






小波降噪CEEMDAN+LSTM+FECAM+NTSformer时间序列代码应用于时间序列预测、金融数据分析、气象预测、异常检测等领域,特别是在数据表现出明显的非平稳性时,能够显著提升模型性能。做创新点非常够用。
1.小波降噪CEEMDAN
CEEMDAN(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise)是一种信号分解技术,用于处理非线性和非平稳时间序列数据。它是EMD(Empirical Mode Decomposition)的改进版本,具备更好的分解性能和鲁棒性。以下是CEEMDAN的主要特点和步骤:
主要特点
-
适应性:CEEMDAN能够适应复杂信号的特征,特别是非线性和非平稳的时间序列,提供更为准确的信号分解。
-
噪声增强:通过引入自适应噪声,CEEMDAN增强了分解过程中的鲁棒性,减少了模式混叠(mode mixing)的现象。
-
多重分解:CEEMDAN可以将时间序列分解为多个本征模式函数(IMF),这些IMF代表信号的不同频率成分,使得对信号的分析和处理更为灵活。
CEEMDAN的步骤
-
生成噪声:为原始信号添加多个白噪声序列,通常为多次重复,以增强信号的分解效果。
-
进行EMD分解:对每个带噪声的信号进行EMD分解,得到多个IMF和一个残余信号。
-
整合结果:将不同噪声序列的分解结果整合起来,去除噪声影响,从而获得更清晰、更稳定的IMF。
-
自适应调整:通过自适应调整噪声的强度,以提高分解质量。
小波降噪是一种利用小波变换的技术,旨在从含噪声的信号中提取出清晰的信号。它通过分析信号在不同频率和时间尺度上的特征,能有效去除高频噪声而保留重要的信号成分。以下是小波降噪的主要步骤和优点:
主要步骤
-
小波变换:
- 将原始信号通过小波变换分解为多个频率子带。常用的变换包括离散小波变换(DWT)和连续小波变换(CWT)。
- 在小波域中,信号被分解为不同的分量,通常包括低频部分(信号的主要特征)和高频部分(噪声)。
-
阈值处理:
- 针对高频系数,应用阈值法进行处理。常用的方法有硬阈值和软阈值:
- 硬阈值:将低于某一阈值的系数置为零,保留大于该阈值的系数。
- 软阈值:在硬阈值的基础上,减少大于阈值的系数的绝对值。
- 针对高频系数,应用阈值法进行处理。常用的方法有硬阈值和软阈值:
-
小波逆变换:
- 将经过阈值处理后的系数进行小波逆变换,重构出降噪后的信号。
优点
-
时频局部化:小波变换能在时间和频率上同时分析信号,有助于捕捉信号中的瞬时特征和变化。
-
多分辨率分析:小波降噪可以处理不同频率成分的噪声,使得降噪效果更加精确。
-
灵活性:根据不同信号特性,可以选择不同的小波基和阈值策略,具有较强的适应性。
-
保留信号特征:小波降噪在去除噪声的同时,能够较好地保留信号的主要特征,避免信号失真。
将小波降噪和CEEMDAN(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise)结合使用,可以充分发挥两者的优势,从而提升时间序列预测的效果。
1. 噪声抑制效果增强
- 小波降噪:能够有效去除高频噪声,保留重要信号特征。
- CEEMDAN:通过添加自适应噪声来增强信号分解的鲁棒性,进一步减少模式混叠现象。
- 结合优势:两者结合能够在不同频率范围内更全面地抑制噪声,提高信号的整体质量。
2. 多层次信号分析
- 小波变换:提供多分辨率分析,能同时捕捉信号的细节和整体趋势。
- CEEMDAN:将信号分解为多个本征模式函数(IMF),这些IMF可以代表信号的不同频率成分。
- 结合优势:这种结合可以从多个角度分析信号,增强对复杂模式的理解。
3. 提高特征提取能力
- 小波降噪:通过去除噪声,提升后续模型的输入质量。
- CEEMDAN:提取出清晰的IMF,便于进一步分析和建模。
- 结合优势:清晰的IMF和去噪后的信号特征结合,可以提高机器学习模型(如LSTM、NTSformer等)的学习效率和预测准确性。
4. 增强模型的鲁棒性
- 小波降噪:减少异常值的影响,提升信号的稳定性。
- CEEMDAN:通过自适应噪声和分解,增强对非平稳信号的适应性。
- 结合优势:这种增强可以使得模型在面对实际数据时更具鲁棒性,减少过拟合的风险。
2.LSTM
LSTM(Long Short-Term Memory,长短期记忆网络)是一种特殊的递归神经网络(RNN),设计用于解决标准RNN在处理长序列时的梯度消失和梯度爆炸问题。LSTM通过引入记忆单元和门控机制,可以在长时间跨度内保持和更新关键信息,从而在许多序列数据任务中表现出色。
LSTM的结构
LSTM的基本单元包括以下三个主要组件:
-
细胞状态(Cell State):
- 细胞状态是LSTM的核心部分,贯穿整个序列的数据流。它相当于一个直通通道,允许信息以最少的修改通过时间步长传播。细胞状态通过加法和乘法操作来控制信息的传递和遗忘,避免了梯度消失问题。
-
门控机制(Gates): LSTM通过三个门控来调节信息的流动:
- 遗忘门(Forget Gate):决定细胞状态中哪些信息需要被遗忘。它接受前一时间步长的隐藏状态和当前输入,通过一个Sigmoid激活函数输出一个0到1之间的值,控制信息是否被丢弃。
- 输入门(Input Gate):决定当前时间步长的新信息对细胞状态的更新程度。输入门与当前输入和前一隐藏状态结合,通过Sigmoid激活函数输出控制信号。
- 输出门(Output Gate):决定细胞状态中的哪些部分将作为隐藏状态输出,并传递到下一时间步长。输出门通过Sigmoid激活函数,结合当前输入和前一隐藏状态,生成下一步的隐藏状态。
-
隐藏状态(Hidden State):
- 隐藏状态是LSTM输出的主要内容,也是传递到下一个时间步长的信息。它包含了LSTM单元对当前时间步长输入和细胞状态的理解。

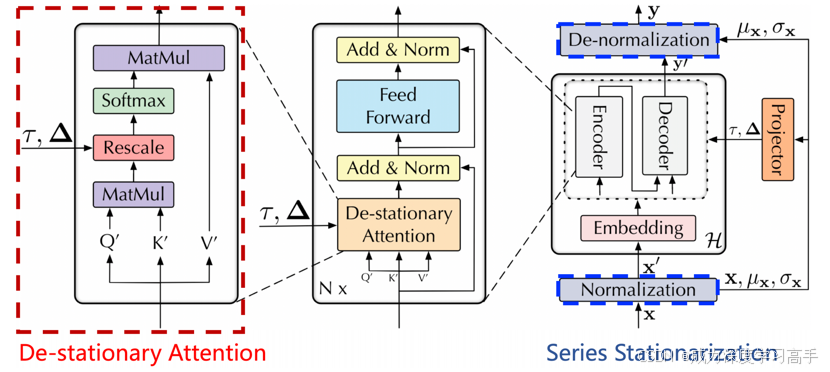
3.Non-stationary Transformers
Non-stationary Transformers是清华大学2022年提出的改进transformer的模型。一种针对非平稳时间序列数据设计的变换模型。传统的变换模型通常假设输入数据是平稳的,但在许多实际应用中,时间序列数据往往表现出趋势变化、季节性波动和其他动态特征,因此需要特别的处理。以下是Non-stationary Transformers的主要特点和构成:
主要特点
-
适应非平稳性:
- 通过动态调整模型参数和结构,使其能够捕捉时间序列中的非平稳性,例如趋势和季节性。
-
时域和频域特征结合:
- Non-stationary Transformers通常将时域和频域特征结合起来,通过自注意力机制增强对重要模式的关注。
-
动态位置编码:
- 采用动态位置编码方法,能够有效表示时间序列的时间特征,尤其是在非均匀时间间隔的情况下。
-
多尺度处理:
- 结合多尺度特征提取技术,能够在不同时间尺度上分析信号,捕捉短期和长期的变化。
构成组件
-
自注意力机制:
- 允许模型关注输入序列中不同位置之间的关系,从而提高对关键模式的捕捉能力。
-
位置编码:
- 针对非平稳序列,位置编码会根据数据的动态特征进行调整,增强对时间序列中重要时刻的识别。
-
卷积和池化层:
- 常与传统的卷积神经网络(CNN)相结合,提取局部特征并降低数据维度。
-
层次化架构:
- 在模型中引入层次化结构,使得模型可以在不同层次上学习到不同的特征和模式。
4.实验
数据集都可以,只要是时间序列格式,不限领域,类似功率预测,风电光伏预测,负荷预测,流量预测,浓度预测,机械领域预测等等各种时间序列直接预测。可以做验证模型,对比模型。格式类似顶刊ETTH的时间序列格式即可。
比如这里是时间列+7列影响特征+1列预测特征

5.源码地址及代码讲解
https://www.bilibili.com/video/BV1Cg15YaEKw/?spm_id_from=333.999.0.0

















 279
279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









