







VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
简介
-
3D点云中物体的精确检测是许多应用中的一个核心问题,为了将高度稀疏的激光雷达点云与区域建议网络(RPN)进行接口。处理LIDAR点云的难点:点云稀疏、点云密度变化、点云数量比较多(约100k个点),基本思想:将点云使用voxel栅格化、且在每个voxel进行特征编码,使其转变为4D tensor。接下来使用卷积的方法就可以了。对于3D体素的特征编码一般有两种方式:
- 手工制作特征表示,例如,鸟瞰投影。
- 机器学习的特征表示,例如,VoxelNet,pointnet
-
由于手动设计选择引入了一个信息瓶颈,阻止这些方法有效地利用3D形状信息和检测任务所需的不变性,所以提出了VoxelNet,一个通用的3D检测网络,统一特征提取和包围盒预测的过程整合进一个阶段,实现端到端可训练的深度学习网络。关键是voxel feature encoding (VFE) layer的构建,能自动学习有效的有鉴别力的特征,最后通过RPN来输出detection box。
3D目标检测整体框架
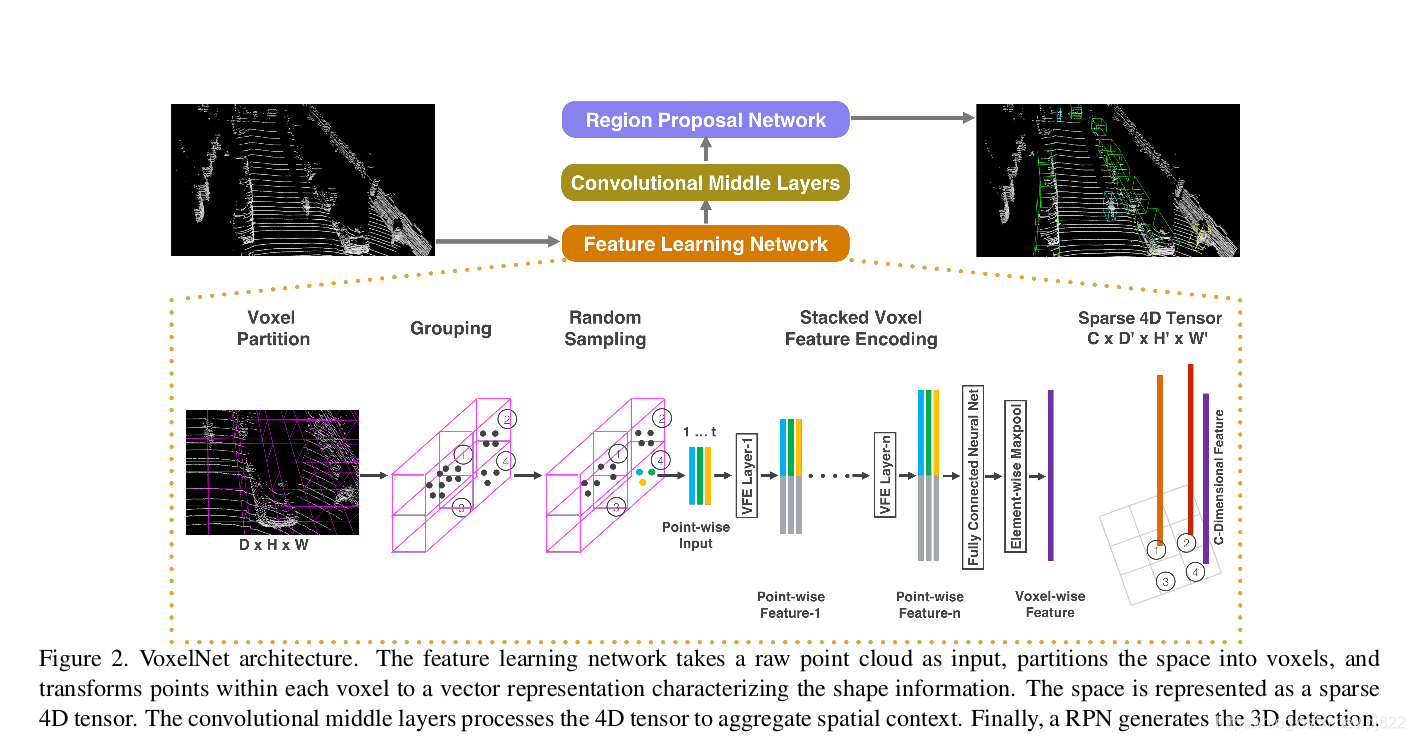
特征学习网络
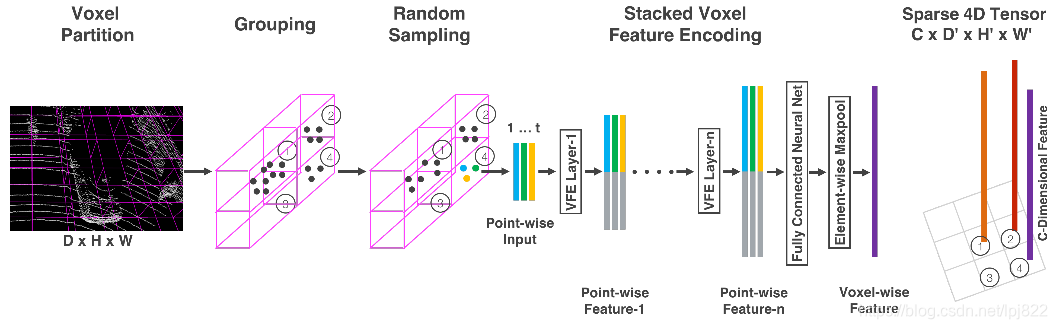
特征学习网络的结构如下图所示,包括体素分块(Voxel Partition),点云分组(Grouping),随机采样(Random Sampling),多层的体素特征编码(Stacked Voxel Feature Encoding),稀疏张量表示(Sparse Tensor Representation)等步骤,具体来说:
-
体素分块
这是点云操作里最常见的处理,对于输入点云,使用相同尺寸的立方体对其进行划分,我们使用一个深度、高度和宽度分别为 (D,H,W)的大立方体表示输入点云,每个体素的深高宽为 ( d D , d H , d W ) ({d_D},{d_H},{d_W}) (dD,dH,dW),则整个数据的三维体素化的结果在各个坐标上生成的体素格(voxel grid)的个数为: ( D d D , H d H , W d W ) (\frac{D}{d_D},\frac{H}{d_H},\frac{W}{d_W}) (dDD,dHH,dWW) -
点云分组
将点云按照上一步分出来的体素格进行分组 -
随机采样
很显然,按照这种方法分组出来的单元会存在有些体素格点很多,有些格子点很少的情况,64线的激光雷达一次扫描包含差不多10万个点,直接处理所有的点不仅增加了计算平台上的内存/效率负担,而且在整个空间中高度可变的点密度可能会偏置检测。为此,我们随机地从包含多于T点的体素随机采样固定点T。该采样策略有两个目的:- 计算节省
- 减少体素之间的点的不平衡,减少采样偏倚,并且增加训练的变化。
-
多个体素特征编码(Voxel Feature Encoding,VFE)层
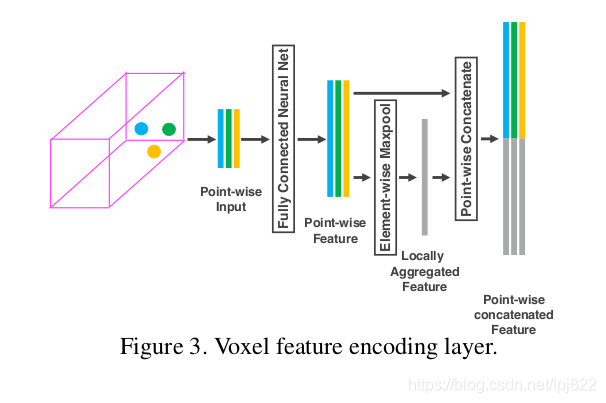
之后是多个体素特征编码层,简称为VFE层,这是特征学习的主要网络结构,以第一个VFE层为例说明:
- 对于输入:
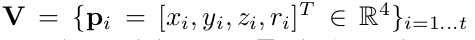
是一个体素格内随机采样的点集,t<=T, ( x i , y i , z i , r i ) ({x_i},{y_i},{z_i},{r_i}) (xi,yi,zi,ri)分别点的XYZ坐标以及激光束的反射强度(即intensity),我们首先计算体素内所有点的平均值 ( v x , v y , v z , ) ({v_x},{v_y},{v_z},) (vx,vy,vz,)作为体素格的形心(类似于Voxel Grid Filter),那么我们就可以将体素格内所有点的特征数量扩充为如下形式:
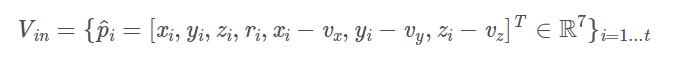
- 接着,每一个 p i ^ \hat{p_i} pi^都会通过一个全连接网络(Fully Connected,FC)被映射到一个特征空间 ,输入的特征维度为7,输出的特征维数变成m,全连接层包含了一个线性映射层,一个批标准化(Batch Normalization),以及一个非线性运算(ReLU),得到逐点的(point-wise)的特征表示。
- 接着我们采用最大池化(MaxPooling)对上一步得到的特征表示进行逐元素的聚合,这一池化操作是对元素和元素之间进行的,得到局部聚合特征(Locally Aggregated Feature,最后,将逐点特征和逐元素特征进行连接(concatenate),得到输出的特征集合:
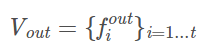
- 对于所有的非空的体素格我们都进行上述操作,并且它们都共享全连接层(FC)的参数。我们使用符号 ( c i n , c o u t ) ({c_{in}},{c_{out}}) (cin,cout) 来描述经过VFE以后特征的维数变化,那么显然全连接层的参数矩阵大小为: ( c i n , c o u t 2 ) ({c_{in}}, \frac{c_{out}}{2}) (cin,2cout)
- 由于VFE层中包含了逐点特征和逐元素特征的连接,经过多层VFE以后,我们希望网络可以自动学习到每个体素内的特征表示
- 通过对体素格内所有点进行最大池化,得到一个体素格内特征表示C

- 对于输入:
-
稀疏张量表示
通过上述流程处理非空体素格,我们可以得到一系列的体素特征(Voxel Feature)。这一系列的体素特征可以使用一个4维的稀疏张量来表示: C × D ∗ × H ∗ × W ∗ C\times{D^*}\times{H^*}\times{W^*} C×D∗×H∗×W∗。对于沿着Lidar坐标系(Z, X, Y)的[-3, 1], [-40, 40],[0,70.4]米这个感兴趣区域,取体素格的大小为 d D = 0.4 , d H = 0.2 , d W = 0.2 {d_D}=0.4,{d_H}=0.2,{d_W}=0.2 dD=0.4,dH=0.2,dW=0.2,那么有 D ∗ = 10 , H ∗ = 400 , W ∗ = 352 {D^*}=10, {H^*}=400,{W^*}=352 D∗=10,H∗=400,W∗=352,我们设置随机采样的T=35,并且采用两个VFE层:VFE-1(7, 32) 和 VFE-2(32, 128),最后,特征学习网络的输出即为一个尺寸为 128 × 10 × 400 × 352 128\times10\times400\times352 128×10×400×352。
卷积中间层
使用3D卷积对4D tensor进行卷积,并进行reshape到3D tensor,举例:输入尺寸(4D tensor)是
128
×
10
×
400
×
352
128\times10\times400\times352
128×10×400×352 ,输出尺寸(经过Convolutional Middle Layers之后)是
64
×
2
×
400
×
352
64\times2\times400\times352
64×2×400×352 ,然后reshape到
128
×
400
×
352
128\times400\times352
128×400×352变成3D tensor(注意到
128
×
400
×
352
128\times400\times352
128×400×352 正是BEV视图上的栅格尺寸)。
目的:
- reshape的目的是方便后续的Region Proposal Network进行2D卷积
- 3D卷积的目的是聚合周围环境voxels的信息
区域提出网络(RPN)
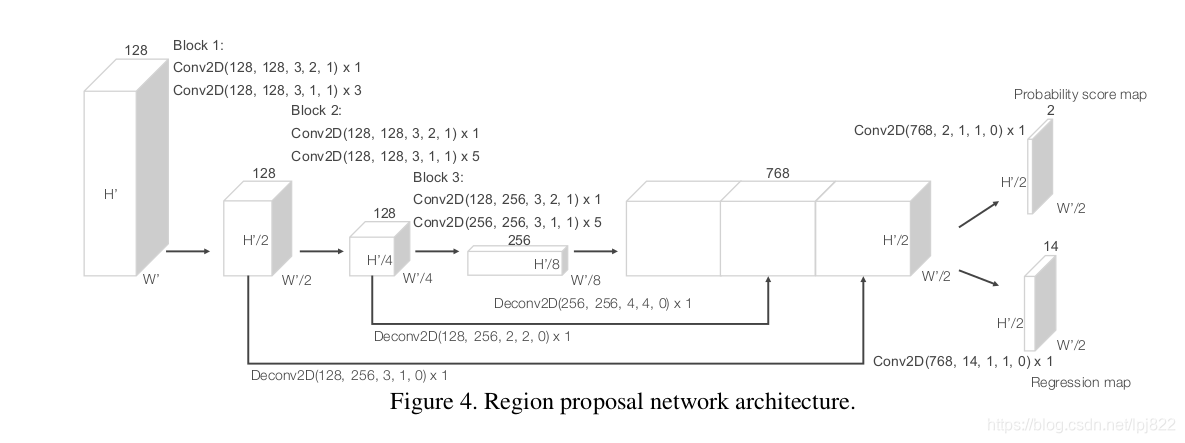
如图所示,该网络包含三个全卷积层块(Block),每个块的第一层通过步长为2的卷积将特征图采样为一半,之后是三个步长为1的卷积层,每个卷积层都包含BN层和ReLU操作。将每一个块的输出都上采样到一个固定的尺寸并串联构造高分辨率的特征图。最后,该特征图通过两种二维卷积被输出到期望的学习目标:
- 概率评分图(Probability Score Map )
- 回归图(Regression Map)
loss
- 回归量是
(
Δ
x
,
Δ
y
,
Δ
z
,
Δ
l
,
Δ
w
,
Δ
h
,
Δ
θ
)
(\Delta{x},\Delta{y},\Delta{z},\Delta{l},\Delta{w},\Delta{h},\Delta{\theta})
(Δx,Δy,Δz,Δl,Δw,Δh,Δθ),计算如下:
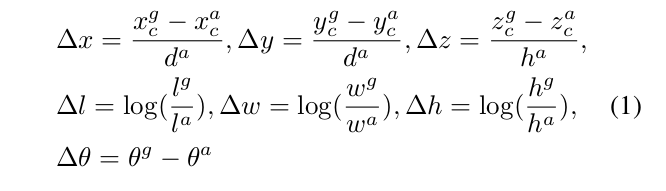
其中:
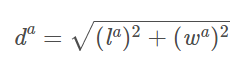
- 这里使用
(
x
c
g
,
y
c
g
,
z
c
g
,
l
g
,
w
g
,
h
g
,
θ
g
)
({x}^g_c,{y}^g_c,{z}^g_c,{l}^g,{w}^g,{h}^g, {\theta}^g)
(xcg,ycg,zcg,lg,wg,hg,θg)来表示一个真实的3D标注框,其中
(
x
c
g
,
y
c
g
,
z
c
g
)
({x}^g_c,{y}^g_c,{z}^g_c)
(xcg,ycg,zcg) 表示标注框中心的坐标,
(
l
g
,
w
g
,
h
g
)
({l}^g,{w}^g,{h}^g)
(lg,wg,hg)表示标注框的长宽高,
θ
g
{\theta}^g
θg表示偏航角(yaw)。相应的,
(
x
c
a
,
y
c
a
,
z
c
a
,
l
a
,
w
a
,
h
a
,
θ
a
)
({x}^a_c,{y}^a_c,{z}^a_c,{l}^a,{w}^a,{h}^a, {\theta}^a)
(xca,yca,zca,la,wa,ha,θa)) 表示正样本框。
定义损失函数为:
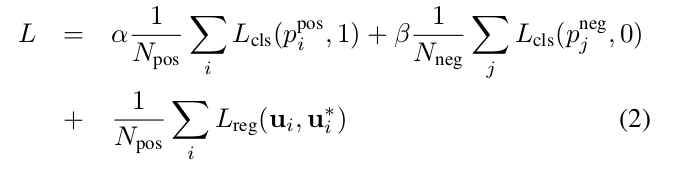
其中 p i p o s p^{pos}_i pipos和 p i n e g p^{neg}_i pineg分别表示正样本 a i p o s a^{pos}_i aipos 和负样本 a i n e g a^{neg}_i aineg 的Softmax输出, u i , u i ∗ u_i,u^*_i ui,ui∗分别表示神经网络的正样本输出的标注框和真实标注框。损失函数的前两项表示对于正样本输出和负样本输出的分类损失(已经进行了正规化), 其中, { a i p o s } i = 1... N p o s \{a^{pos}_i\}_{i=1...N_{pos}} {aipos}i=1...Npos为正样本集合, { a j n e g } j = 1... N n e g \{a^{neg}_j\}_{j=1...N_{neg}} {ajneg}j=1...Nneg为负样本集合, L c l s L_{cls} Lcls表示交叉熵, α \alpha α和 β \beta β是两个常数,它们作为权重来平衡正负样本损失对于最后的损失函数的影响。 L r e g L_{reg} Lreg表示回归损失,这里采用的是Smooth L1函数。

















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









