




一、 模型结构方面
依然是使用的标准的、密集型的Transformer架构,和Llama2相比没什么滑头。一些细微的修改:
-
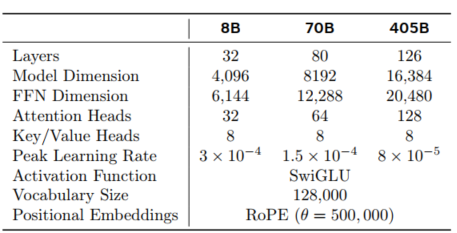
使用了GQA的attention,带8个key-value头来减少K-V cache的decoding负担。
-
使用attention mask来替代self-attention, 当两份不同的文档含有相同的文本序列时,对持续的训练长文本比较有效,且副作用小。
-
词汇表是128k tokens:100k token 来自tiktoken的分词器,28k额外的token来自其他非英语系语言。
-
增加了ROPE位置编码的基础频率超参数至500000. 这也增强了长上下文的理解能力。
二、 训练的基础架构
计算:405B模型版本在16K H100 GPUs上,700w TDP,80G HBM3,使用了Meta’s Grand Teton AI 服务器平台。每台服务8块GPUs带2个CPU。8卡GPU 通过NVlink互联。
存储:240PB 存储,7500台带SSD的服务器,2 TB/s吞吐,峰值为7TB/s。挑战点在于模型中间状态的checkpoint文件的存储,以及故障恢复和debug。
网络:405B模型使用RDMA over RoCE。小版本的模型基于Nvidia Quantum2 Infiniband fabric来训练。无论是RoCE还是Infiniband集群都保证了GPU之间的互连速率达到400Gbps。
模型扩展的并行策略
为了尽可能训练最大的模型,使用了_4D_并行技术:TP、PP、DP、CP
(CP: context parallelism)
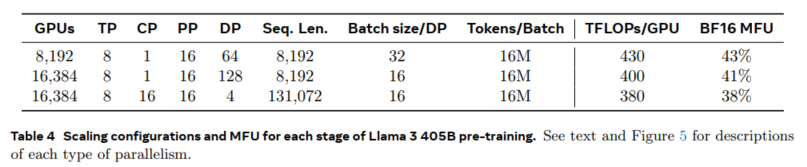
张量并行将各个权重张量分割成不同设备上的多个块。管道并行将模型垂直分层划分,使得不同的设备在完整模型管道的各个阶段可以并行处理不同的数据。上下文并行将输入的上下文分为多个段,减少长序列长度输入对内存的瓶颈。
使用了FSDP技术:fully sharded data parallelism技术将模型优化器、梯度计算结果和数据并行分布到多个GPU。
GPU utilization: 基于上表的配置,可以看到MFU在38%~43%之间。
PP过程中遇到的挑战:
Batch size限制:当前的实现对每个 GPU 支持的批次大小有限制,要求它能被管道级数整除。对于图 6 中的示例,深度优先管道并行性的调度(DFS)(Narayanan et al., 2021)要求 N = PP = 4,而广度优先调度(B
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 953
953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









