







作者:Dreamweaver,SJTU × AIGC/LLM,腾讯公司 · 多模态应用研究 (实习)
声明:本文只做分享,版权归原作者,侵权私信删除!
原文:https://zhuanlan.zhihu.com/p/706145455
我们会发现,最新流行的MLLM架构大多采用类LLaVA的ViT+MLP+LLM范式。得益于LLaVA的精简设计、数据和训练高效性、更强的baseline性能,LLaVA架构建立起了良好的应用生态。国内也涌现出了高质量的MLLM,InternVL拉近了开源模型与GPT-4V的差距,具备4K高分辨率处理能力,而MiniCPM-V实现了高效端侧部署,让小模型也能抗衡顶尖的闭源模型。最新的Cambrian-1则是鼓励研究者跳出当前MLLM的思维定式,不断探索视觉表征更多的可能性。通往AGI有多条路径,而原生的多模态大模型则是必经之路。
本文重点介绍LLaVA-NeXT、InternVL、MiniCPM-V系列,以及以视觉为中心的Cambrian-1,简单介绍VILA1.5和CogVLM2。截止2024.06,持续更新ing... 干货很多,欢迎大家多多点赞、收藏、讨论!
LLaVA-NeXT系列
LLaVA-1.5
23年10月,LLaVA-1.5发布,通过在视觉和语言模态间添加简单的MLP层实现了训练样本高效性,为多模态大模型在低数据业务场景的落地提供了可能。
[2310.03744] Improved Baselines with Visual Instruction Tuning[1]
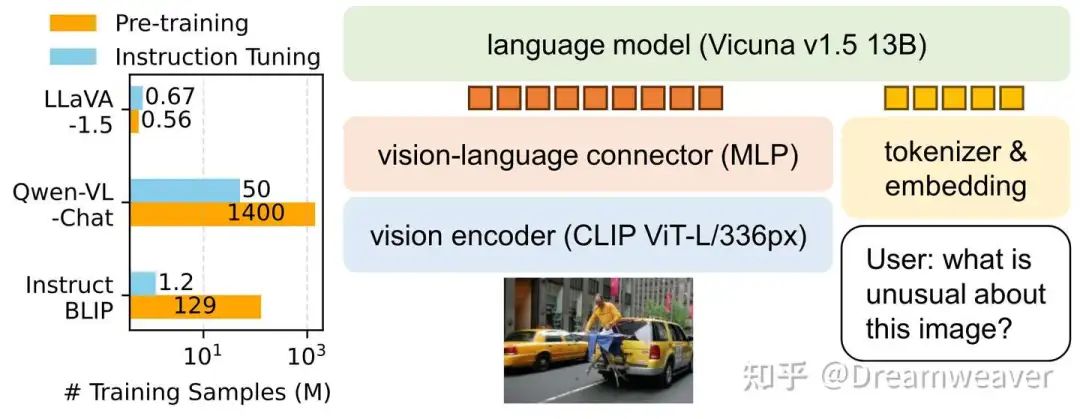
LLaVA-NeXT
24年1月,LLaVA-NeXT(1.6)发布,在1.5的基础上保持了精简的设计和数据高效性,支持更高的分辨率、更强的视觉推理和OCR能力、更广泛场景的视觉对话。模型分为两阶段训练:阶段1预训练只训练连接层,阶段2指令微调训练整个模型。
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge[2]
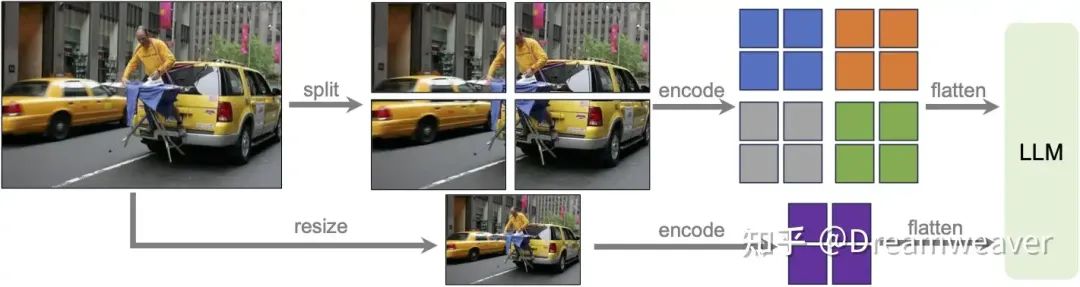
-
• 动态高分辨率AnyRes:如上图,为了让模型能感知高分辨率图像的复杂细节,对图像进行网格划分。比如,对于672x672的图像,一方面按2x2的网格切分为4张336px的输入图像送给ViT编码成特征,另一方面将图像直接resize到336px进行编码,最后将两部分特征合并输入到LLM中,这样模型具备了全局和局部的视觉推理能力。
-
• 指令数据混合:一方面保证指令数据具有高质量、多样性,反映真实场景的广泛用户意图;另一方面,补充文档和表格数据,提升模型的OCR和图表理解能力。
-
• 扩大LLM尺寸:考虑了7B、13B、34B的LLM。
24年5月,团队发布基于更强LLM的LLaVA-NeXT版本,支持LLaMA3(8B)和Qwen1.5(72B/110B)。更大的LLM提供更好的视觉世界知识和逻辑推理能力,最大的模型接近GPT-4V的性能,同时保证了训练高效性。
LLaVA-NeXT: Stronger LLMs Supercharge Multimodal Capabilities in the Wild[3]
LLaVA-NeXT-Video
24年4月,LLaVA-NeXT-Video发布,展现出强大的zero-shot视频理解能力。LLaVA-NeXT中的高分辨率图像动态划分可以很自然地迁移到视频模态用来表示视频的多帧,使得只在图文模态上训练的LLaVA-NeXT能在视频任务上泛化。此外,推理时的长度泛化用于有效处理超出LLM最大长度的长视频输入。基于LLaVA-NeXT-Image模型,作者发布了在视频数据上监督微调的LLaVA-NeXT-Video,以及在AI反馈的监督下使用DPO偏好对齐的LLaVA-NeXT-Video-DPO。使用SGLang部署和推理,支持可扩展的大规模视频推理。可以想到,这有助于海量视频的高效文本标注,催生了未来更强大视频生成模型。
LLaVA-NeXT: A Strong Zero-shot Video Understanding Model[4]

-
• AnyRes:可以将N帧视频看作{1xN}的网格,而LLM的最大长度限制了可以处理的帧数,很自然地会考虑对图像进行下采样减少每帧token数,但作者发现为保证效果仍只能处理16帧。
-
• 长度泛化:基于LLM的长度外推技术(RoPE的线性扩展),推理时扩展2倍,从之前的16帧扩展到56帧,大大提升了模型分析长视频序列的能力。
-
• 基于LLM反馈的DPO偏好优化:偏好数据由LLM生成,视频表示为详细的说明文字,带来了很大的性能增益。
-
• 对于视频数据的微调,作者进行了ablation study:(1) 在LLaVA-NeXT图像级指令微调后,继续在视频级指令上增量微调;(2) 在LLaVA-NeXT图像级预训练后,在图像级和视频级数据联合微调,每个batch数据包含一种类型或
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











