






源自:计算机应用 作者:刘睿珩, 叶霞, 岳增营 “人工智能技术与咨询” 发布
摘 要
近年来,深度学习技术得到了快速发展。在自然语言处理(NLP)任务中,随着文本表征技术从词级上升到了文档级,利用大规模语料库进行无监督预训练的方式已被证明能够有效提高模型在下游任务中的性能。首先,根据文本特征提取技术的发展,从词级和文档级对典型的模型进行了分析;其次,从预训练目标任务和下游应用两个阶段,分析了当前预训练模型的研究现状,并对代表性的模型特点进行了梳理和归纳;最后,总结了当前预训练模型发展所面临的主要挑战并提出了对未来的展望。
关键词
自然语言处理;预训练模型;深度学习;无监督学习;神经网络
引 言
自然语言处理(Natural Language Processing,NLP)的研究结合了人工智能、语言学和数学等领域的相关知识,旨在让机器能够理解人类的语言。近年来,随着人工智能领域飞速发展,特别是在深度学习技术的支持下,NLP的发展取得了巨大的进步,其任务的划分也更加细致,如词性标注、文本分类、情感分析、机器翻译、共指消解等。在这些任务中,预训练技术的发展起到了至关重要的作用。
预训练模型为解决深度神经网络中大规模参数学习问题提供了一种有效的方案,这种方法最早使用在计算机视觉(Computer Vision,CV)领域,其核心思想是先在大数据集上对深层次的神经网络进行预训练得到模型参数,然后将这些训练好的模型运用到各种具体的下游任务以避免从头开始训练并且减少对标注数据的需要,结果表明,模型的性能得到了显著提高。随着NLP 领域研究的不断深入,在大型语料库上进行预训练也被证明能够有助于下游任务。
预训练技术在本质上运用了迁移学习[1]的思想,将在相关领域数据集中学习到的先验语言知识,迁移到目标领域,以改进不同目标任务的学习效果。在现代自然语言处理任务中,用大规模语料库进行无监督训练得到的词的分布式表示[2-3]被广泛使用,其中以Word2Vec(Word to Vector)[2]为典型代表的方法实现了在低维条件下用稠密向量对词进行表示,降低了计算成本的同时提高了表示精度。但是这种方法仅对词进行单个全局表示,提取浅层文本表征,却忽略了它们的上下文,因此无法在不同语境下对词的句法和语义特征进行有效表示。随后ELMo(Embeddings from Language Model)[4]采用双向长短期记忆(Long Short-Term Memory,LSTM)网络对语言模型实现了基于上下文的词嵌入表示,并显著提高了模型在下游任务的性能。直到Google 在Transformer[5]中引入了注意力机制,为之后的 BERT(Bidirectional Encoder Representations from Transformers)[6]和GPT(Generative Pre-Training)[7]等深层次预训练模型的出现奠定了重要基础,使得预训练技术的发展迎来了一个高潮。自此,NLP 任务已经越来越离不开预训练技术。
1 文本特征提取技术的发展
预训练技术是利用大型语料库学习通用语义表示的新方法,其核心离不开语义表示技术的发展。传统的基于词袋模型的文本特征提取方法,如One-Hot 编码对词进行符号化处理,即用数字编码来表示词语,在其向量表示中只有一个维度上的值为1,其余各维均是0。该方法虽然能够简单稳定地提取词特征,但无法表示词与词之间的相对位置关系,并且产生很高的词向量维数导致表示非常稀疏,同时还无法涵盖有效的语义信息,不能体现词之间的语义相似度;n-gram 算法和共现矩阵的出现虽然缓解了区分词序的问题,但还是面临着维数灾难所带来的计算量过大的困扰。随着统计方法、神经网络模型在自然语言处理任务中的应用,分布式假说为进一步优化文本特征提取方法提供了新的理论基础,通过结合神经网络和语言模型,词的分布式表示使得许多NLP 任务取得了巨大的突破。
本章将文本特征提取技术的发展大致划分为两个阶段:词级表示和文档级表示,不同之处在于其产生的词向量是否能够根据上下文语境的变化而动态改变。
1.1 词级表示
词级表示作为一种词的分布式表示方法,通过描述目标词与其邻近词之间的关系从而建立模型,从而包含更加丰富的语义信息。
为解决One-Hot 编码产生的维度灾难等诸多问题,起初的做法是设计一个窗口,根据窗口大小罗列出所有单词的组合关系;然后统计每个组合关系在语料库中出现的次数;最终通过一个矩阵来存储单词之间的共现关系。由于共现矩阵的维度依然受到语料库中句子长度的影响,因此考虑采用奇异值分解(Singular Value Decomposition,SVD)的方法对遍历语料库后得到的共现矩阵进行处理,通过选择部分奇异向量提取子矩阵,从而实现维度的降低。但这种方法也面临着许多问题:一方面,共现矩阵的维度往往会随着语料库大小的变化而变化,不易进行统一处理;另一方面,由于语料库中的大部分词并不存在共现关系,从而导致共现矩阵非常稀疏,而SVD方法的计算复杂度一般较高,使得处理矩阵的效率十分低下。
神经网络语言模型(Neural Network Language Model,NNLM)[8]将语言模型与神经网络相结合。一方面,通过n-gram 方法对输入语言模型的长文本信息进行简化处理,使得在对条件概率进行估算时,忽略距离长度大于n 的词信息。同时,不同于传统语言模型,它在词语表示上采用低维词向量来代替One-Hot 向量,因此当遇到语义相近的上文信息时,该模型依然能够对目标词进行相似的预测。另一方面,该方法将各词词向量按照顺序进行拼接,并直接送入前馈神经网络,保留了一定的顺序信息。
由于NNLM 在前馈神经网络中使用了全连接结构,因此只能处理定长的文本信息。针对此问题,循环神经网络语言模 型(Recurrent Neural Network based Language Model,RNNLM)[9-10]不再使用n-gram 方法对语言模型进行简化,而是采用循环神经网络(Recurrent Neural Network,RNN)替代前馈神经网络,并直接优化语言模型条件概率。在预测目标词时通过迭代的方式获取所有上文信息,使得模型能够处理长度变化的文本序列。除此之外,该方法相较于NNLM 还能够获取更为丰富的上文信息。
在之前的研究中,由于语言模型的引入,神经网络训练的目标始终为预测词概率分布最大化,因此词向量仅仅是一种副产物。不同于NNLM 和RNNLM 的方法,C&W 模型[11]不再采用语言模型的条件概率思想,而是直接以学习和优化词向量为目标,为了更快地得到词向量,该方法根据短语出现的频率,通过打分的方式评价每一个n 元短语,并最大化正例和反例的得分差。因此,避免了复杂的条件概率和归一化计算,具有更低的时间计算复杂度。Word2Vec 在前期工作的基础上,采用分布式思想并利用浅层神经网络从大规模无标注数据集中学习词向量表示,在缩短了计算时间的同时获得了更好的句法规则和细粒度语义。该方法主要包含Continuous Bag-Of-Words(CBOW)和Skip-Gram(SG)两种算法,如图1所示。
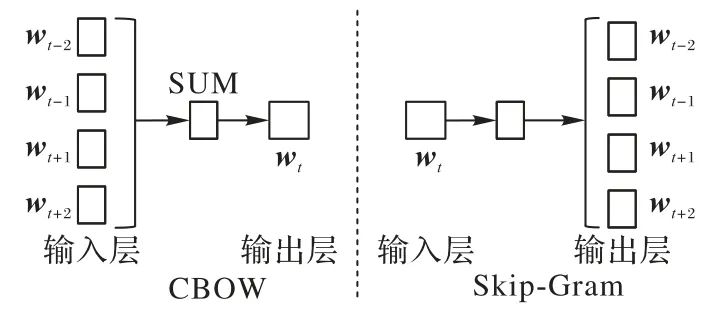
图1 Word2Vec模型结构
CBOW 采用了类似NNLM 的方法,其核心思想是根据中心词附近的上下文词来预测中心词的词向量,即先输入上下文词向量,然后在中间层进行简单的向量求和,最后再输出最有可能的词向量。SG 与CBOW 类似,是根据中心词来预测其周围上下文词的词向量。与之前基于神经网络的模型相比,这两种算法简化了模型架构中的隐藏层,大大提高了模型的计算速率,除此之外,在预测目标词时两种算法还融入了周围词语的信息,考虑了上下文环境。
在训练方法上,为解决输出层Softmax 计算开销过大问题,采取了负采样(Negative Sampling)和层级Softmax(Hierarchical Softmax)[12]两种方式。负采样方法结合了C&W模型中建立负样本和基于向量的逆语言模型(inverse vector Log-Bilinear Language model,ivLBL)[13]中的噪声对比评估方法。首先通过计算与中心词的余弦相似度,从上下文中确定正样本;然后在语料库中根据词频从非上下文中选取负样本,最后设计了一个最优函数,使正样本似然函数达到最大的同时,负样本似然函数达到最小,通过利用这种负采样方法产生的新数据集,使得归一化概率分布的计算得到了大幅简化。由于传统的Softmax 函数在对归一化项进行处理时需要计算每个分量的值,因此占用了大量的计算资源,层级Softmax[12]本质上作为一种近似于Softmax 的方法,通过构造一种类似于哈夫曼树的结构,减少了每个分量概率值的计算次数,降低计算复杂度的量级,从而节约了计算时间。
Word2Vec 实现了词向量的低维稠密表示,不仅包含了更丰富的语义信息,同时还具有较高的计算速率,有效地提升下游任务的性能,此后很多模型都受到了它的启发,如用于文本分类和词向量生成的Fast-Text[14],它除了能在保持高精度的条件下快速实现文本分类,还能完成词向量学习任务。该模型采用一种类似于CBOW 的模型架构,利用上下文信息来预测标签,但其不同之处在于,Word2Vec 中的每个单词拥有一个独立的词向量表示,在处理稀有词和生词时,语料库中的相关词语信息便很少或者不存在,因此对于这类词向量的生成存在困难,而Fast-Text 通过采用n-gram 的方法可以从其他单词的共享部分中构造稀有词或者生词的词向量表示,同时这种关联相邻词语的方法还能在模型训练时融入词序信息,从而提升词向量的表示效果。为了提升模型的运算效率,Fast-Text 同样采用层级Softmax 的方法对标签进行编码,以减少模型预测的标签数量。
虽然Word2Vec在预测中心词时能够考虑到上下文环境,但是这种上下文信息仅仅是局部的,很难结合文本的全局特征。针对这个问题,不同于基于神经网络架构的模型,GloVe(Global Vectors for word representation)[3]采用基于矩阵的统计建模方法,首先遍历整个语料库得到共现矩阵以表示词与词之间的相关性;然后在对共现矩阵进行降维重构时,只考虑共现次数非零的元素,同时在任务设计上对矩阵中的行和列加入了偏移项,并通过设计加权函数遏制低频共现词产生的噪声影响。相较于Word2Vec,该方法的速度更快,并且由于结合了全局文本特征,产生的词向量表示能够包含更多的语义信息,如表1 所示,GloVe 在单词类比、命名实体识别、单词相似性判断等任务上与三种在共现矩阵降维上采取不同策略的SVD方法,以及Word2Vec中的两种方法相比有明显的提升。
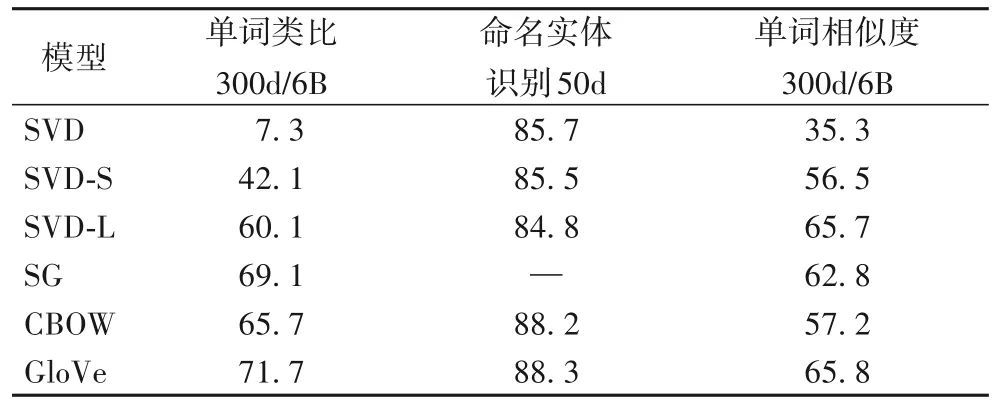
表1 GloVe与其他模型在不同任务上的实验结果对比 单位:%
注:300d/6B表示训练在标记数量为6B的语料库上进行,且向量维度为300;50d表示向量维度为50。
词级表示的方法在大规模语料库上进行预训练得到词向量,从而提升了模型在下游任务的表现;但这种预训练过程往往可以看作是一种对语料进行的预处理,仅能获得词与词之间的浅层关系。同时,这种方式得到的词向量始终是固定不变的,无法根据不同的下游任务进行灵活改变,也不能处理遇到新词和一词多义情况,缺乏针对性。可以看出,词级表示方法包含的语义信息十分有限。
1.2 文档级表示
文档级语义表示超越了词级范畴,通过输入整个句子或文档序列,在语言模型上进行预训练,根据不同语境动态地提取文本序列的句法规则和语义特征。
假设一个语料库中的文本表示为(t1,t2,…,tN),用词级表示方法可以得到文本序列中每个ti 对应的向量
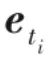
,而文档级表示方法就是将每个
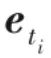
与输入的整个序列通过函数f 相关联求得
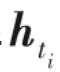
,即:
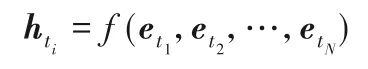
文档级表示方法不仅利用了词级表示生成的词向量,还将预训练技术运用于更复杂的语言模型,获取更高级的语义表示,如ELMo、GPT、BERT 等都采用了这种思想。采用文档级表示方法的预训练模型,在文本分类、问答系统、摘要生成等众多NLP 任务上取得了突破性效果,如今这种方法也成为了研究预训练技术的一种主流趋势。
从文档级表示内容的范围上看,还可以将其大致划分为局部文本信息和全局文本信息。
1.2.1 局部文本信息
一般是通过捕获局部上下文信息生成词向量表示,典型的预训练技术主要采用语言模型的方法。在提取语言特征时,大多基于以下技术:卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络、长短期记忆网络等。
CNN 能够结合文本序列位置信息,通过池化层获取最有用的文本且训练速度较快,但其获取信息能力的大小取决于卷积核窗口长度,因此捕获能力有限,只适用于局部文本[15],不能很好地解决长期依赖问题,而且池化操作不利于序列位置信息的传递。RNN 根据时间序列逐词处理文本信息,通过隐藏节点来传递前文短期记忆,其结构简单、符合语言习惯,天然适合NLP 任务,但该结构在训练长序列文本时很容易出现梯度消失或梯度爆炸现象,优化较为困难。除此之外,RNN在计算过程中,当前节点的计算必须依赖于前一个时间序列的隐藏节点,不便于并行计算,导致效率低下。LSTM 和GRU(Gated Recurrent Unit)[16]则通过引入门控机制缓解了梯度消失和长期依赖问题,但其本质上还是基于RNN 的序列结构,很多问题并不能得到彻底解决。
为捕获上下文信息,很多模型采用双向RNN[17]或双向LSTM 结构,最终合并正向和反向结果。如ELMo 就是使用两层双向LSTM 用于编码上下文以捕获句法和语义特征,其结构如图2 所示,左侧双层LSTM 表示前向编码器,按照从左至右的顺序输入上文预测下文;右侧双层LSTM 代表逆向编码器,由右至左输入下文预测上文,以此获取上下文特征。预训练阶段,ELMo利用语言模型获得词向量表示;在下游任务中,根据不同的上下文语境调整先前获得的词向量,以提高其准确性和适应能力。通过将预训练技术运用于语言模型,有效地应对了同一词语在不同上下文场景中的一词多义问题。
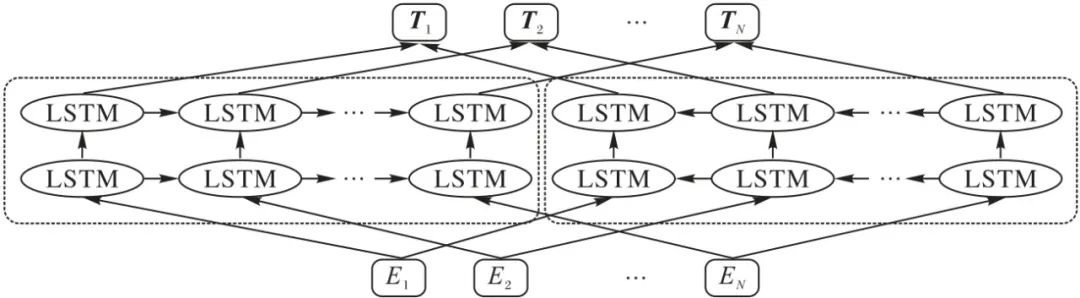
图2 ELMo模型结构
ELMo能够获得不同语义场景下的词向量表示,在问答系统、文本蕴涵和情感分析等6个NLP 任务上有出色的表现;同时这种先在大规模未标记语料库上进行无监督预训练,再对下游任务进行特征提取的两段式方法也为后续的相关研究打开了思路。
由于ELMo 采用LSTM 架构,仍然存在计算效率低下等问题。除此之外,这种双向模型的结果往往是通过联合叠加正向和反向两次单向过程得到的,无法同时获取上下文信息。因此,通过局部上下文获取的信息始终有限,容易产生局部误差。
1.2.2 全局文本信息
不同于顺序计算的思想,Attention 机制[17]为获取全局文本信息提供了一种新思路,通过计算目标词与源文本每个词之间的相似度作为权重系数,对其进行加权求和表示词向量,实现关注和提取上下文重点信息。此类方法主要以Transformer为典型代表。
Transformer 在Attention 的基础上统一了目标词与源文本,提出Self-Attention 结构,并将叠加的Self-Attention 结构与Multi-Head Attention 机制结合,能够同时获取上下文信息,解决了长期依赖问题,还具备了并行计算的关键能力,在一定程度上证明了增加模型参数规模可以提升模型效果。因此这种架构被之后的预训练模型广泛使用,以对NLP 任务进行更深层次的探究。虽然Transformer 解决了长期依赖问题,在能够获取更多语义信息的同时还实现了并行计算;但是,随着文本序列长度的增加,全连接Attention 机制所需要的计算成本也越来越高。
为降低Transformer 处理长文本序列时的计算复杂度,多项研究提出了自己的改进方法:Transformer-XL[18]在原模型的基础上,引入了相对位置编码以及分段RNN机制;Reformer[19]改进了Transformer 中的Multi-Head Attention 机制,提出基于局 部 敏 感 哈 希(Locality Sensitive Hashing,LSH)的Self-Attention,并引入了RevNet(Reversible Residual Network)架构[20];Longformer[21]提出一种由局部和全局两个部分构成的稀疏Self-Attention 结构。总之,Transformer 为预训练模型的底层架构注入了强大的动力,将文本特征提取提升到了一个新高度,同时也为之后的预训练模型的发展指明了一条新的道路,如GPT、BERT等都是其受益者。
GPT 是一个典型基于单向Transformer 的预训练模型,其结构如图3 所示。首先,它验证了以多层Transformer 作为核心架构进行特征提取的效果要明显优于基于RNN 的序列结构,并证明了其在无监督预训练任务上的性能;其次,该方法采用单向语言模型作为训练目标任务,通过上文信息来预测下文。与ELMo 的两段式不同,它提出了一种半监督学习方法,即先在大规模无标记语料库上进行无监督训练,在下游任务上,没有进行特征提取,而是以最后一层的词向量作为后续任务的输入并利用少量标注语料进行有监督训练微调。同时它还为不同下游任务提出了统一的模型框架,仅需根据特定任务对输入数据进行相应的转换,避免了针对不同任务而设计复杂的下游模型。
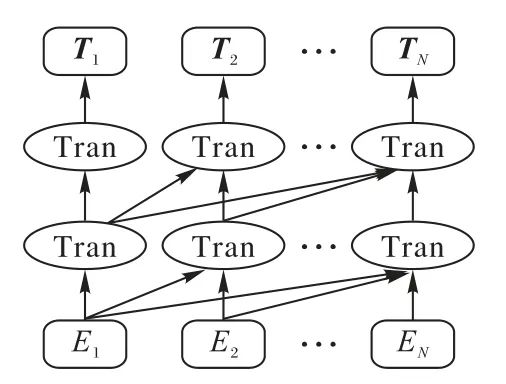
图3 GPT模型结构
GPT 在 GLUE(General Language Understanding Evaluation)[22]的多个NLP 任务中均取得了state-of-the-art 结果,并且在小数据集上也表现出色。但其采用的单向的语言模型未能发挥出Transformer 的最佳效果,从一定程度上也制约着其性能的进一步提升。
BERT被Google部署到搜索引擎上以改进搜索效果,其结构如图4 所示。它由多个双向Transformer 编码器层堆叠组成全连接神经网络结构,在嵌入时涵盖了词类、句法和位置等信息。相较于GPT 的单向语言模型,BERT 采用双向方法,能够从真正意义上同时捕获上下文语境信息。
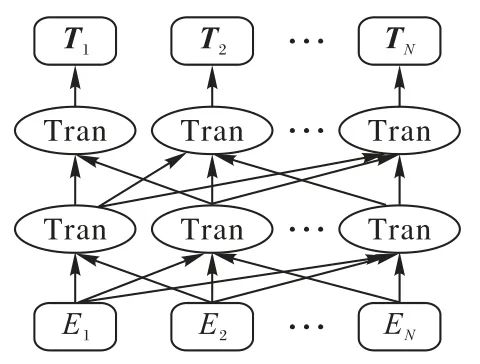
图4 BERT模型结构
BERT 采用与GPT 相同的“预训练+微调”两段式思路。预训练主要包含Masked Language Modeling(MLM)和Next Sentence Prediction(NSP)两个半监督任务。MLM 类似于完形填空,随机遮盖住输入的文本序列,然后利用其他序列的句法规则和语义信息预测这些词。由于在微调阶段不会对输入文本进行遮盖操作,因此会引起预训练和微调阶段的不一致性,为缓解这个问题,在选取的15%遮盖词中,对其中80%的词进行真正的遮盖,10%的词进行随机替换,最后10%的词保持不变。由于从词粒度上无法判断两个句子之间的关系,NSP任务从句子层面预测两个输入是否相邻。在该任务中,通过随机抽取文档中两个相邻句子构建正样本,而负样本则随机抽取不相邻的句子。文献[23]研究表明,BERT 通过预训练,有助于微调下游任务时找到更宽、更平坦的区域,且泛化误差较小。因此,在处理过拟合问题上表现更好。
预训练模型BERT一经推出,就刷新了11项NLP任务,取得state-of-the-art结果,表2给出了BERT[6]与其他模型在GLUE任务上的实验对比,共包括9 个自然语言理解(Natural Language Understanding,NLU)任务,结果表明,采用全局文本信息方法的性能明显优于局部文本信息的方法。可以说BERT 是集前期研究成果大成之作,“预训练+微调”的两段式方法也成为处理大多数NLP 任务的主流方式,从一定意义上看,BERT开启了NLP领域的一个新时代。
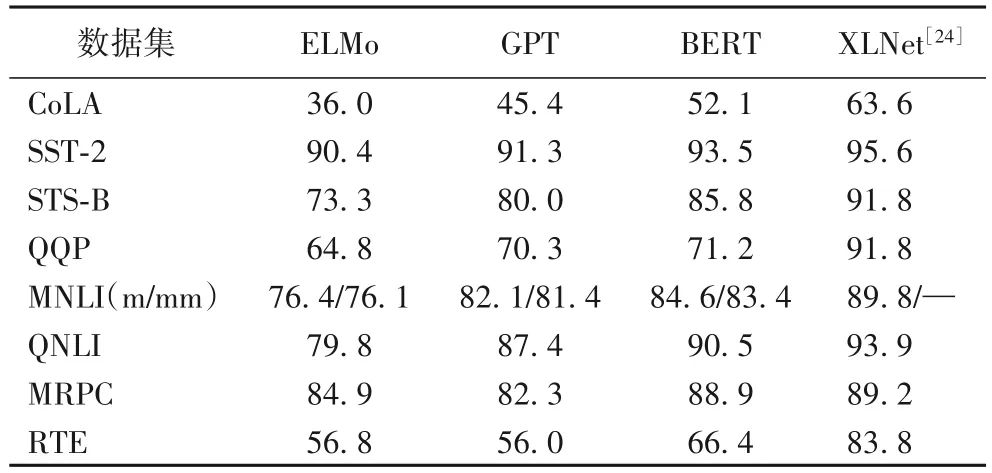
表2 不同模型在GLUE任务上的实验结果对比 单位:%
注:m/mm表示在MNLI数据集中,匹配和不匹配测试集上的准确率。
2 预训练模型研究现状
BERT 的问世引起了NLP 界的一股热潮,凭借其出色的性能和良好的泛化能力,它的各种变体也提升了很多任务的效果。除此之外,以XLNet 为典型代表的模型也提出了与BERT 不同的思路。本章主要从预训练阶段目标任务和下游应用出发,对当前典型预训练模型进行梳理和分析,旨在理清预训练模型的发展现状。
2.1 预训练阶段目标任务
从预训练阶段目标任务的数量出发,可以将预训练模型大致分为两类:基于单任务和基于多任务。
2.1.1 基于单任务
单任务指在预训练阶段只采用一个目标任务,一般基于以下几种方法:基于自回归语言模型(Language Model,LM)、基于降噪自动编码器(Denoising AutoEncoder,DAE)和基于多流机制。
1)基于LM。
自回归语言模型是处理NLP任务时经常使用的一种经典概率模型,其本质上是概率回归。给定一个文本序列X1:T=[X1,X2,…,XT],其联合概率分布P(X1:T)可分解为:
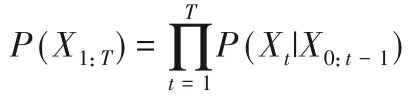
式中X0表示初始序列。
传统的自回归语言模型往往是自左向右来考虑被预测词之间的相关性,它符合人类语言习惯,因此天然适合处理自然语言生成(Natural Language Generation,NLG)任务。在预训练过程中,ELMo 通过两个反向的双层LSTM 分别从正向和逆向来预测上下文信息,巧妙地弥补自回归语言模型单向处理文本序列的缺陷。
与ELMo 类似,ULMFiT(Universal Language Model Fine-Tuning)[25]也选择语言模型作为目标任务,采用了更高效的三层AWD-LSTM(ASGD(Average Stochastic Gradient Descent)Weight-Dropped LSTM)[26]架构,通过引入正则化手段和针对目标语言模型定制微调策略,结合差异精调、倾斜三角率和逐层解冻等方法进一步提升了语言模型的性能,降低了多个文本分类任务18%~24%的错误率。
SiATL(Single-step Auxiliary loss Transfer Learning)[27]针对ELMo 和ULMFiT 预训练计算成本过高的问题,在构建语言模型时依然采用更简单的两层LSTM 结构,提出辅助语言模型,将训练负担转移到下游任务,使得对特定任务微调时也能训练更新预训练模型参数,在优化策略上,采用序贯解冻的方法,随着训练批次的增加逐渐解冻不同层的参数,直至模型最终收敛。相较于ULMFiT,SiATL 在文本分类任务上表现出更好的性能。
与前几种方法不同,GPT系列[7,28-29]均采用单向的Transformer 架构建立语言模型,在处理文本的长距离依赖问题和并行计算上相较于LSTM 有着更好地表现。同时,该系列模型主要在模型和训练数据规模上进行了改进,其细节对比如表3所示。
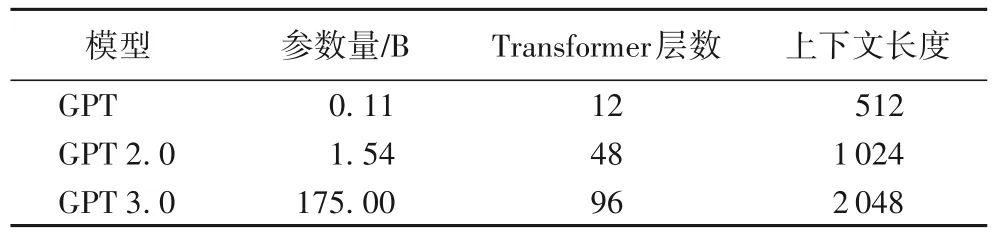
表3 GPT系列模型细节对比
但是,从联合概率分布的分解公式中可以看出,自回归语言模型只能按照序列顺序对文本进行自左向右或自右向左的单向分解,尽管ELMo 提出了双向结构,但其本质上还是两个单向LSTM 的拼接,仍无法同时获取上下文表征。而上下文信息对NLU 任务非常重要,自回归语言模型不能很好满足这一需求。
2)基于DAE。
不同于概率密度估计,DAE采用了一种“填空”的思想,先破坏输入文本序列再训练模型进行恢复。
对于同一个文本序列,采用DAE 方法时,其联合概率分布P(X1:T)可近似表示为:
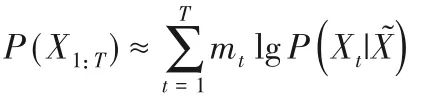
式中:如果当前序列被预测,则mt=1,否则mt=0;
![]()
表示原始文本被替换后的输入。
目前基于DAE 方法主要以BERT 提出的MLM 为代表,即在文本序列中加入噪声MASK 进行遮盖,再训练模型去预测这些被遮盖的序列,配合Transformer 架构,MLM 在NLU 任务中取得了显著的效果,但这种“填空”结构不能像自回归语言模型那样适合处理NLG 任务。针对这一问题,MASS(Masked Sequence to Sequence pre-training)[30]在预训练目标上引入“编码器-解码器”结构,对BERT 和传统语言模型框架进行统一,编码器采用改进MLM 机制来随机遮盖连续的单词片段,解码器则对这些片段进行预测,最终通过对编码器和解码器的联合训练来提高对语言的建模能力,在英语-法语翻译任务上的BLEU(BiLingual Evaluation Understudy)分数达到了37.5。值得注意的是,MASS还具有一个统一的预训练框架,在MLM 过程中,当遮盖词的数量为1 或为整个输入序列时,MASS 分别与BERT和GPT等价。
为更好地统一NLU 和NLG 任务,T5(Text-to-Text Transfer Transformer)[31]在预训练目标任务中也采用“编码器-解码器”结构,但与MASS 不同的是,T5 对模型架构、语料库、掩码机制、训练策略等多个方面进行了全面详细的对比分析,证明了MLM机制的优势,在英语-法语翻译任务中的BLEU分数达到了43.4%,相较于MASS提升了5.9%。
同样为提高预训练模型在NLG 任务上的表现,BART(Bidirectional and Auto-Regressive Transformers)[32]采 用DAE的方法设计了“序列-序列”预训练模型。为了在结合上下文语境信息的同时仍能适应序列生成任务,该模型提出了基于Transformer 的双向编码器和自回归解码器融合架构,在预训练过程中首先使用任意噪声函数破坏文本,然后经过双向编码器处理后送入自回归解码器预测原始文本。最终BART 不仅在多个文本生成类任务上取得了最优的结果,而且在文本理解类任务上也与XLNet等模型相当。
对于BERT 中NSP 任务的效果,很多研究提出了质疑[23,33-35],RoBERTa[35]放弃了NSP,仅使用动态优化的MLM 作为预训练任务,与MASS和T5所采用的静态遮盖不同,在每次迭代训练过程中,它的遮盖对象是动态变化的。RoBERTa 还配合采用更大的batch size、扩大训练规模、延长训练时间等方法来提升模型效果,在GLUE任务上超越了BERT和XLNet。
基于DAE 方法虽然弥补了自回归语言模型不能同时获取上下文信息的缺陷,但也带来一些问题,比如不适应NLG任务,而且MLM 方法在预训练时人为添加了MASK,而微调时它又不存在于实际数据中,造成两个阶段的不一致。除此之外,随机选取部分序列进行MASK 还可能会忽略被MASK序列之间存在的语义关联。
3)基于多流机制。
通过对前期工作中自回归语言模型和降噪自动编码两种方法的研究,XLNet 在融合了两者优点的同时避开其缺陷。并且为了更好地处理长文本问题,XLNet 采用了Transformer-XL架构。针对BERT 中的MLM 机制引起的不一致问题,在单向自回归语言模型上同时获取上下文信息,XLNet 针对预训练阶段设计了排列语言模型(Permuted Language Model,PLM)。从广义上看,PLM 也是一种自回归语言模型,单向地进行语言建模,但通过双流自注意力机制,它融入了双向语言模型的优势。其思想是首先对被预测词的位置进行固定;然后随机排列组合剩下的词语,使得被预测词的下文也能被排列到其上文位置;最终通过下文信息来预测上文。
在PLM 实现上,XLNet 通过双流自注意力机制,类似于MLM 机制中的MASK 过程,引入Query 流对输入文本中预测单词的进行遮盖,不同于MLM 机制中显式地对输入序列中的部分单词进行随机MASK 操作,XLNet 在文本特征提取器内部,即Transformer-XL 中进行隐式的MASK 操作,使得被MASK 的单词在预测时不发挥作用,从而有效缓解了MLM 机制中预训练与微调阶段的不一致问题。XLNet 在长文本阅读理解任务中取得了显著效果,如表2 所示,在GLUE 任务上的性能超越了BERT 等其他模型。
受到XLNet 双流自注意力机制的启发,百度提出了基于多流预训练技术的语言生成模型ERNIE-GEN[36]。其采用基于Transformer 的“编码器-解码器”框架,考虑到传统的“序列-序列”模型往往采用逐字符的学习范式,一方面在进行预测时容易过度依赖于上一个词;另一方面逐字符生成也与人类基于实体和短语的写作思考方法不一致。因此,ERNIEGEN 率先引入了Span-by-Span 生成流以改进语义单元生成效果,在训练时不仅仅只预测一个字符,而是预测一个完整的语义片段。除此之外,它还设计了Contextual流来建模语言单元的上文信息,并通过Mulit-flow Attention 机制来进行多流的联合学习。针对“序列-序列”生成模型面临的曝光偏差问题,ERNIE-GEN 提出了填充生成和噪声感知机制,以减小训练和解码生成之间的差异。最终用更少的参数和数据,在多个生成任务上取得了state-of-the-art效果。
与ERNIE-GEN 相似,针对传统语言模型无法捕捉长距离依赖问题,微软提出了语言生成模型ProphetNet[37]。该方法采用基于n-gram 的多流机制,能够同时对不同语义粒度的文本信息进行建模,不同于传统“序列-序列”结构每次只能预测下一个字符,ProphetNet 能够同时预测未来更远的n 个字符,以防止模型在预测时过于依赖距离较近的文本信息,避免局部相关的过拟合现象。表4 给出了两者在SQuAD(Stanford Question Answering Dataset)数据集[38]上进行问题生成任务的实验对比,可以看出两种方法在不同任务上的表现相当。

表4 ERNIE-GEN与ProphetNet的实验结果对比 单位:%
以XLNet为代表的PLM方法融合文本生成和获取上下文信息的优势,既弥补了MLM 的缺陷,又保持了语言模型的优势,兼顾了NLG 和NLU 任务,适用的范围更广,启发了后续的研究。
2.1.2 基于多任务
多任务指在预训练阶段采用多个目标任务联合训练,与单任务相比,多任务往往带来更加复杂的模型结构,但能进一步提升模型的性能。其中一个典型代表BERT 的预训练过程就包含了MLM 和NSP 两个任务,除此之外,针对模型压缩、高效计算、多任务学习等问题,很多研究在此基础上进行了一系列优化,表5给出了不同模型在GLUE任务上的实验对比。
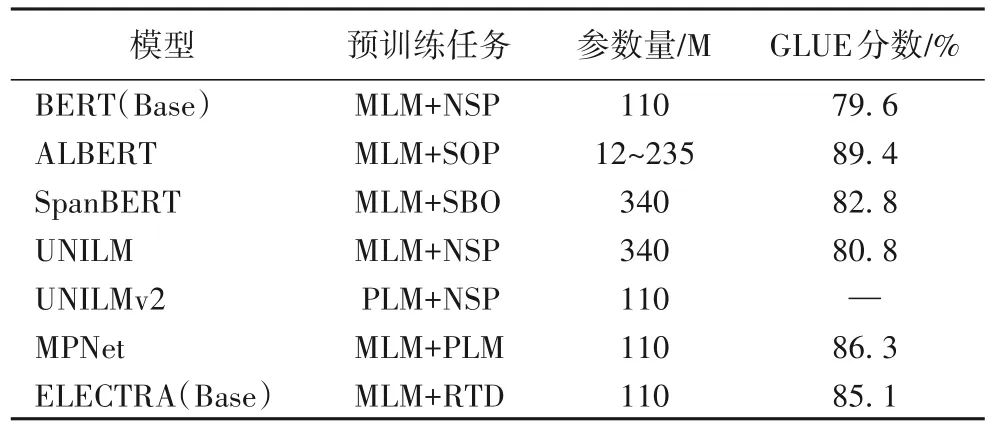
表5 基于多目标任务的预训练模型实验结果对比
ALBERT(A Lite BERT)[33]为简化BERT参数规模:一方面考虑到词向量的维度可以不必与隐藏层的维度保持一致,因此对词嵌入参数进行因式分解,通过降低词嵌入维度来减少参数量;与此同时,由于BERT 中各层参数独立且不共享,ALBERT 通过共享各全连接层和注意力层参数,明显减少了隐藏层参数量。另一方面,ALBERT 提出新的目标任务,即句子顺序预测(Sentence Order Prediction,SOP)来替代BERT 中的NSP 任务,相比于NSP,SOP 任务主要针对句子间的连贯性问题并且更为复杂。最终ALBERT 在保持甚至提高模型性能的条件下有效压缩了模型。
原始的BERT 采取随机遮盖最小单元的方法,但这种做法往往会割裂一个完整词汇的语义信息。SpanBERT[34]的改进主要体现在MLM 机制的遮盖方式上,对随机相邻的连续词而不是单个词进行MASK,在选择遮盖长度时,首先从几何分布中进行采样得到分词的长度,然后从中进行随机均匀选择。除此之外,SpanBERT 将NSP 替换为Span-Boundary Objective(SBO)任务,训练模型仅通过边界词来预测遮盖部分的内容。最终该模型在问答、共指消解等NLP 任务中均取得了显著的效果。
微软提出的UNILM(Unified pre-trained Language Model)[39]采用BERT 中MLM 机制的思想,在预训练时设计了单向和双向语言模型以及“序列-序列”语言模型三个目标函数,并分别进行相应的MASK 操作,然后与NSP 任务联合建模同时共享一个Transformer 框架。UNILM 还在不同目标函数上共享网络参数,避免了结果过拟合于单一的语言模型。在“序列-序列”语言模型的推动下,UNILM 不仅能灵活处理NLG 任务还能适应NLU 任务。其改进模型UNILMv2[40]引入XLNet 中的PLM,提出了伪掩蔽语言模型(Pseudo-Masked Language Model,PMLM),将自编码和部分自回归方法统一于预训练目标任务的语言模型,其中通过自编码方法进行传统的MASK操作,以学习被遮盖词与上下文之间的关系;同时为学习被遮盖词之间的关系,采用PLM 中基于部分自回归伪掩码的思想。这种结合类似于多流自注意力机制进行联合建模的方式,在PLM 中实现了连续词的预测,相较于BERT、XLNet 和RoBERTa在多个任务中取得了更好的效果。
同样是微软提出的MPNet[41]发现PLM虽然近似实现了双向LM 功能,但从单个因式分解过程的细节上看,被预测的序列依然只能关注到它前面的序列,无法看到完整的序列和位置信息。为弥补这一缺陷,MPNet 在预训练时结合MLM 与PLM的优势,采用联合建模的方式,通过在被预测序列中加入位置补偿信息,进一步减少了预训练和微调过程之间的差异。
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)[42]针对MLM机制提出了Replaced Token Detection(RTD)任务,将生成式转化为了判别式任务,采用替换而不是掩盖的方法破坏输入。在训练时引入类似对抗学习的思想,先通过基于Transformer 的生成器对遮盖的序列进行预测,再将预测结果输入到判别器中,从而训练模型去判断每一个词是否被生成器替换过。ELECTRA 进一步提升了预训练模型的学习效率,在提高了模型性能的同时大幅降低了计算成本。
2.2 预训练模型应用
预训练模型在NLP 任务上的应用采用知识迁移的思想,如图5 所示,将预训练模型在语料库中学习到的知识,有效地运用于下游任务。

图5 迁移学习
为了提升运用的效果,避免过拟合或灾难性遗忘等问题,针对不同的任务还必须选择合适的语料库、预训练模型架构以及微调策略。如Google 提出的T5 根据迁移学习的思想,将所有语言问题统一于一个Text-to-Text 框架,并从预训练目标任务,架构设计、语料库选择和迁移方法等多个因素出发进行了系统的研究,同时还提出Colossal Clean Crawled Corpus(C4)作为一种更高质量的语料库以此来提高下游任务性能。
对于训练数据的筛选,Ruder 等[43]引入贝叶斯优化方法,从多个数据源进行选择,有效提高了训练质量,还分析了该方法在不同模型、领域和任务上的鲁棒性;GPT 2.0/3.0[28-29]在更宽领域和更大规模的高质量语料库上进行预训练,同时加入了更多的模型参数,甚至不需要进行微调就可以直接应用到下游任务。
预训练模型在具体下游任务的应用主要靠特征提取或微调来实现。特征提取时预训练模型的参数被固定,因此可以减少下游任务的计算,但需要针对具体任务设计特定的模型结构;微调方法将通用的预训练模型应用于不同的下游任务,通过具体的任务进一步更新预训练模型参数,更好地发挥预训练模型的普适作用,因此较为常用。Peters 等[44]通过对ELMo 和BERT 的研究发现,预训练任务与下游目标任务的相似性在对特征提取或者微调方式的选择上有较大影响。实验表明,当下游任务为序列标记或句子对任务时,ELMo 更适合于采用特征提取的方法,而BERT则更适合微调。
按照预训练模型在下游任务的使用策略,将预训练模型大致分为四类:基于单任务/多任务微调、辅助微调下游任务、进一步预训练和其他策略,表6给出了它们的实验对比。
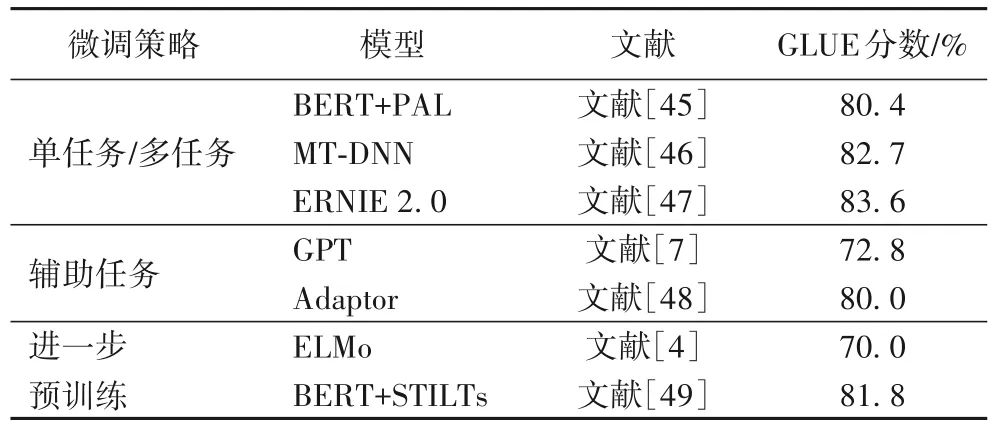
表6 不同微调策略下的预训练模型实验结果对比
1)基于单任务/多任务微调。
单任务微调是大多数模型所采用的微调方式,可以理解为让预训练模型在有监督数据集上训练单个特定任务;而多任务微调往往采用多任务学习的方法共享多个相关任务之间有价值的信息,提高模型在不同任务上的泛化能力。
微软提出的MT-DNN[46]在微调时引入了多任务学习的方法,以BERT 作为底层共享的文本特征提取模块,从每个批次中随机选择一个任务进行训练,一方面弥补了部分下游任务标记数据不足的缺陷;另一方面可以减轻模型在特定任务上的过拟合现象。MT-DNN实现了超越了BERT的性能,进一步证明了多任务学习的微调效果和泛化能力。不同于MT-DNN在微调过程中引入多任务学习的方法,ERNIE 2.0[47]为了进一步提取文本语料中的语义、语法和词汇信息,采用增量学习的思想,在保留已学习知识记忆的基础上,继续从新数据中学习有用信息。在预训练时定义了词汇、语法、语义等三个层级上的任务,并采用多任务学习机制全面提取语料库中的先验知识。在中文和英文场景任务下的效果都明显优于BERT。Stickland 等[45]受到CV多任务学习和“residual adapter modules[50]”的启发,在BERT中设计添加了一种基于多头注意力机制的投影注意层(Projected Attention Layers,PAL),实现高度的参数共享,在文本蕴含任务上的表现超越了BERT 和MT-DNN。
2)辅助微调下游任务。
通常是在微调时利用预训练阶段的目标任务或设计新的模块来防止灾难性遗忘,提高模型性能。如Yang等[51]提出微调时结合预训练模型的多层而不是顶层特征来丰富信息表示的方法。
SiATL 在微调时将预训练阶段的语言模型作为辅助目标函数,并与特定任务的优化函数相结合,从而设计了一个简单而有效的目标函数,可近似表示为:
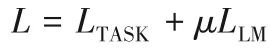
式中,μ 为指数衰减系数,其用途在于随着后期训练次数的迭代增加,通过减小辅助语言模型LLM 的影响力来提升任务目标函数LTASK对总目标函数L的主导作用。
这种方法既能利用语言模型捕获的语法规则,又能提升模型对特定任务的适应能力,并且有效缓解了灾难性遗忘问题。最终SiATL 在不同的文本分类任务上取得了优于ULMFiT 的结果。GPT 也在对下游任务进行微调时也采用了与SiATL 相同的思路,不仅能够改善模型对已学到知识产生遗忘的现象,还能提升模型收敛速度和精度。
Houlsby 等[48]在预训练的各层之间添加Adaptor 模块,当对不同的任务进行微调时,仅需调整Adaptor模块中的少量参数,而模型的大部分参数保持不变,实现了高度参数共享,有效提高了预训练模型针对不同任务的微调效率。
3)进一步预训练。
一般是在预训练和微调两阶段之间在不同语料库上进行额外的预训练以提升预训练模型的稳健性和泛化能力,如Gururangan 等[52]提出了领域适应性和任务适应性训练。ERNIE(Enhanced Representation through knowledge Integration)[53]在对预训练过程中的遮盖词进行预测时采用了知识增强的方法,并引入实体级和短语级信息,以学习更丰富的语义知识。与此同时,通过在由百度贴吧对话数据构成的语料库上进一步预训练,能够学习到对话中的隐式关系,增强模型学习不同语义表示的能力,最终在自然语言推理、语义相似度、情感分析等多个中文NLP任务中都取得了显著的效果。ELMo将预训练模型在特定任务上进一步训练,再应用于最终任务,有效提升了其性能。ULMFiT 也采用了逐层解冻、差异精调和倾斜三角学习率的方法优化在特定任务上进行额外的预训 练。Phang 等[49]设计STILTs(Supplementary Training on Intermediate Labeled-data Tasks),发现额外的有监督训练能够有效提升下游任务的稳健性。受到STILTs的启发,He等[54]提出了QUASE(Question-Answer driven Sentence Encoding)框架,针对目标任务单句或多句的输入类型,利用问答(Question Answering,QA)数据集对模型做进一步预训练,以提高最终下游任务的效果。
4)其他策略。
主要表现为非微调的方式,如特征提取。在特征提取中,特征提取的难度随着训练任务与下游目标任务相似性减小而增大。但GPT 2.0/3.0 在上游任务中通过利用大规模高质量语料库进行无监督训练能够缓解这一问题。
GPT 2.0 的基本结构与GPT 相似,其改进一方面主要体现在数据质量的提升,在高质量、宽泛的海量数据上进行无监督训练;另一方面不再为特定任务设计微调流程,并且无监督地进行下游任务,最终刷新了7 大数据集的state-of-the-art 结果。GPT 3.0 依旧延续旧版本中单向语言模型结构,进一步扩大模型和数据规模,采取无监督的学习方式且无须微调。GPT 3.0 在Zero-Shot、One-Shot 和Few-Shot 三种样本条件下探究了模型规模对其表现的影响,最终结果表现出强大的泛化能力。在一些任务中的效果达到甚至超越了最新的采用微调方式的模型。
3 面临的主要挑战与展望
3.1 面临的主要挑战
近年来,以BERT、XLNet 为典型代表的一系列预训练模型在NLP 任务上取得了丰硕的成果,在证实了预训练技术重要意义的同时也面临着困难与挑战。
1)计算成本高。
随着Transformer 的广泛应用,通过深度预训练可以得到越来越高层次的文本信息,但这也使得预训练模型的规模呈现普遍增长的趋势,最具有代表性的BERT 的base 版本包含约1.08亿个参数,xlarge版本达到了12.7亿个参数,这种现象到GPT 3.0 达到了高峰,采用1 750 亿个参数和45 TB 的训练数据。模型扩大对计算设备提出了更高的要求,如何降低高昂的计算成本是今后面对的主要问题之一。
2)鲁棒性差。
深层次的神经网路由于其线性特点,容易受到对抗性输入的攻击[55]。尽管预训练模型在不同NLP 任务上表现出色,但它们大多采用深层神经网络的结构,因此也存在鲁棒性差的问题。对抗性攻击作为检验模型鲁棒性的手段,最早在CV领域被广泛应用,但由于文本不同于图像,一个字的变化就可能改变整句话所表达的含义。针对文本对抗攻击的研究起步较慢,Jin 等[56]使用对抗文本攻击了许多现有模型后发现,它们的性能都发生了急剧下降。因此,提高预训练模型的鲁棒性也是今后一个亟待解决的问题。
3)语义理解不足。
预训练语言模型究竟有没有真正学到语言的真正意义,还是仅仅学到了一种“形式”?Bender等[57]敲响了警钟。尽管很多模型在各类数据集上都有出色的表现,有的已经逼近甚至超过人类水平,但从文本对抗攻击可以看出,这种表现是脆弱的。仅依靠语料的学习忽略了人们使用语言时的交际意图[57],虽然能提取到一些有用的信息,但却是不完整的,并不符合人类使用语言的真正目的。
3.2 展望
在未来的研究中,预训练模型势必将会给NLP 领域的发展带来更多的惊喜,通过对预训练模型的归纳和总结,对其未来发展指出了以下几个可能的趋势。
1)精简和改进模型。
为降低预训练计算成本,以BERT 为对象展开了很多研究,融合了参数共享、知识蒸馏等多种方法,如ALBERT、TinyBERT[58]等,能在保持性能的前提下,通过共享参数和知识蒸馏等方法,大幅降低参数规模,提升训练效率,那么在未来具有一定计算能力的边缘设备能否也具有预训练能力?除此之外,多模态技术为设计强大的预训练模型提供了一个思路,除了文本之外,可以结合视频、图片、语音等多个领域的信息复现人类使用语言的情景,提高模型的语义理解能力,如ERNIE-ViL[59]等。同时,在继Transformer、BERT 后,未来能否提出新的具有革新意义的模型架构也非常值得关注。
2)提高模型稳健性。
对抗性训练是提高预训练模型鲁棒性的关键手段,如采用化攻为守的方法,利用对抗样本训练模型。Goodfellow[60]和Madry等[61]针对文本对抗训练方法展开研究,Zhu等[62]也在前期研究的基础上,提出了对抗训练算法FreeLB(Free Large-Batch)。鲁棒性是当前预训练模型面临的重要问题之一,想必在未来还会出现更多的方法来增强模型的稳健性。
3)优化评价体系。
随着NLP 领域技术的快速发展,很多评测体系已经不能满足当前模型的需求而进行了相应的改进。如用于机器阅读理解的问答数据集SQUAD 2.0[63]和多任务的NLU 基准与分析平台SuperGLUE[64]等都增加了更为复杂的任务,旨在能够推动更强大的模型诞生。Ribeiro 等[65]还提出了全新的评测方式CHECKLIST,不再对已有数据进行测试集和训练集的简单地划分,而是能够从各个任务层面,对模型进行全面的评测。评价标准指引着领域的发展方向,因此,未来评价体系的建设也显得尤为重要。
4 结语
本文主要对NLP任务中预训练模型的发展和研究现状进行了简要概述。从文本特征提取技术上看,预训练模型的发展主要以上下文信息的捕获能力为核心,经历了由简单到复杂、由局部到全局、由单向到双向的发展历程。目前,主流的文本特征提取技术以RNN、CNN 和Transformer 为代表,其中Transformer在众多任务中显现出优势,具有较大的发展潜力。从预训练模型的阶段任务和应用手段上看,其目标任务主要以自回归语言模型、降噪自动编码器和多流机制为典型代表,通过对不同方法的改进和融合来达到取长补短的目的。在应用手段上,主要面临着灾难性遗忘和过拟合等问题,在引入多任务学习、辅助微调函数和进一步预训练等方法后得到了显著改善。总而言之,目前预训练技术已经在自然语言处理问题上取得了不可忽视的成就,具有广阔的应用领域和前景。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。
“人工智能技术与咨询”发布















 1193
1193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









