Wk,Wv获得 局部的k,v(k,v在数量上相等)x 经过
W
q
W_q
Wq作为q, 得到q,k,v送入 attention网络, 得到稀疏的动态局部自注意力输出。
用公式描述如下:
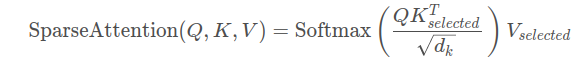
所以deformable attention 的网络结构图如下:
1、将输入向量转换成特征图,然后生成Query向量,同时考虑参考点的坐标;
2、将输入特征图在线性变换后与Query向量一同输入到偏移模块中
3、将偏移模块产出的结果与Query向量输入到注意力模块中得到最终结果。
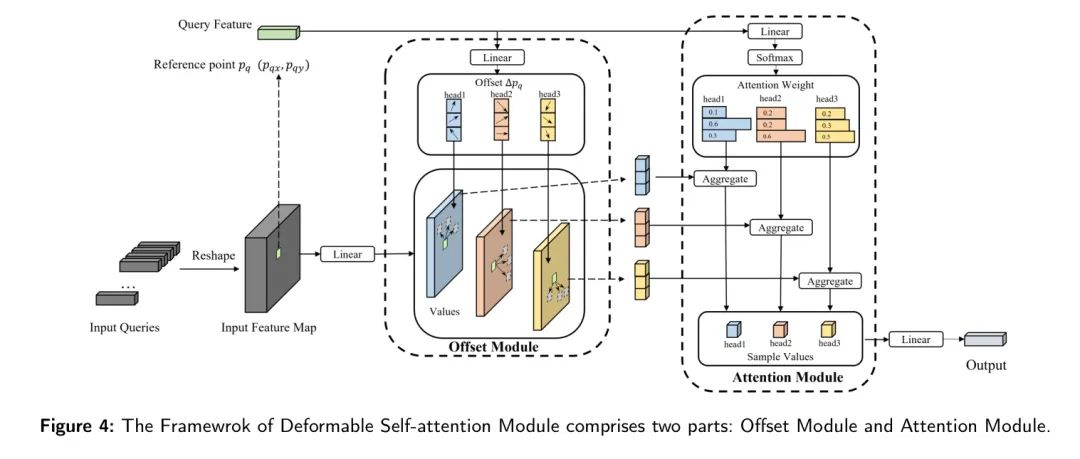
将当前参考点特征x作为动态偏移网络输入,生成K个动态offset, 和对应的K个attention weight。
对于单一尺度的可变形多头注意力,用公式描述如下:
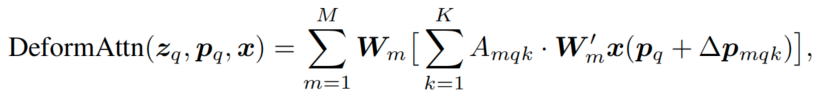
z
q
z_q
zq 为query 特征,
P
q
P_q
Pq 为当前位置,
x
x
x 为value,
Δ
p
m
q
k
\Delta p_{mqk}
Δpmqk表示第m个注意力头第k个采样点相对于参考点的位置偏移; K是采样的key总数.
从生成自注意力从表达式看,与全局自注意力几乎差不多。只是 x k x_k xk 变成了( p q + Δ p m q k p_q + \Delta{p_{mqk}} pq+Δpmqk)其实就是referece point + offset的形式。 A m q k A_{mqk} Amqk 就是第K个attention weight, 作用在对应选点的特征上。
可以看到,每个query在每个头部中采样K个位置,只需和这些位置的特征交互 x ( p q + Δ q m q k ) x(p_q+\Delta q_{mqk}) x(pq+Δqmqk)即可。
最后将多头自注意力输出concat得到最终的向量.
deformable DETR
我们回到DETR中,
怎么获取offset?
假设我们只需要K个局部参考点:K << HW 。
那么:用query计算出K个offset,然后和参考点相加,进行双线性差值对应到
x
k
x_k
xk上,算出K个“关注点的坐标”,迫使模型只focus在这K个点上,而不是整个feature map H*W个点。
DETR 与 deformable DETR 结构对比如下:
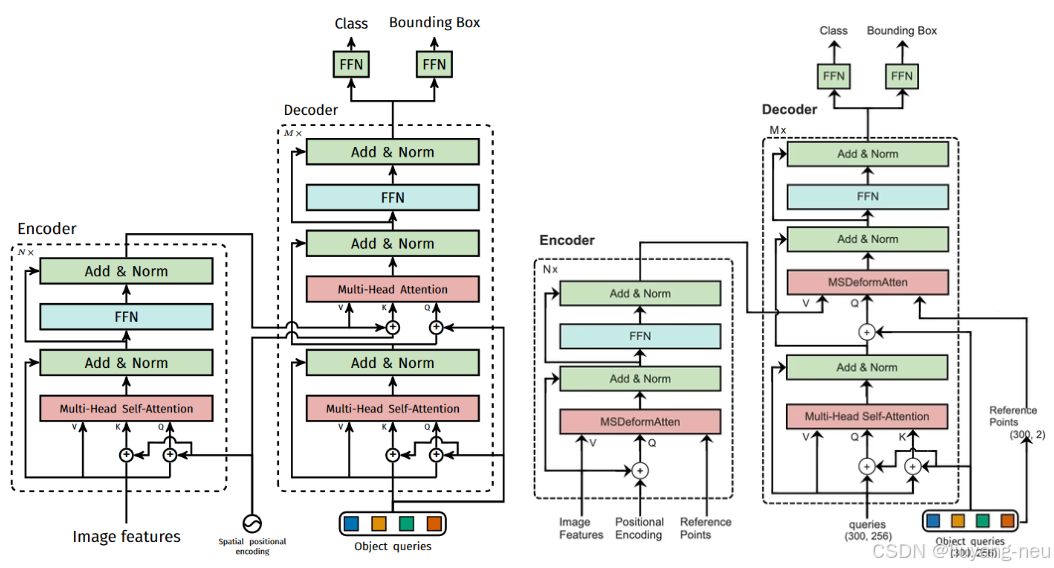
可以看到deformable DETR 相比 DETR 只是在encoder 的 self-attention 和 decoder 的第二个 attention(其实这两个结构是一样的)中添加可学习的位置偏移量offset代替原始的Key。
multi-scale deformable attention
构建多尺度特征图,然后在每个尺度上进行deformable attention。
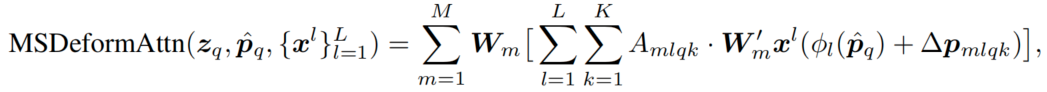 1、先将特征图进行堆叠(L个scale的feature map堆叠在一起)。
1、先将特征图进行堆叠(L个scale的feature map堆叠在一起)。
2、每个特征图上采样K个点。这个和single-scale的时候没什么区别。
这样就获得多尺度的采样点。
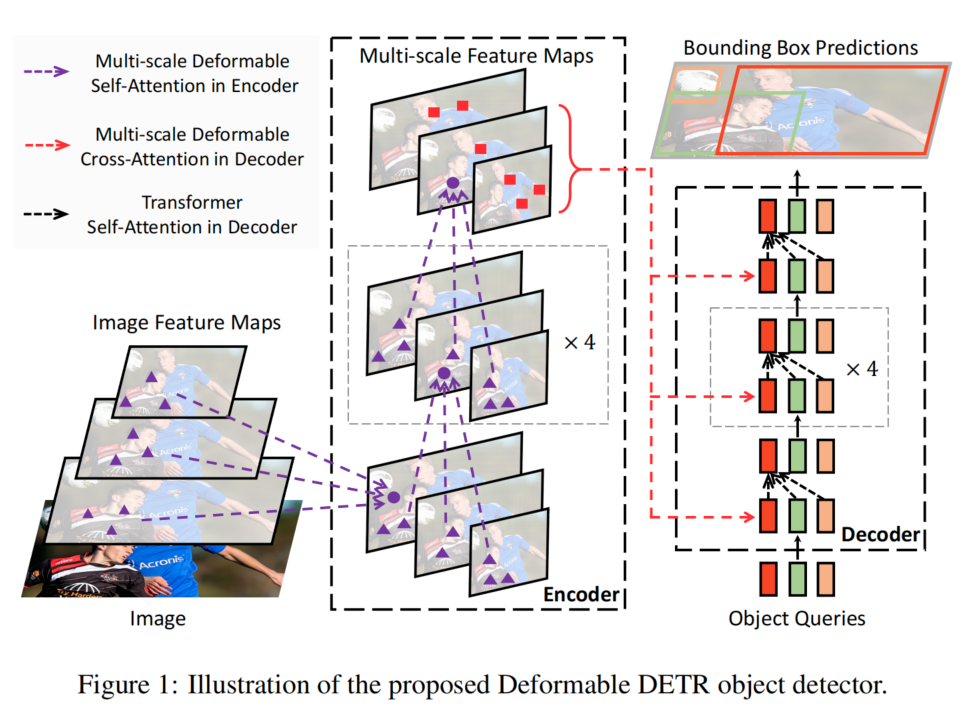
backbone 生成多尺度特征
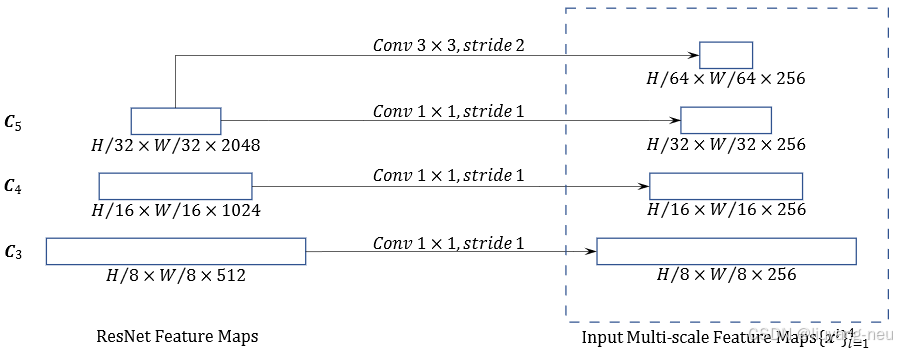
多尺度特征位置编码
生成的多尺度特征会被concat连接在一起。
 对于多尺度特征,不能采用单一尺度的位置编码,因为不同尺度的特征中,位于相同位置(x、y)坐标的位置会产生相同的位置编码。没有体现出尺度特征的差异性。所以引入level_embedding,先在不同层有不同的level_embed,然后== level_embed + pos_embed ==作为 最后的多尺度位置编码。
对于多尺度特征,不能采用单一尺度的位置编码,因为不同尺度的特征中,位于相同位置(x、y)坐标的位置会产生相同的位置编码。没有体现出尺度特征的差异性。所以引入level_embedding,先在不同层有不同的level_embed,然后== level_embed + pos_embed ==作为 最后的多尺度位置编码。
此外,不同于三角函数那种固定地利用公式计算出来的编码方式,这个scale-level embedding是随机初始化并且是随网络一起训练的、是可学习的。
Head 预测
分类头:FFN 后预测query 对应的目标类别
回归头:由于对参考点引入了offset,将参考点与偏移量相加作为边界框预测,降低优化难度。
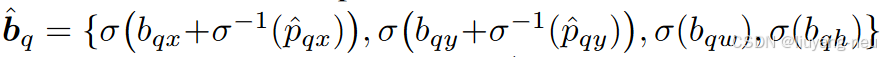
(
p
q
^
=
(
p
q
x
^
,
p
q
y
^
\hat{p_{q}} = (\hat{p_{qx}}, \hat{p_{qy}}
pq^=(pqx^,pqy^)表示参考点,
b
q
(
x
,
y
,
w
,
h
)
b_{q(x,y,w,h)}
bq(x,y,w,h)表示相对参考点偏移。在进行归一化相加后作为最后边界框预测输出。
效果
与DETR-DC5比,相同性能训练速度快10倍,小目标AP提升4个点。

















 2017
2017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









