







 本文综述了轨迹规划在机器人和自动驾驶领域的应用,介绍了传统算法如图搜索、采样、插值及数值优化,并探讨了基于机器学习的最新发展。
本文综述了轨迹规划在机器人和自动驾驶领域的应用,介绍了传统算法如图搜索、采样、插值及数值优化,并探讨了基于机器学习的最新发展。
0. 简介
对于自动驾驶以及机器人而言,除了SLAM以外,另一个比较重要的部分就是轨迹规划了。而最近作者看到了几篇比较好的文章,分别为《A Review of Motion Planning Techniques for Automated Vehicle》、《A review of motion planning algorithms for intelligent robots》、《A review of motion planning for highway autonomous driving》这里就结合各个文章阐述的要点给各位对轨迹规划进行科普,以便了解未来几年需要解决的差距和挑战。
1. 机器人领域传统算法
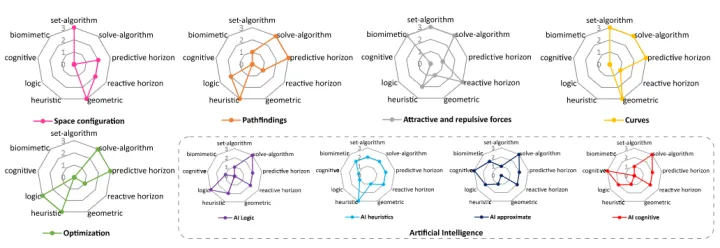
机器人规划算法根据其原理和发明的年代可以分为两类:传统算法和基于ML的算法。传统算法由四组组成,包括图搜索算法(如A*)、基于采样的算法如快速探索随机树(RRT)、插值曲线算法(如线和圆)、基于反应的算法(如DWA)。基于ML的规划算法包括经典的ML算法,如支持向量机(SVM),最优值RL,如深度Q-学习网络(DQN)和策略梯度RL(如演员批评算法)。下图总结了规划算法的类别。
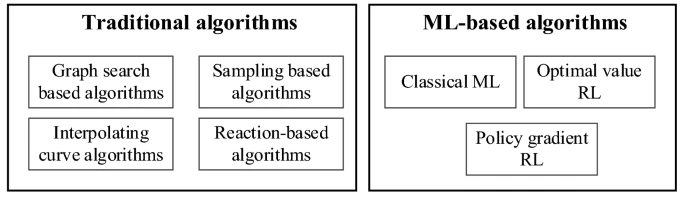
2. 机器人领域机器&强化学习算法
另一部分就是基于ML的算法的发展,例如经典的ML,如SVM,在早期阶段被用来实现简单的运动规划,但其性能很差,因为SVM的一步预测是短视的。它需要精心准备的矢量作为输入,而这些矢量不能完全代表基于图像的数据集的特征。在卷积神经网络(CNN)发明之后,从图像中提取高级特征的工作有了很大的改进(Lecun等人,1998)。CNN被广泛用于许多与图像相关的任务,包括运动规划,但它不能处理复杂的时间序列运动规划问题。这些更适合马尔科夫链(Chan等人,2012)和长短期记忆(LSTM)(Inoue等人,2019)。然后,神经网络与LSTM或基于马尔科夫链的算法(例如,Q学习(Smart & Kaelbling,2002))相结合,实现时间序列运动规划。然而,其效率是有限的(例如,在网络收敛方面表现不佳)。当谷歌DeepMind引入自然DQN(Mnih等人,2013年,2015年)时,取得了突破性进展,其中回复缓冲区是重复使用旧数据以提高效率。然而,由于噪声影响了对状态动作值(Q值)的估计,在鲁棒性方面的表现是有限的。因此发明了双DQN(Hasselt等人,2016;Sui等人,2018)和决斗DQN(Wang等人,2015)来应对噪声造成的问题。双重DQN利用另一个网络来评估DQN中Q值的估计,以减少噪声,而在决斗DQN中利用优势值(A值)来获得更好的Q值,噪声大多被减少。Q学习、DQN、双DQN和决斗DQN都是基于最优值(Q值和A值)来选择最佳的时间顺序行动。
最优值算法后来被政策梯度法(Sutton等人,1999)所取代,其中梯度法(Zhang,2019)被直接利用来升级政策,用于生成最优行动。政策梯度法在网络收敛方面比较稳定,但在网络收敛速度方面缺乏效率。Actor-critic算法((Cormen等人,2009;Konda & Tsitsiklis,2001))通过actor-critic架构提高了收敛速度。然而,收敛速度的提高是以牺牲收敛的稳定性为代价的,因此,演员批判算法的网络在早期阶段的训练中很难收敛。于是发明了异步优势演员批评(A3C)(Gilhyun,2018;Mnih等人,2016)、优势演员批评(A2C)足彩代理1(Babaeizadeh等人,2016)、信任区域策略优化(TRPO)(Schulman等人,2017a)和近似策略优化(PPO)(Schulman等人,2017b)算法来应对这一缺陷。A3C和A2C利用多线程技术(Mnih等人,2016)来加快收敛速度,而TRPO和PPO通过在TRPO中引入信任区域约束,以及在PPO中引入 "代用 "和自适应惩罚来改进行为批评算法的策略,以提高收敛速度和稳定性。然而,数据在训练后会被丢弃,因此必须收集新的数据来训练网络,直到网络收敛。
包括确定性策略梯度(DPG)(Silver等人,2014)和深度DPG((Lillicrap等人,2019;Munos等人,2016))在内的非策略梯度算法被发明出来,通过重放缓冲区重用数据。DDPG融合了行为批判性架构和确定性策略,以提高收敛速度。综上所述,经典ML、最优值RL和策略梯度RL是机器人运动规划中典型的ML算法,这些基于ML的运动规划算法的发展如图5所示。
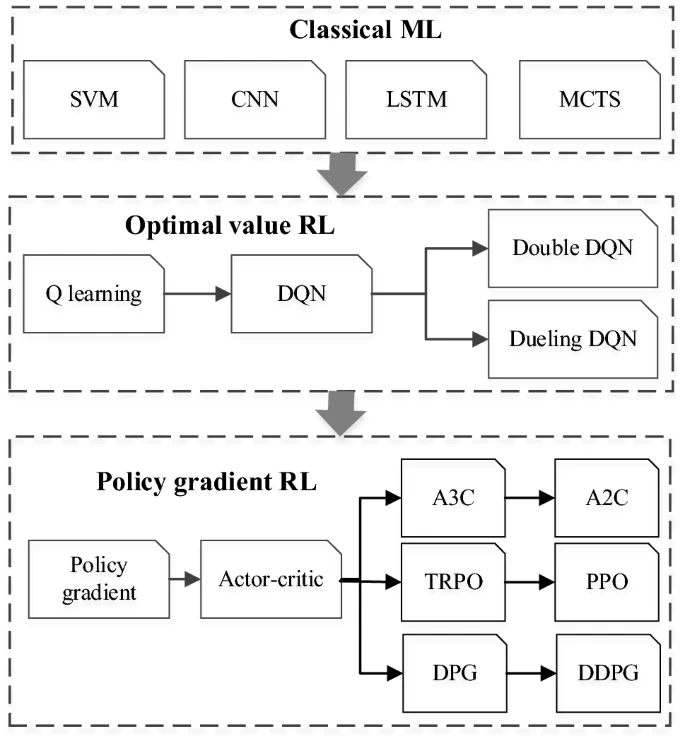
3. 自动驾驶领域传统算法
智能交通系统的应用显著地帮助驾驶员减少一些与驾驶相关的繁琐任务。具体而言,归功于巡航控制(CC)、自适应巡航控制(ACC)和最近的协作ACC(CACC)的发展,高速公路驾驶已经变得更为安全,可以使用其中预先定义好的与前车的间距来控制纵向执行器、油门和制动踏板。来提高车辆整体的安全性、舒适度、交通时间和能量消耗。这类系统被称为高级驾驶辅助系统(ADAS),下图为自动驾驶车辆的通用框架,其中对于自动驾驶而言,感知、决策和控制最为重要。而我们主要要讲的规划就是在决策层当中
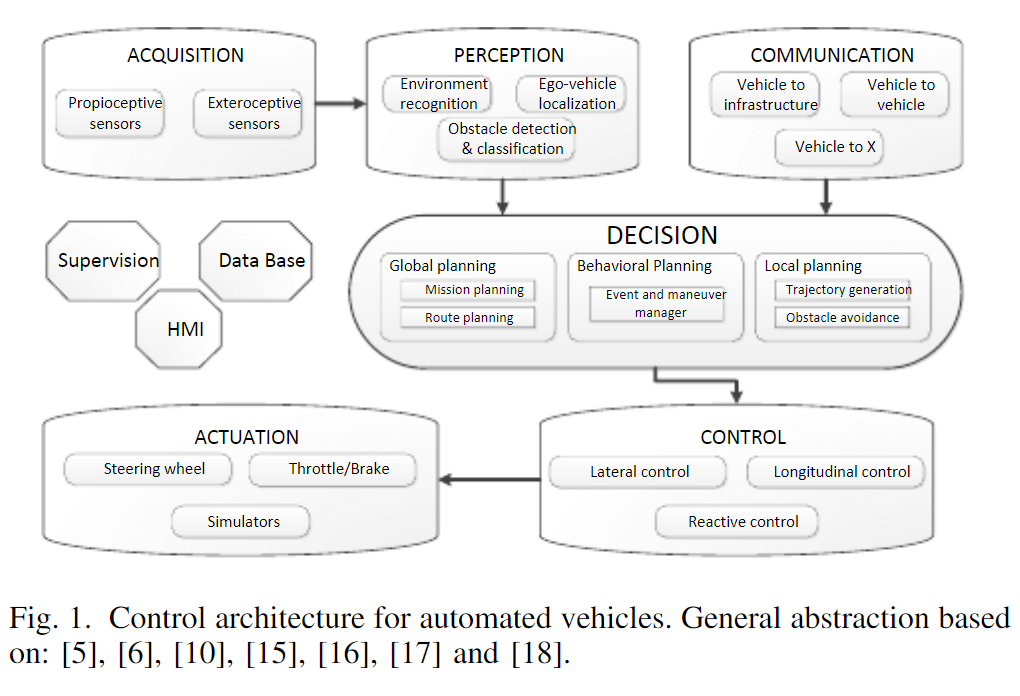
与机器人类似,这部分工作也同样适用于机器人导航的关键方面,因为它提供了全局和局部的轨迹规划以描述机器人的行为。它考虑了机器人从起始位置到终止位置的动力学和运动学模型。车辆和机器人之间执行运动规划的主要区别在于,前者解决了必须遵守交通规则的道路网络,而后者必须处理没有太多规则需要遵守的开放环境,它仅需要到达最终的目的地。
对于自动驾驶而言,其只需要以下几个功能,前两个部分不属于运动规划,因此不在本文的讨论范围。 下面主要讨论的是后三点
- 路线规划(route planning): 从起点到终点的长距离规划。
- 预测 (pediction): 通过储存的当前和历史动态信息来预测周围物体的动向。比如:道路信息,车道线的变化,路段交通规则,以及周围车辆的行为。
- 决策 (decision making):
- 生成 (generation):
- 形变 (deformation):
在过去几十年中,移动机器人中的路径规划已经成为一个研究课题。大多数作者将该问题划分为全局规划和局部规划。
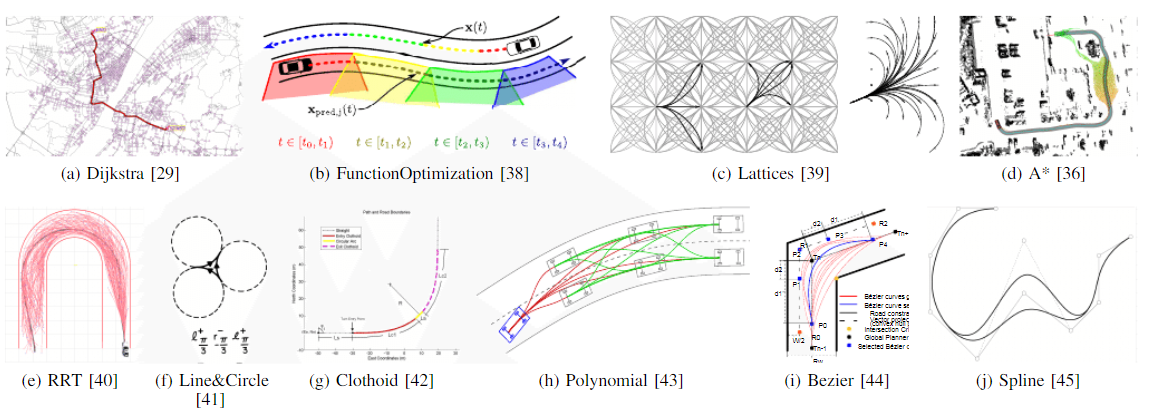
大量的导航技术来自移动机器人,只是自动驾驶会根据规则加以修改。这些规划技术根据它们在自动驾驶中的实现被分类为四组:图搜索、采样、插值和数值优化(见表格I)。下面描述了在自动驾驶运动规划中实现的最相关的路径规划算法。下面我们来简述每个模型
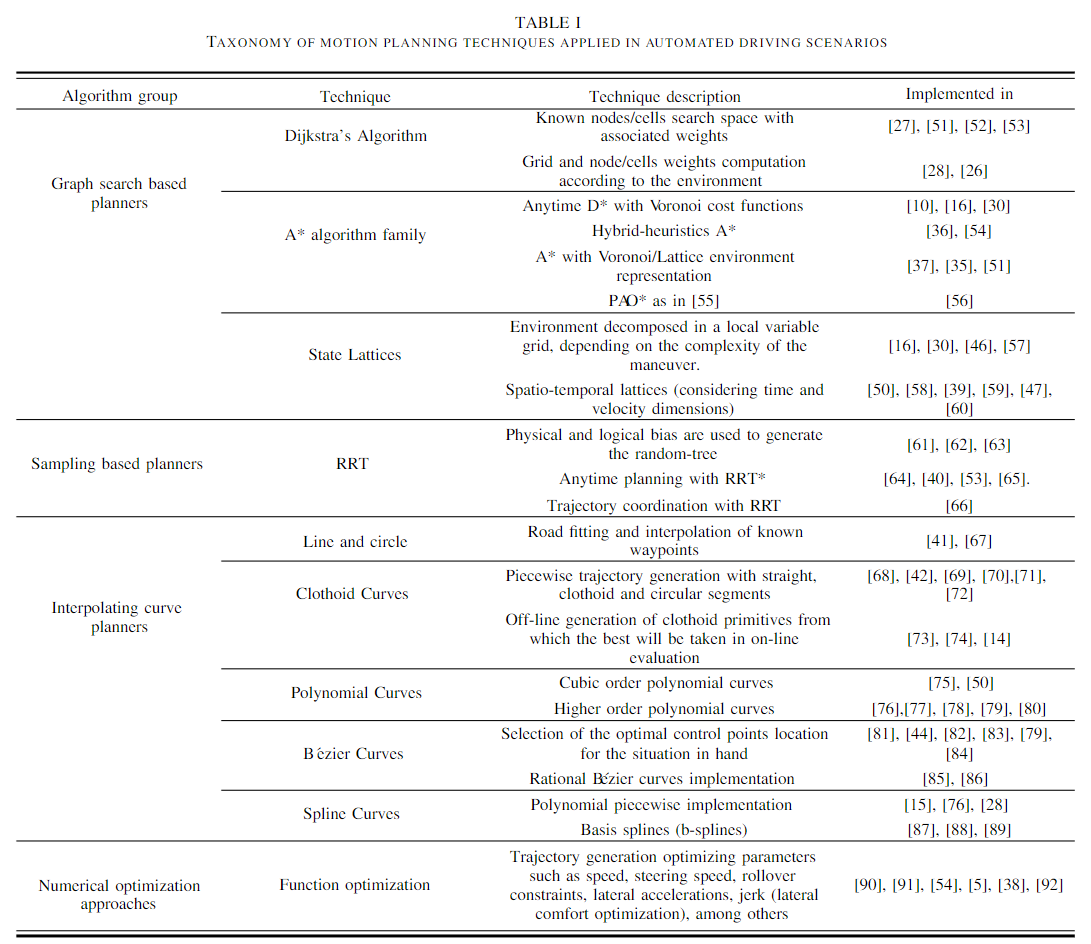
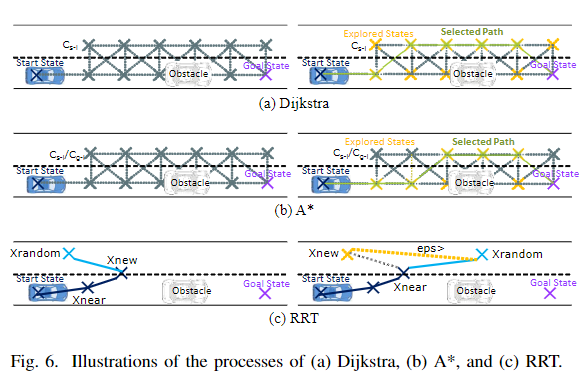
2.1 基于图搜索的规划器
Dijkstra算法:它是一种在图中寻找单源最短路径的图搜索算法。配置空间被近似为离散的网格单元空间、lattice等。
A-star算法(A)*:它是一种图搜索算法,由于实现了启发式函数,因此能够进行快速的节点搜索(它是Dijkstra图搜索算法的扩展)。它最重要的设计为代价函数的确定。移动机器人中的一些应用已经被作为改进的基础,例如动态A*(D*)、Field D* 、Theta*、Anytime repairing (ARA*)和Anytime D* (AD*)等
State Lattice算法:该算法使用带有网格状态(通常是超维状态)的规划区域的离散表示。该网格被称为state lattice,在它上面应用运动规划搜索。这个算法中的路径搜索是基于包含所有可行特征的一组lattices或者primitives的局部查询,允许车辆从一个初始状态行驶到一些其它的状态。代价函数决定了预先计算的lattices之间的最佳路径。通过不同的实现(例如A或者D)应用节点搜索算法。
2.2 基于采样的规划器
快速探索随机树(RRT):它属于基于采样的算法,其适合于在线的路径规划。它通过在导航区域执行随机搜索从而允许在半结构化空间中进行快速规划,还能够考虑非完整约束(例如车辆的最大转弯半径和动量)。然而,生成的路径不是最优的,其路径有突变且不是曲率连续的。RRT*这种新的实现收敛到一个最优的解。
2.3 插值曲线规划器
计算机辅助几何设计(CAGD)等技术通常被用作给定道路点集的路径平滑解决方案。这些允许运动规划器通过考虑可行性、舒适度、车辆动力学和其它参数来拟合给定的道路描述,以便绘制轨迹。
直线和圆圈:不同段的道路网络能够通过使用直线和圆圈对已知路径点进行插值来表示。
螺旋曲线:这种类型的曲线是根据Fresnel积分定义的。使用螺旋曲线能够定义曲率连续变化的轨迹,因为它们的曲率等价于其弧长,这使得直线段和曲线段之间平滑过渡,反之亦然。螺旋线已经被应用于公路和铁路的设计,还适用于类似车辆的机器人。
多项式曲线:这些曲线通常被实现用于满足插值点所需要的约束,即在拟合位置、角度和曲率约束等方面是有用的。
贝塞尔曲线:这些是参数化的曲线,它们依赖于控制点来定义其形状。贝塞尔曲线的核心为Bernstein多项式。这些曲线已经被广泛应用于CAGD应用、技术制图、航空和汽车设计。
样条曲线:样条曲线是在子区间上划分的分段多项式参数化曲线,它能够定义为多项式曲线、b样条曲线(也能够用贝塞尔曲线表示)或者螺旋曲线。每个子段之间的连接处被称为节点,它们通常在样条曲线的连接处具有高度平滑的约束。
2.4 数值优化
函数优化:该技术寻找函数的实数根(最小化变量输出)。它已经被实现用于改进移动机器人中障碍物和狭窄通道的势场法(PFM)
4. 自动驾驶领域智能算法
在运动规划通常被划分为高级规划和低级规划:
- 高级预测:需要做到的是通过对环境的分析,运动风险的评估,做出决策,并生成一些列的候选行为。类似于人的大脑,为行为做出指示。
- 低级反应:从高层规划中变形生成的运动。类似于小脑,不需要几乎不需要思考的产生运动,且会有应急反应,令真实的轨迹与路径有一定区别。
我们这一节将会带着上一节的内容进行更细的划分
4.1 空间配置分析(也就是我们怎么样表示地图)
空间配置分析是选择演化空间的一个去构成。它是一种集合算法,主要用于运动生成或指定时的变形。这些方法是基于几何方面的;它们指的是用粗略的分解来限制计算时间的预测方法,或者用更细的分布来更准确的反应方法。主要的困难是找到正确的空间配置参数以获得运动和环境的良好表现[41]。如果离散化太粗,碰撞风险将被很好地解释,并且不可能在两个连续的分解之间尊重运动学约束;然而,如果离散化太细,算法的实时性会很差。我们将空间分解区分为三个主要的子系列,如下图所示:采样点、连接单元和Lattice
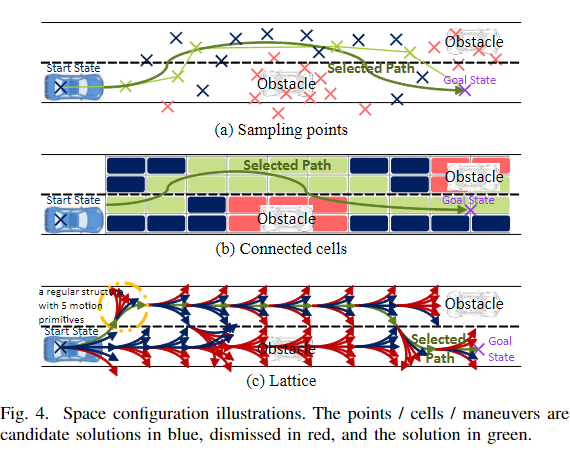
基于采样的分解:最流行的随机方法是概率道路图(PRM)[41]。它在构建阶段使用在进化空间中挑选的随机采样。这些采样点与它们的邻居相连,形成一个无障碍的路线图,然后在第二个查询阶段由寻路算法解决,例如Dijkstra(见III-B2)[42]。在[33]中,作者首先根据参考路径,例如小车道中心线,对配置空间进行采样,然后根据目标函数选择最佳采样点集,最后为路径分配一个速度曲线以尊重安全和舒适标准.
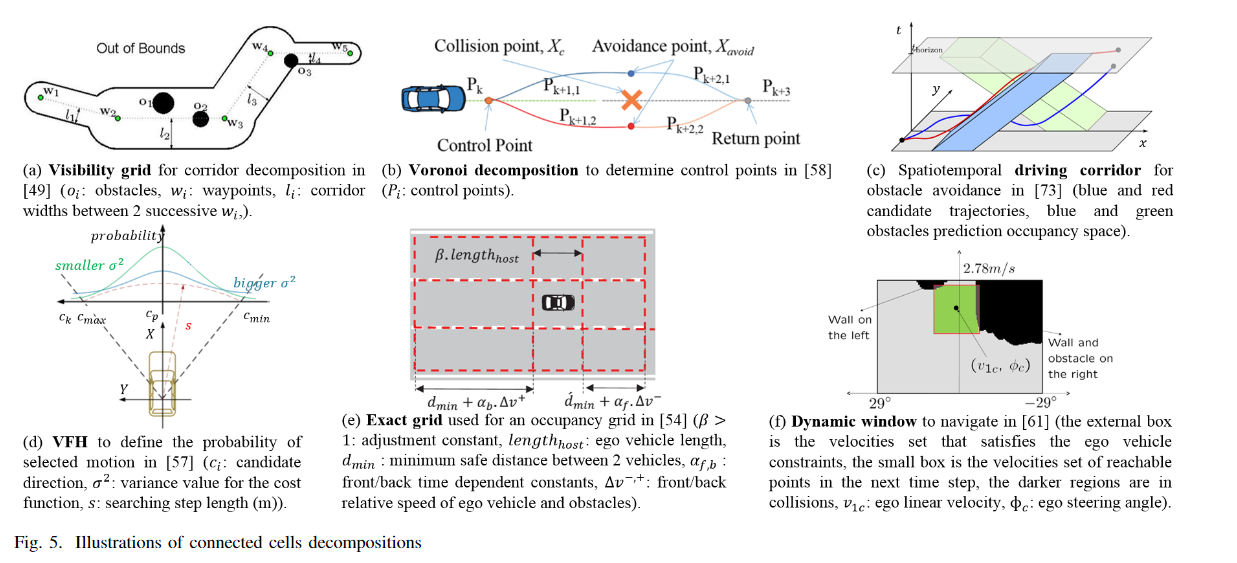
基于连接单元分解:这些方法首先利用几何学将空间分解成单元,然后构建一个占用网格和/或单元连接图,应用实例见下图。在占用网格的方法中,在小车周围生成一个网格。障碍物的检测信息被叠加在网格上。在连接图的方法中,节点代表单元,而边则是单元之间的相邻关系。该图可以被解释为沿着细胞的边缘的路径或在连接的细胞内寻找的路径。主要的方法有 visibility decomposition、Voronoi decomposition、driving corridor、Vector Field Histograms (VFH)、exact decomposition、Dynamic Window (DW)这些主要的算法
Lattice 表示法:在运动规划中,Lattice 是一种规则的空间结构,是网格的概括[22]。可以定义运动基元,将Lattice的一个状态准确地连接到另一个状态。所有由网格产生的可行状态演化被表示为机动的可达性图。Lattice表征同时汇编了道路边界和运动学约束,并且可以快速重新规划,这对高速公路规划很有用。
4.2 寻路算法
寻路算法系列是运筹学中图形理论的一个分支,用于解决图形表示下的组合概率问题。该图可以是加权的,也可以是带有采样点、单元或操纵节点的定向图。基本原理是在图中寻找路径以优化成本函数。比如Dijkstra、A*、Anytime Weighted A* (AWA*)、hybrid-state A*、D*、RRT、RRT*这些。详细的内容都已经在上面讲过了。
与基于抽样的分解类似,概率图搜索也不太适合于高速公路的结构化环境。此外,高速公路通常是一个已知的环境。从这个意义上说,在自主车辆的高速公路运动规划中,确定性的寻路方式更受青睐。
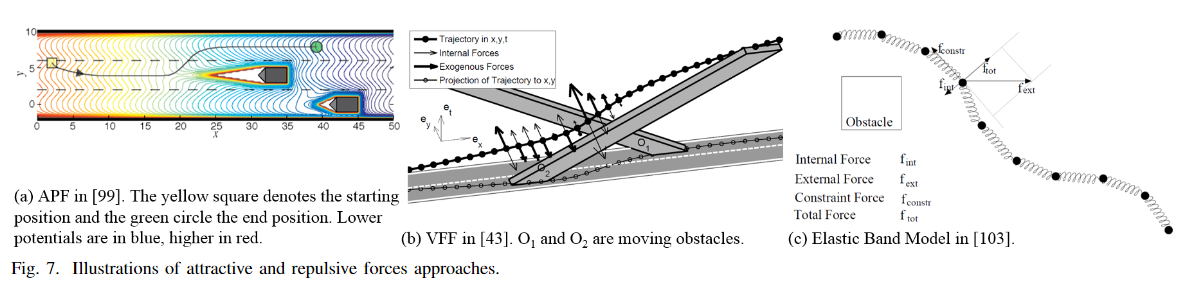
4.3 吸引力和排斥力
吸引力和排斥力的方法是一种生物仿生的方法。演化空间的符号是符号化为所需运动(如合法速度)的吸引力。障碍物的排斥力(如道路边界、车道标记、障碍物)。标线、障碍物)。因此,其主要优点是对场景表现的动态演变做出反应 对场景表现的动态演变作出反应。然后 小我私家车辆的运动是由结果的力向量引导的,因此没有明确的空间力矢量引导,因此不需要明确的空间分解。常见的方法有使用Artificial Potential Field (APF) 、Velocity Vector Field (VVF).以及elastic band algorithm。
4.4 参数化曲线和半参数化曲线
参数化和半参数化曲线是高速公路上路径规划算法的主要几何方法,至少有两个原因:
(1)高速公路的道路是由一系列简单和预定义的曲线(直线、圆和棍子[105])构成的;
(2)预定义的曲线集很容易实现,作为候选解集进行测试。


















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











