







0. 简介
随着Transformer爆火,也导致了许多以Transformer为主题框架的端到端网络的兴起,这也导致了传统自动驾驶模块化逐渐被取代,这里我们将围绕BEVFormer开始学习整体的架构,我们在上一讲《逐行逐句从BEVFormer开始学起(四)》中介绍了Encoder的各种操作,这一章节我们来简单的看一下Decoder以及loss求解。这也是我们BEVFormer的最后一节了
1. Decoder解码器操作
我们其实第三讲和第四讲都围绕着get_bev_features以及内部的encoder编码器函数,下面其实就是decoder解码器以及loss求解函数了
bs = mlvl_feats[0].size(0) # 1
query_pos, query = torch.split(object_query_embed, self.embed_dims, dim=1) # (900, 156)和(900, 156)
query_pos = query_pos.unsqueeze(0).expand(bs, -1, -1) # (1, 900, 156)
query = query.unsqueeze(0).expand(bs, -1, -1) # (1, 900, 156)
reference_points = self.reference_points(query_pos) # 256-->3 (1, 900, 3)
reference_points = reference_points.sigmoid() # (1, 900, 3)
init_reference_out = reference_points # 初始参考点(随机初始化)
query = query.permute(1, 0, 2) # (900, 1, 256)
query_pos = query_pos.permute(1, 0, 2) # (900, 1, 256)
bev_embed = bev_embed.permute(1, 0, 2) # (22500, 1, 256)
# (6, 900, 1, 256)和(6, 1, 900, 3)
inter_states, inter_references = self.decoder(
query=query, # (900, 1, 256)
key=None,
value=bev_embed, # (22500, 1, 256)
query_pos=query_pos, # (900, 1, 256)
reference_points=reference_points, # (1, 900, 3)
reg_branches=reg_branches, # 6层
cls_branches=cls_branches, # None
spatial_shapes=torch.tensor([[bev_h, bev_w]], device=query.device), # [[150, 150]]
level_start_index=torch.tensor([0], device=query.device), # [0]
**kwargs)
inter_references_out = inter_references # 内部decoder layer输出的参考点 (6, 1, 900, 3)
"""
bev_embed:(22500, 1, 256) bev的拉直嵌入,t-2,t-1,t的特征
inter_states:(6, 900, 1, 256) 内部decoder layer输出的object query
init_reference_out:(1, 900, 3) 随机初始化的参考点(可学习)
inter_references_out:(6, 1, 900, 3) 内部decoder layer输出的参考点
"""
return bev_embed, inter_states, init_reference_out, inter_references_out

1.1 DetectionTransformerDecoder解码器函数
下面我们来稍微看一下self.decoder函数,对应的tiny文件的反射参数为:
decoder=dict(
type='DetectionTransformerDecoder',
num_layers=6,
return_intermediate=True,
transformerlayers=dict(
type='DetrTransformerDecoderLayer',
attn_cfgs=[
dict(
type='MultiheadAttention',
embed_dims=_dim_,
num_heads=8,
dropout=0.1),
dict(
type='CustomMSDeformableAttention',
embed_dims=_dim_,
num_levels=1),
],
feedforward_channels=_ffn_dim_,
ffn_dropout=0.1,
operation_order=('self_attn', 'norm', 'cross_attn', 'norm',
'ffn', 'norm')))),
下面我们来看一下详细的DetectionTransformerDecoder函数和CustomMSDeformableAttention函数。它们实现了DETR3D中的解码器和用于Deformable DETR的自定义多尺度可变形注意力模块。
-
DetectionTransformerDecoder类:- 继承自
TransformerLayerSequence,实现了DETR3D transformer中的解码器。 - 包含初始化函数和前向传播函数。
- 在前向传播过程中,迭代应用每一层,并在有必要时更新参考点。
- 支持返回中间输出结果。
- 继承自
-
CustomMSDeformableAttention类:- 继承自
BaseModule,实现了用于Deformable DETR的多尺度可变形注意力模块。 - 包含初始化函数、权重初始化函数和前向传播函数。
- 在前向传播过程中,计算采样偏移量和注意力权重,并通过多尺度可变形注意力函数计算输出。
- 继承自
@TRANSFORMER_LAYER_SEQUENCE.register_module()
class DetectionTransformerDecoder(TransformerLayerSequence):
"""Implements the decoder in DETR3D transformer.
Args:
return_intermediate (bool): Whether to return intermediate outputs.
coder_norm_cfg (dict): Config of last normalization layer. Default:
`LN`.
"""
def __init__(self, *args, return_intermediate=False, **kwargs):
super(DetectionTransformerDecoder, self).__init__(*args, **kwargs)
self.return_intermediate = return_intermediate # True
self.fp16_enabled = False
def forward(self,
query,
*args,
reference_points=None,
reg_branches=None,
key_padding_mask=None,
**kwargs):
"""Forward function for `Detr3DTransformerDecoder`.
Args:
query (Tensor): Input query with shape
`(num_query, bs, embed_dims)`.
reference_points (Tensor): The reference
points of offset. has shape
(bs, num_query, 4) when as_two_stage,
otherwise has shape ((bs, num_query, 2).
reg_branch: (obj:`nn.ModuleList`): Used for
refining the regression results. Only would
be passed when with_box_refine is True,
otherwise would be passed a `None`.
Returns:
Tensor: Results with shape [1, num_query, bs, embed_dims] when
return_intermediate is `False`, otherwise it has shape
[num_layers, num_query, bs, embed_dims].
"""
output = query # (900, 1, 256)
intermediate = []
intermediate_reference_points = []
for lid, layer in enumerate(self.layers):# 6层decoder
reference_points_input = reference_points[..., :2].unsqueeze(
2) # BS NUM_QUERY NUM_LEVEL 2 --> (1, 900, 1, 2)
output = layer(
output, # (900, 1, 256)
*args,
reference_points=reference_points_input, # (1, 900, 1, 2)
key_padding_mask=key_padding_mask, # None
**kwargs) # (900, 1, 256)
output = output.permute(1, 0, 2) # (900, 1, 256)-->(1, 900, 256)
if reg_branches is not None:
tmp = reg_branches[lid](output) # (1, 900, 10) 对每一次输出做了一个预测,xyz,长宽高,yaw偏航角,速度
assert reference_points.shape[-1] == 3
new_reference_points = torch.zeros_like(reference_points) # (1, 900, 3)
# 在原参考点(真实坐标逆sigmoid)基础上+预测值(偏移量)
new_reference_points[..., :2] = tmp[
..., :2] + inverse_sigmoid(reference_points[..., :2]) # (1, 900, 2)
# 此时新参考点是真实坐标,不是0-1之间
new_reference_points[..., 2:3] = tmp[
..., 4:5] + inverse_sigmoid(reference_points[..., 2:3]) # (1, 900, 1)
new_reference_points = new_reference_points.sigmoid() # (1, 900, 3)
# 参考点的计算不参与反向传播,而且均经过sigmoid,归一化到0~1之间
reference_points = new_reference_points.detach() # (1, 900, 3)
output = output.permute(1, 0, 2) # (900, 1, 256)
if self.return_intermediate:
intermediate.append(output) # 记录中间预测值输出 (900, 1, 256)
intermediate_reference_points.append(reference_points) # 记录参考点 (900, 1, 3)
if self.return_intermediate:
return torch.stack(intermediate), torch.stack(
intermediate_reference_points) # (6, 900 1, 256)和 (6, 1, 900, 3)
return output, reference_points
@ATTENTION.register_module()
class CustomMSDeformableAttention(BaseModule):
"""An attention module used in Deformable-Detr.
`Deformable DETR: Deformable Transformers for End-to-End Object Detection.
<https://arxiv.org/pdf/2010.04159.pdf>`_.
Args:
embed_dims (int): The embedding dimension of Attention.
Default: 256.
num_heads (int): Parallel attention heads. Default: 64.
num_levels (int): The number of feature map used in
Attention. Default: 4.
num_points (int): The number of sampling points for
each query in each head. Default: 4.
im2col_step (int): The step used in image_to_column.
Default: 64.
dropout (float): A Dropout layer on `inp_identity`.
Default: 0.1.
batch_first (bool): Key, Query and Value are shape of
(batch, n, embed_dim)
or (n, batch, embed_dim). Default to False.
norm_cfg (dict): Config dict for normalization layer.
Default: None.
init_cfg (obj:`mmcv.ConfigDict`): The Config for initialization.
Default: None.
"""
def __init__(self,
embed_dims=256,
num_heads=8,
num_levels=4,
num_points=4,
im2col_step=64,
dropout=0.1,
batch_first=False,
norm_cfg=None,
init_cfg=None):
super().__init__(init_cfg)
if embed_dims % num_heads != 0:
raise ValueError(f'embed_dims must be divisible by num_heads, '
f'but got {embed_dims} and {num_heads}')
dim_per_head = embed_dims // num_heads
self.norm_cfg = norm_cfg # LN
self.dropout = nn.Dropout(dropout) # 0.1
self.batch_first = batch_first # False
self.fp16_enabled = False
# you'd better set dim_per_head to a power of 2
# which is more efficient in the CUDA implementation
def _is_power_of_2(n):
if (not isinstance(n, int)) or (n < 0):
raise ValueError(
'invalid input for _is_power_of_2: {} (type: {})'.format(
n, type(n)))
return (n & (n - 1) == 0) and n != 0
if not _is_power_of_2(dim_per_head):
warnings.warn(
"You'd better set embed_dims in "
'MultiScaleDeformAttention to make '
'the dimension of each attention head a power of 2 '
'which is more efficient in our CUDA implementation.')
self.im2col_step = im2col_step # 64
self.embed_dims = embed_dims # 256
self.num_levels = num_levels # 1
self.num_heads = num_heads # 8
self.num_points = num_points # 4
self.sampling_offsets = nn.Linear(
embed_dims, num_heads * num_levels * num_points * 2) # 256-->8 * 1 * 4 * 2 = 64
self.attention_weights = nn.Linear(embed_dims,
num_heads * num_levels * num_points) # 256-->8 * 1 * 4=32
self.value_proj = nn.Linear(embed_dims, embed_dims) # 256-->256
self.output_proj = nn.Linear(embed_dims, embed_dims) # 256-->256
self.init_weights()
def init_weights(self):
"""Default initialization for Parameters of Module."""
constant_init(self.sampling_offsets, 0.)
thetas = torch.arange(
self.num_heads,
dtype=torch.float32) * (2.0 * math.pi / self.num_heads)
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
grid_init = (grid_init /
grid_init.abs().max(-1, keepdim=True)[0]).view(
self.num_heads, 1, 1,
2).repeat(1, self.num_levels, self.num_points, 1)
for i in range(self.num_points):
grid_init[:, :, i, :] *= i + 1
self.sampling_offsets.bias.data = grid_init.view(-1)
constant_init(self.attention_weights, val=0., bias=0.)
xavier_init(self.value_proj, distribution='uniform', bias=0.)
xavier_init(self.output_proj, distribution='uniform', bias=0.)
self._is_init = True
@deprecated_api_warning({'residual': 'identity'},
cls_name='MultiScaleDeformableAttention')
def forward(self,
query,
key=None,
value=None,
identity=None,
query_pos=None,
key_padding_mask=None,
reference_points=None,
spatial_shapes=None,
level_start_index=None,
flag='decoder',
**kwargs):
"""Forward Function of MultiScaleDeformAttention.
Args:
query (Tensor): Query of Transformer with shape
(num_query, bs, embed_dims).
key (Tensor): The key tensor with shape
`(num_key, bs, embed_dims)`.
value (Tensor): The value tensor with shape
`(num_key, bs, embed_dims)`.
identity (Tensor): The tensor used for addition, with the
same shape as `query`. Default None. If None,
`query` will be used.
query_pos (Tensor): The positional encoding for `query`.
Default: None.
key_pos (Tensor): The positional encoding for `key`. Default
None.
reference_points (Tensor): The normalized reference
points with shape (bs, num_query, num_levels, 2),
all elements is range in [0, 1], top-left (0,0),
bottom-right (1, 1), including padding area.
or (N, Length_{query}, num_levels, 4), add
additional two dimensions is (w, h) to
form reference boxes.
key_padding_mask (Tensor): ByteTensor for `query`, with
shape [bs, num_key].
spatial_shapes (Tensor): Spatial shape of features in
different levels. With shape (num_levels, 2),
last dimension represents (h, w).
level_start_index (Tensor): The start index of each level.
A tensor has shape ``(num_levels, )`` and can be represented
as [0, h_0*w_0, h_0*w_0+h_1*w_1, ...].
Returns:
Tensor: forwarded results with shape [num_query, bs, embed_dims].
"""
if value is None:
value = query # (1, 22500, 256)
if identity is None:
identity = query # (1, 900, 256)
if query_pos is not None:
query = query + query_pos # (1, 900, 256)
if not self.batch_first:
# change to (bs, num_query ,embed_dims)
query = query.permute(1, 0, 2)
value = value.permute(1, 0, 2)
bs, num_query, _ = query.shape # (1, 900, _)
bs, num_value, _ = value.shape # (1, 22500, _)
assert (spatial_shapes[:, 0] * spatial_shapes[:, 1]).sum() == num_value
value = self.value_proj(value) # (1, 22500, 256)
if key_padding_mask is not None:
value = value.masked_fill(key_padding_mask[..., None], 0.0)
value = value.view(bs, num_value, self.num_heads, -1) # (1, 22500, 8, 32)
# (1, 900, 64) --> (1, 900, 8, 1, 4, 2)
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)
# (1, 900, 64) --> (1, 900, 8, 4)
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_levels * self.num_points)
attention_weights = attention_weights.softmax(-1) # (1, 900, 8, 4)
attention_weights = attention_weights.view(bs, num_query,
self.num_heads,
self.num_levels,
self.num_points) # (1, 900, 8, 1, 4)
if reference_points.shape[-1] == 2:
# [[150, 150]] --> (1, 2)
offset_normalizer = torch.stack(
[spatial_shapes[..., 1], spatial_shapes[..., 0]], -1)
# (1, 900, 1, 1, 1, 2) + (1, 900, 8, 1, 4, 2) / (1, 1, 1, 1, 1, 2) --> (1, 900, 8, 1, 4, 2)
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets \
/ offset_normalizer[None, None, None, :, None, :]
elif reference_points.shape[-1] == 4:
sampling_locations = reference_points[:, :, None, :, None, :2] \
+ sampling_offsets / self.num_points \
* reference_points[:, :, None, :, None, 2:] \
* 0.5
else:
raise ValueError(
f'Last dim of reference_points must be'
f' 2 or 4, but get {reference_points.shape[-1]} instead.')
if torch.cuda.is_available() and value.is_cuda:
# using fp16 deformable attention is unstable because it performs many sum operations
if value.dtype == torch.float16:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
else:
MultiScaleDeformableAttnFunction = MultiScaleDeformableAttnFunction_fp32
output = MultiScaleDeformableAttnFunction.apply(
value, spatial_shapes, level_start_index, sampling_locations,
attention_weights, self.im2col_step) # (1, 900, 256)
else:
output = multi_scale_deformable_attn_pytorch(
value, spatial_shapes, sampling_locations, attention_weights)
output = self.output_proj(output) # (1, 900, 256)
if not self.batch_first:
# (num_query, bs ,embed_dims)
output = output.permute(1, 0, 2) # (900, 1, 256)
return self.dropout(output) + identity # (900, 1, 256)
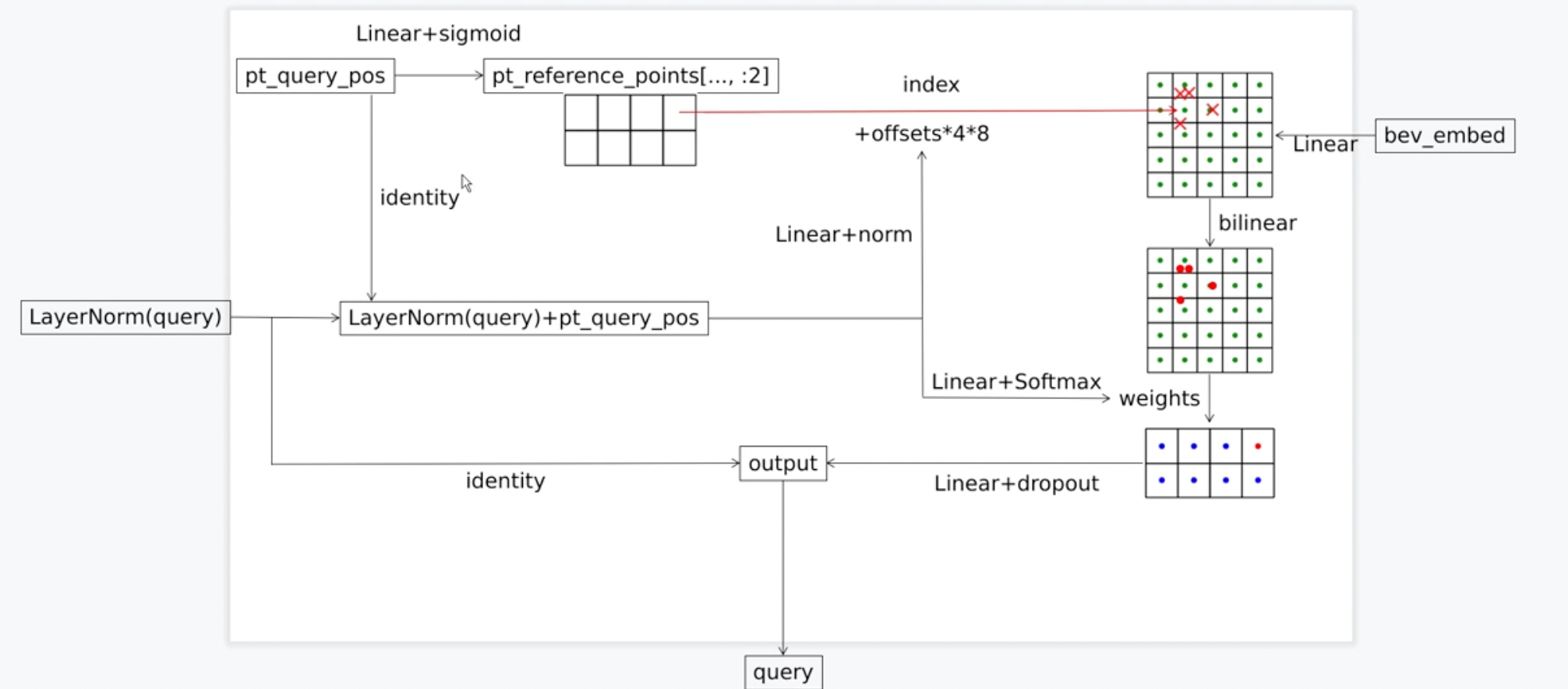
2. 分类回归预测
到这一步其实Transformer里面所有的内容就已经讲完了,下面我们回到bevformer_head.py这个函数中,并来进一步看一下分类回归预测模块
"""
bev_embed:(22500, 1, 256) bev的拉直嵌入
hs:(6, 900, 1, 256) 内部decoder layer输出的object query
init_reference:(1, 900, 3) 随机初始化的参考点(可学习)
inter_references:(6, 1, 900, 3) 内部decoder layer输出的参考点
"""
bev_embed, hs, init_reference, inter_references = outputs
hs = hs.permute(0, 2, 1, 3) # (6, 900, 1, 256)-->(6, 1, 900, 256)
outputs_classes = []
outputs_coords = []
# 逐个隐藏层处理
for lvl in range(hs.shape[0]):
if lvl == 0:
reference = init_reference # (1, 900, 3) 对于第0层,则取初始参考点
else:
reference = inter_references[lvl - 1] # 其余层则取上一层的参考点,参考点都是在0~1之间的
reference = inverse_sigmoid(reference) # 对参考点取逆sigmoid (1, 900, 3) 真实位置,去除归一化
# 对每一层新的query再次分类和回归
outputs_class = self.cls_branches[lvl](hs[lvl]) # (1, 900, 10)
tmp = self.reg_branches[lvl](hs[lvl]) # (1, 900, 10),这个和tmp = reg_branches[lid](output) 保持一致
# TODO: check the shape of reference
assert reference.shape[-1] == 3
# 实际参考点+偏移量
tmp[..., 0:2] += reference[..., 0:2] # x和y
tmp[..., 0:2] = tmp[..., 0:2].sigmoid() # 取sigmoid限制在0~1之间
tmp[..., 4:5] += reference[..., 2:3] # z
tmp[..., 4:5] = tmp[..., 4:5].sigmoid()
# 恢复lidar坐标系下中心点的实际坐标
tmp[..., 0:1] = (tmp[..., 0:1] * (self.pc_range[3] -
self.pc_range[0]) + self.pc_range[0])
tmp[..., 1:2] = (tmp[..., 1:2] * (self.pc_range[4] -
self.pc_range[1]) + self.pc_range[1])
tmp[..., 4:5] = (tmp[..., 4:5] * (self.pc_range[5] -
self.pc_range[2]) + self.pc_range[2])
# TODO: check if using sigmoid
outputs_coord = tmp
outputs_classes.append(outputs_class) # 将分类预测加入outputs list (1, 900, 10)
outputs_coords.append(outputs_coord) # 将回归预测加入outputs list (1, 900, 10)
outputs_classes = torch.stack(outputs_classes) # (6, 1, 900, 10)
outputs_coords = torch.stack(outputs_coords) # (6, 1, 900, 10)
outs = {
'bev_embed': bev_embed, # (22500, 1, 256)
'all_cls_scores': outputs_classes, # (6, 1, 900, 10)
'all_bbox_preds': outputs_coords, # (6, 1, 900, 10)
'enc_cls_scores': None,
'enc_bbox_preds': None,
}
return outs
到这一步,forward也已经结束了根据代码,我们可以看到下面就是计算loss信息
outs = self.pts_bbox_head(
pts_feats, img_metas, prev_bev)
loss_inputs = [gt_bboxes_3d, gt_labels_3d, outs]
losses = self.pts_bbox_head.loss(*loss_inputs, img_metas=img_metas)
return losses
3. loss信息计算
@force_fp32(apply_to=('preds_dicts'))
def loss(self,
gt_bboxes_list,
gt_labels_list,
preds_dicts,
gt_bboxes_ignore=None,
img_metas=None):
""""Loss function.
Args:
gt_bboxes_list (list[Tensor]): Ground truth bboxes for each image
with shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels_list (list[Tensor]): Ground truth class indices for each
image with shape (num_gts, ).
preds_dicts:
all_cls_scores (Tensor): Classification score of all
decoder layers, has shape
[nb_dec, bs, num_query, cls_out_channels].
all_bbox_preds (Tensor): Sigmoid regression
outputs of all decode layers. Each is a 4D-tensor with
normalized coordinate format (cx, cy, w, h) and shape
[nb_dec, bs, num_query, 4].
enc_cls_scores (Tensor): Classification scores of
points on encode feature map , has shape
(N, h*w, num_classes). Only be passed when as_two_stage is
True, otherwise is None.
enc_bbox_preds (Tensor): Regression results of each points
on the encode feature map, has shape (N, h*w, 4). Only be
passed when as_two_stage is True, otherwise is None.
gt_bboxes_ignore (list[Tensor], optional): Bounding boxes
which can be ignored for each image. Default None.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
assert gt_bboxes_ignore is None, \
f'{self.__class__.__name__} only supports ' \
f'for gt_bboxes_ignore setting to None.'
all_cls_scores = preds_dicts['all_cls_scores'] # (6, 1, 900, 10)
all_bbox_preds = preds_dicts['all_bbox_preds'] # (6, 1, 900, 10)
enc_cls_scores = preds_dicts['enc_cls_scores'] # None
enc_bbox_preds = preds_dicts['enc_bbox_preds'] # None
num_dec_layers = len(all_cls_scores) # 6
device = gt_labels_list[0].device
gt_bboxes_list = [torch.cat(
(gt_bboxes.gravity_center, gt_bboxes.tensor[:, 3:]),
dim=1).to(device) for gt_bboxes in gt_bboxes_list] # (45, 9)
all_gt_bboxes_list = [gt_bboxes_list for _ in range(num_dec_layers)] # 复制6份
all_gt_labels_list = [gt_labels_list for _ in range(num_dec_layers)]
all_gt_bboxes_ignore_list = [
gt_bboxes_ignore for _ in range(num_dec_layers)
] # None
# 逐层计算loss
losses_cls, losses_bbox = multi_apply(
self.loss_single, all_cls_scores, all_bbox_preds,
all_gt_bboxes_list, all_gt_labels_list,
all_gt_bboxes_ignore_list) # 6层的分类和回归损失 List[Tensor:6]
loss_dict = dict()
# loss of proposal generated from encode feature map.
if enc_cls_scores is not None:
binary_labels_list = [
torch.zeros_like(gt_labels_list[i])
for i in range(len(all_gt_labels_list))
]
enc_loss_cls, enc_losses_bbox = \
self.loss_single(enc_cls_scores, enc_bbox_preds,
gt_bboxes_list, binary_labels_list, gt_bboxes_ignore)
loss_dict['enc_loss_cls'] = enc_loss_cls
loss_dict['enc_loss_bbox'] = enc_losses_bbox
# loss from the last decoder layer 记录最后一层的损失
loss_dict['loss_cls'] = losses_cls[-1]
loss_dict['loss_bbox'] = losses_bbox[-1]
# loss from other decoder layers 记录其他层的损失
num_dec_layer = 0
for loss_cls_i, loss_bbox_i in zip(losses_cls[:-1],
losses_bbox[:-1]): # d0~d4
loss_dict[f'd{num_dec_layer}.loss_cls'] = loss_cls_i
loss_dict[f'd{num_dec_layer}.loss_bbox'] = loss_bbox_i
num_dec_layer += 1
return loss_dict
loss部分相关的算法包含了下面的算法


















 1458
1458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











