







0. 简介
随着Transformer爆火,也导致了许多以Transformer为主题框架的端到端网络的兴起,这也导致了传统自动驾驶模块化逐渐被取代,这里我们将围绕BEVFormer开始学习整体的架构,我们在上一讲《逐行逐句从BEVFormer开始学起(一)》中介绍了数据端输入。下面我们来继续学习图像特征提取与位置编码
1. 图像特征提取
首先我们回顾一下,我们拿到的数据中包含有四个参数,然后imgs的内部结构是一个torch.size为一个([1,3,6,3,736, 1280]),这里面分别代表了
- 1代表了batch_size大小
- 3代表了队列长度[对应t,t-1,t-2这三个时间的数据]
- 6是相机数量
- 3 是图像通道数
- 736, 1280 是图像的宽高
1.1 forward_train前向训练
具体对应了projects/mmdet3d_plugin/bevformer/detectors/bevformer.py中的forward_train部分代码的数据输入部分
@auto_fp16(apply_to=('img', 'prev_bev', 'points'))
def forward_train(self,
points=None,
img_metas=None,
gt_bboxes_3d=None,
gt_labels_3d=None,
gt_labels=None,
gt_bboxes=None,
img=None,
proposals=None,
gt_bboxes_ignore=None,
img_depth=None,
img_mask=None,
):
"""Forward training function.
Args:
points (list[torch.Tensor], optional): Points of each sample.
Defaults to None.
img_metas (list[dict], optional): Meta information of each sample.
Defaults to None.
gt_bboxes_3d (list[:obj:`BaseInstance3DBoxes`], optional):
Ground truth 3D boxes. Defaults to None.
gt_labels_3d (list[torch.Tensor], optional): Ground truth labels
of 3D boxes. Defaults to None.
gt_labels (list[torch.Tensor], optional): Ground truth labels
of 2D boxes in images. Defaults to None.
gt_bboxes (list[torch.Tensor], optional): Ground truth 2D boxes in
images. Defaults to None.
img (torch.Tensor optional): Images of each sample with shape
(N, C, H, W). Defaults to None.
proposals ([list[torch.Tensor], optional): Predicted proposals
used for training Fast RCNN. Defaults to None.
gt_bboxes_ignore (list[torch.Tensor], optional): Ground truth
2D boxes in images to be ignored. Defaults to None.
Returns:
dict: Losses of different branches.
"""
len_queue = img.size(1) # 3,对应了三个时刻
prev_img = img[:, :-1, ...] # 前2帧 (1, 2, 6, 3, 736, 1280)
img = img[:, -1, ...] # 当前帧 (1, 6, 3, 736, 1280)
prev_img_metas = copy.deepcopy(img_metas) # 复制img_metas信息, 3帧的信息
prev_bev = self.obtain_history_bev(prev_img, prev_img_metas) # 获取历史帧的BEV特征图 (1, 22500, 256)
img_metas = [each[len_queue-1] for each in img_metas] # 只有一帧,取出T帧的img_metas
img_feats = self.extract_feat(img=img, img_metas=img_metas) # 计算当前帧的图像特征List[(1, 6, 256, 23, 40)]
losses = dict()
losses_pts = self.forward_pts_train(img_feats, gt_bboxes_3d,
gt_labels_3d, img_metas,
gt_bboxes_ignore, prev_bev)
losses.update(losses_pts)
return losses
1.2 obtain_history_bev提取历史BEV信息
在这个当中,有一个比较关键的函数obtain_history_bev,这里面是主要的整体流程,当中pts_bbox_head这个函数是在configs/bevformer/bevformer_tiny.py下定义的BEVFormerHead。
def obtain_history_bev(self, imgs_queue, img_metas_list):
"""Obtain history BEV features iteratively. To save GPU memory, gradients are not calculated.
"""
self.eval()
with torch.no_grad():
prev_bev = None # 初始化前一帧的BEV特征图为None
bs, len_queue, num_cams, C, H, W = imgs_queue.shape # 1, 2, 6, 3, 736, 1280
imgs_queue = imgs_queue.reshape(bs*len_queue, num_cams, C, H, W) # (2, 6, 3, 736, 1280),获得batch size和len所有的图片
img_feats_list = self.extract_feat(img=imgs_queue, len_queue=len_queue) # List[(1, 2, 6, 256, 23, 40)],对应neck结果
# 逐帧处理,处理历史图像队列的图像内容
for i in range(len_queue):
img_metas = [each[i] for each in img_metas_list] # 提取该帧的img_metas信息
# img_feats = self.extract_feat(img=img, img_metas=img_metas)
img_feats = [each_scale[:, i] for each_scale in img_feats_list] # List[(1, 6, 256, 23, 44)],获取队列索引下环视的图像特征
prev_bev = self.pts_bbox_head(
img_feats, img_metas, prev_bev, only_bev=True) # 计算BEV特征图 (1, 22500, 256),这里进入BEVFormerHead
self.train()
return prev_bev # (1, 22500, 256)
1.3 extract_feat识别图像特征
这个函数结束,下一个比较重要的函数是extract_feat,这个里面img_backbone和img_neck在projects/configs/bevformer这下面有对应的图像输入设置。
@auto_fp16(apply_to=('img'))
def extract_feat(self, img, img_metas=None, len_queue=None):
"""Extract features from images and points."""
# 计算prev_bev时:(1, 2, 6, 256, 23, 40) 或 计算curr时:(1, 6, 256, 23, 40)
img_feats = self.extract_img_feat(img, img_metas, len_queue=len_queue) # 抽取图像特征
return img_feats
def extract_img_feat(self, img, img_metas, len_queue=None):
"""Extract features of images."""
B = img.size(0) # 2 torch.Size[(2,6,3,736, 1280)]
if img is not None:#判断历史图像是否存在
# input_shape = img.shape[-2:]
# # update real input shape of each single img
# for img_meta in img_metas:
# img_meta.update(input_shape=input_shape)
if img.dim() == 5 and img.size(0) == 1:
img.squeeze_()
elif img.dim() == 5 and img.size(0) > 1:#进入这个,即历史帧大于1
B, N, C, H, W = img.size() # 2, 6, 3, 736, 1280
img = img.reshape(B * N, C, H, W) # (12, 3, 736, 1280),合成到12个
if self.use_grid_mask:#
img = self.grid_mask(img)
img_feats = self.img_backbone(img) # (12, 2048, 23, 40),做完数据增强后,进入resnet,生成图像特征
if isinstance(img_feats, dict):
img_feats = list(img_feats.values())
else:
return None
if self.with_img_neck:
img_feats = self.img_neck(img_feats) # tuple((12, 256, 23, 40)),队列长度*相机,特征数量,提取特征后的分辨率
img_feats_reshaped = []
for img_feat in img_feats:
BN, C, H, W = img_feat.size() # 12, 256, 23, 40
if len_queue is not None:
# (1, 2, 6, 256, 23, 40)
img_feats_reshaped.append(img_feat.view(int(B/len_queue), len_queue, int(BN / B), C, H, W))#对neck结果去进行重新生成,再变成1,2,6的格式
else:
img_feats_reshaped.append(img_feat.view(B, int(BN / B), C, H, W))
return img_feats_reshaped # (1, 6, 256, 23, 40)
1.4 grid_mask网格掩码
这部分其实是为了做数据增强,对应的grid_mask是一个class,并在bevformer.py的初始化函数中构建
self.grid_mask = GridMask(
True, True, rotate=1, offset=False, ratio=0.5, mode=1, prob=0.7)
self.use_grid_mask = use_grid_mask # True
这种方法通过在图像上应用网格状的遮挡来增加数据集的多样性,帮助模型更好地泛化
class GridMask(nn.Module):
def __init__(self, use_h, use_w, rotate = 1, offset=False, ratio = 0.5, mode=0, prob = 1.):
super(GridMask, self).__init__()
self.use_h = use_h# 是否在垂直方向使用网格掩码
self.use_w = use_w # 是否在水平方向使用网格掩码
self.rotate = rotate # 掩码旋转的角度范围
self.offset = offset # 是否应用随机偏移
self.ratio = ratio # 掩码遮挡区域的比例
self.mode=mode# 掩码模式(0表示遮挡,1表示反转遮挡)
self.st_prob = prob
self.prob = prob # 应用掩码的概率
self.fp16_enable = False
# 置掩码应用的概率,随着训练轮次增加而变化
def set_prob(self, epoch, max_epoch):
self.prob = self.st_prob * epoch / max_epoch #+ 1.#0.5
# nn.Module, 重载forward方法,实现Grid掩码的应用,如果调用,格式是img = GridMask()(img)
@auto_fp16()
def forward(self, x):
if np.random.rand() > self.prob or not self.training:
return x
n,c,h,w = x.size()# n: batch_size, c: 通道数, h: 高, w: 宽
x = x.view(-1,h,w)# 将x变形为n*h*w的形状
hh = int(1.5*h)# 扩大1.5倍
ww = int(1.5*w)# 扩大1.5倍
d = np.random.randint(2, h)
self.l = min(max(int(d*self.ratio+0.5),1),d-1)
mask = np.ones((hh, ww), np.float32)# 初始化掩码
st_h = np.random.randint(d)
st_w = np.random.randint(d)
if self.use_h:
for i in range(hh//d):
s = d*i + st_h# 起始位置
t = min(s+self.l, hh)# 终止位置
mask[s:t,:] *= 0# 将掩码区域置0
if self.use_w:
for i in range(ww//d):
s = d*i + st_w
t = min(s+self.l, ww)
mask[:,s:t] *= 0
r = np.random.randint(self.rotate)
mask = Image.fromarray(np.uint8(mask))# 转换为PIL格式
mask = mask.rotate(r)
mask = np.asarray(mask)
mask = mask[(hh-h)//2:(hh-h)//2+h, (ww-w)//2:(ww-w)//2+w]
mask = torch.from_numpy(mask).to(x.dtype).cuda()
if self.mode == 1:
mask = 1-mask
mask = mask.expand_as(x)
if self.offset:# 是否应用随机偏移
offset = torch.from_numpy(2 * (np.random.rand(h,w) - 0.5)).to(x.dtype).cuda()
x = x * mask + offset * (1 - mask)
else:
x = x * mask
return x.view(n,c,h,w)# 返回处理后的图像/张量
这里就是我们处理过后的结果,总共2*6的图像。减少输入信息,从而完成数据增强
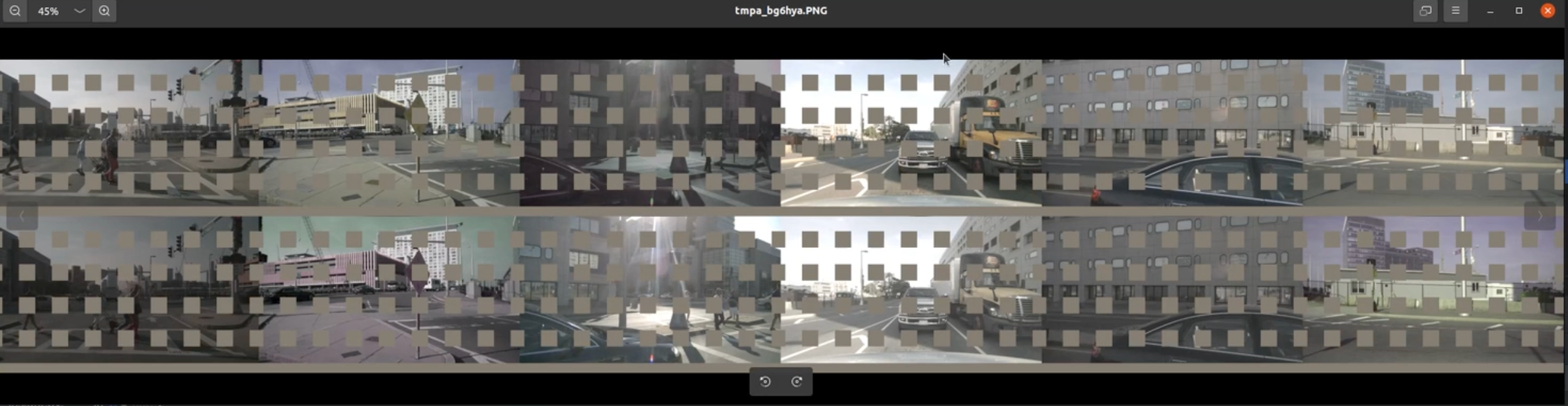
2. 位置编码
obtain_history_bev定义到的其实就是这个参数内容,到这部分其实就已经进入Transformer模块了,整个pipeline如下,主要是一些结构上的定义。主要通过反射来完成结构数据的查询。
…详情请参照古月居
256 cls_branch.append(nn.LayerNorm(self.embed_dims))
cls_branch.append(nn.ReLU(inplace=True))
cls_branch.append(Linear(self.embed_dims, self.cls_out_channels)) # 256-->10
fc_cls = nn.Sequential(*cls_branch)
reg_branch = []
for _ in range(self.num_reg_fcs): # 2
reg_branch.append(Linear(self.embed_dims, self.embed_dims)) # 256-->256
reg_branch.append(nn.ReLU())
reg_branch.append(Linear(self.embed_dims, self.code_size)) # 256-->10
reg_branch = nn.Sequential(*reg_branch)
def _get_clones(module, N):
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
# last reg_branch is used to generate proposal from
# encode feature map when as_two_stage is True.
num_pred = (self.transformer.decoder.num_layers + 1) if \
self.as_two_stage else self.transformer.decoder.num_layers # 6
if self.with_box_refine:
self.cls_branches = _get_clones(fc_cls, num_pred) # 分类和回归head复制6次
self.reg_branches = _get_clones(reg_branch, num_pred)
else:
self.cls_branches = nn.ModuleList(
[fc_cls for _ in range(num_pred)])
self.reg_branches = nn.ModuleList(
[reg_branch for _ in range(num_pred)])
if not self.as_two_stage:
self.bev_embedding = nn.Embedding(
self.bev_h * self.bev_w, self.embed_dims) # (22500, 256),申明一个矩阵,对应了bev图像中的宽高,以及维度信息
self.query_embedding = nn.Embedding(self.num_query,
self.embed_dims * 2) # (900, 512)
### 2.2 Transformer 头forward前向传播
通过`img_feats = self.extract_img_feat(img, img_metas, len_queue=len_queue)`传入了这些参数,用于前向传播。
```python
@auto_fp16(apply_to=('mlvl_feats'))
def forward(self, mlvl_feats, img_metas, prev_bev=None, only_bev=False):
"""Forward function.
Args:
mlvl_feats (tuple[Tensor]): Features from the upstream
network, each is a 5D-tensor with shape
(B, N, C, H, W).
prev_bev: previous bev featues
only_bev: only compute BEV features with encoder.
Returns:
all_cls_scores (Tensor): Outputs from the classification head, \
shape [nb_dec, bs, num_query, cls_out_channels]. Note \
cls_out_channels should includes background.
all_bbox_preds (Tensor): Sigmoid outputs from the regression \
head with normalized coordinate format (cx, cy, w, l, cz, h, theta, vx, vy). \
Shape [nb_dec, bs, num_query, 9].
"""
bs, num_cam, _, _, _ = mlvl_feats[0].shape # (1, 6, 256, 23, 40)
dtype = mlvl_feats[0].dtype # torch.float32
object_query_embeds = self.query_embedding.weight.to(dtype) # (900, 512),这个在前面init定义过,并拿出对应的weight。
bev_queries = self.bev_embedding.weight.to(dtype) # (150*150, 256) 可学习query(Embeding)
bev_mask = torch.zeros((bs, self.bev_h, self.bev_w),
device=bev_queries.device).to(dtype) # (1, 150, 150)
bev_pos = self.positional_encoding(bev_mask).to(dtype) # (1, 256, 150, 150) 可学习位置编码。这里只用到了bev_mask的shape和device信息,与bev_mask无关
if only_bev: # only use encoder to obtain BEV features, TODO: refine the workaround,要么走get_bev_features要么就是forward
return self.transformer.get_bev_features(
mlvl_feats, # (1, 6, 256, 23, 40)
bev_queries, # (22500, 256)
self.bev_h, # 150
self.bev_w, # 150
grid_length=(self.real_h / self.bev_h, # 102.4 / 150
self.real_w / self.bev_w),
bev_pos=bev_pos, # (1, 256, 150, 150)
img_metas=img_metas,
prev_bev=prev_bev, # None或(1, 22500, 256)
) # -->(1, 22500, 256)
else:
outputs = self.transformer(
mlvl_feats, # (1, 6, 256, 23, 40)
bev_queries, # (22500, 256)
object_query_embeds, # (900, 512)
self.bev_h, # 150
self.bev_w, # 150
grid_length=(self.real_h / self.bev_h, # 102.4 / 150 = 0.6826
self.real_w / self.bev_w),
bev_pos=bev_pos, # (1, 256, 150, 150)
reg_branches=self.reg_branches if self.with_box_refine else None, # 6层
cls_branches=self.cls_branches if self.as_two_stage else None, # 6层
img_metas=img_metas, # 当前帧的img_metas
prev_bev=prev_bev # (1, 22500, 256)
)
"""
bev_embed:(22500, 1, 256) bev的拉直嵌入
hs:(6, 900, 1, 256) 内部decoder layer输出的object query
init_reference:(1, 900, 3) 随机初始化的参考点(可学习)
inter_references:(6, 1, 900, 3) 内部decoder layer输出的参考点
"""
bev_embed, hs, init_reference, inter_references = outputs
hs = hs.permute(0, 2, 1, 3) # (6, 900, 1, 256)-->(6, 1, 900, 256)
outputs_classes = []
outputs_coords = []
# 逐个隐藏层处理
for lvl in range(hs.shape[0]):
if lvl == 0:
reference = init_reference # (1, 900, 3) 对于第0层,则取初始参考点
else:
reference = inter_references[lvl - 1] # 其余层则取上一层的参考点,参考点都是在0~1之间的
reference = inverse_sigmoid(reference) # 对参考点取逆sigmoid (1, 900, 3) 真实位置
# 对每一层新的query再次分类和回归
outputs_class = self.cls_branches[lvl](hs[lvl]) # (1, 900, 10)
tmp = self.reg_branches[lvl](hs[lvl]) # (1, 900, 10)
# TODO: check the shape of reference
assert reference.shape[-1] == 3
# 实际参考点+偏移量
tmp[..., 0:2] += reference[..., 0:2] # x和y
tmp[..., 0:2] = tmp[..., 0:2].sigmoid() # 取sigmoid限制在0~1之间
tmp[..., 4:5] += reference[..., 2:3] # z
tmp[..., 4:5] = tmp[..., 4:5].sigmoid()
# 恢复lidar坐标系下中心点的实际坐标
tmp[..., 0:1] = (tmp[..., 0:1] * (self.pc_range[3] -
self.pc_range[0]) + self.pc_range[0])
tmp[..., 1:2] = (tmp[..., 1:2] * (self.pc_range[4] -
self.pc_range[1]) + self.pc_range[1])
tmp[..., 4:5] = (tmp[..., 4:5] * (self.pc_range[5] -
self.pc_range[2]) + self.pc_range[2])
# TODO: check if using sigmoid
outputs_coord = tmp
outputs_classes.append(outputs_class) # 将分类预测加入outputs list (1, 900, 10)
outputs_coords.append(outputs_coord) # 将回归预测加入outputs list (1, 900, 10)
outputs_classes = torch.stack(outputs_classes) # (6, 1, 900, 10)
outputs_coords = torch.stack(outputs_coords) # (6, 1, 900, 10)
outs = {
'bev_embed': bev_embed, # (22500, 1, 256)
'all_cls_scores': outputs_classes, # (6, 1, 900, 10)
'all_bbox_preds': outputs_coords, # (6, 1, 900, 10)
'enc_cls_scores': None,
'enc_bbox_preds': None,
}
return outs
2.3 positional_encoding
positional_encoding也是在配置中定义的,其type是LearnedPositionalEncoding。这个是mmdet3d当中自带的
[docs]@POSITIONAL_ENCODING.register_module()
class LearnedPositionalEncoding(nn.Module):
"""Position embedding with learnable embedding weights.
Args:
num_feats (int): The feature dimension for each position
along x-axis or y-axis. The final returned dimension for
each position is 2 times of this value.
row_num_embed (int, optional): The dictionary size of row embeddings.
Default 50.
col_num_embed (int, optional): The dictionary size of col embeddings.
Default 50.
"""
def __init__(self, num_feats, row_num_embed=50, col_num_embed=50):
super(LearnedPositionalEncoding, self).__init__()
self.row_embed = nn.Embedding(row_num_embed, num_feats)# 150 * 256,数量*维度
self.col_embed = nn.Embedding(col_num_embed, num_feats)# 150 * 256
self.num_feats = num_feats
self.row_num_embed = row_num_embed
self.col_num_embed = col_num_embed
self.init_weights()
[docs] def init_weights(self):
"""Initialize the learnable weights."""
uniform_init(self.row_embed)
uniform_init(self.col_embed)
[docs] def forward(self, mask):
"""Forward function for `LearnedPositionalEncoding`.
Args:
mask (Tensor): ByteTensor mask. Non-zero values representing
ignored positions, while zero values means valid positions
for this image. Shape [bs, h, w].
Returns:
pos (Tensor): Returned position embedding with shape
[bs, num_feats*2, h, w].
"""
h, w = mask.shape[-2:]# 拿到的是mask值150*150
x = torch.arange(w, device=mask.device)# 0-49的值
y = torch.arange(h, device=mask.device)
x_embed = self.col_embed(x)# 取出对应的weight
y_embed = self.row_embed(y)
pos = torch.cat(
(x_embed.unsqueeze(0).repeat(h, 1, 1), y_embed.unsqueeze(1).repeat(
1, w, 1)),
dim=-1).permute(2, 0,
1).unsqueeze(0).repeat(mask.shape[0], 1, 1, 1)
return pos
def __repr__(self):
"""str: a string that describes the module"""
repr_str = self.__class__.__name__
repr_str += f'(num_feats={self.num_feats}, '
repr_str += f'row_num_embed={self.row_num_embed}, '
repr_str += f'col_num_embed={self.col_num_embed})'
return repr_str


















 2186
2186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











