







Spike Timing Dependent Plasticity
脉冲时序依赖可塑性是Hebb学习的时间不对称形式,由突触前后神经元脉冲紧密的时间相关性引导的。和其他形式的突触可塑性一样,人们普遍认为它是大脑中学习和信息存储的基础,以及在大脑发育期间神经元回路的发展与完善。使用STDP,在突触后动作电位之前几毫秒反复的突触前脉冲的到达导致了许多突触成为LTP突触类型,相反,在突触后脉冲之后的重复的脉冲的到达导致同样的突触变为LTD类型。以突触前后动作电位的的时间相关函数标定的突触的变化称为STDP函数或突触类型的学习窗和变化。带有脉冲相关时序性质的STDP函数的快速变化表明在毫秒尺度上进行时间编码方案的可能。
写在前面
在典型的STDP实验中,突触是通过注射短电流脉冲使突触后神经元发射脉冲不久之前或之后,刺激突触前神经元来激活的。这样的配对按照固定的频率重复50-100次。突触的权重是以突触后神经元电势的幅值来衡量的。突触权重的变化由突触前脉冲的到达和突触后的激发的相对时序的函数来表示。值得注意的是,不同的突触具有不同形式的STDP函数。和其他突触可塑性相比,STDP特别具有吸引力因为它被认为是生物可解释的。在生物的大脑中,动作电位经常非常精确地定时于外界的刺激,尽管并不是所有的脑区和细胞类型都是如此。
经典STDP模型
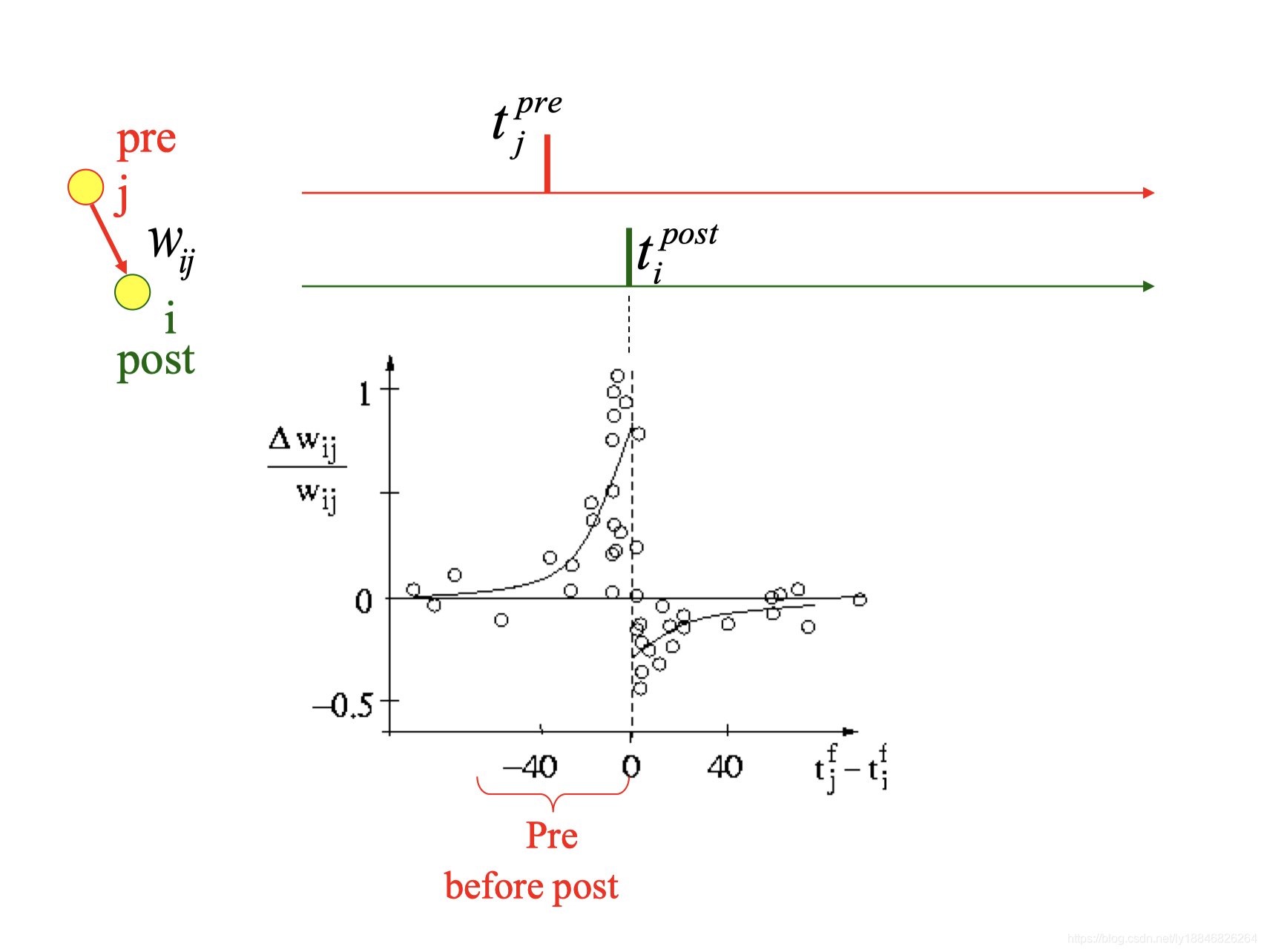
来自突触前神经元
j
j
j的突触权重变化
Δ
ω
\Delta \omega
Δω依赖于突触前脉冲的到达和突触后脉冲的相对时序。突触
j
j
j的突触前脉冲的到达时刻
t
j
f
t_j^f
tjf,
f
=
1
,
2
,
3
,
.
.
.
f=1,2,3,...
f=1,2,3,...计数了突触前神经元的脉冲。同样的
t
i
n
t_i^n
tin表示突触后神经元的脉冲时间。在成对的突触前后脉冲上按照刺激规则,总权重变化
Δ
ω
j
\Delta \omega_j
Δωj是
Δ
ω
j
=
∑
f
=
1
N
∑
n
=
1
N
W
(
t
i
n
−
t
j
f
)
\Delta \omega_{j}=\sum_{f=1}^{N} \sum_{n=1}^{N} W\left(t_{i}^{n}-t_{j}^{f}\right)
Δωj=f=1∑Nn=1∑NW(tin−tjf)
W表示STDP函数,常用的STDP函数W的一个选择是
W
(
x
)
=
A
+
exp
(
−
x
/
τ
+
)
for
x
>
0
W
(
x
)
=
−
A
−
exp
(
x
/
τ
−
)
for
x
<
0
\begin{array}{lll} W(x)=A_{+} \exp \left(-x / \tau_{+}\right) & \text {for } x>0 \\ W(x)=-A_{-} \exp \left(x / \tau_{-}\right) & \text {for } x<0 \end{array}
W(x)=A+exp(−x/τ+)W(x)=−A−exp(x/τ−)for x>0for x<0
A
+
,
A
−
A_+,A_-
A+,A−取决于突触的当前值。时间常数取
10
m
s
10ms
10ms。
STDP的各种变体
1、online-STDP
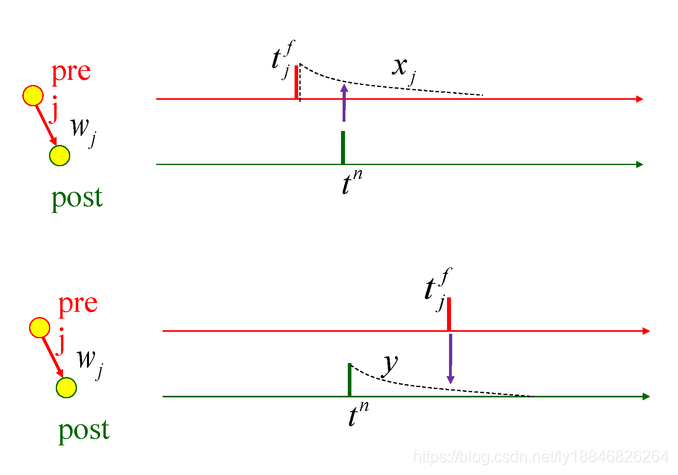
上式中的STDP函数可以通过使用以下假设按在线更新的规则实现。每个突触前脉冲的到达都会留下轨迹 x j ( t ) x_j(t) xj(t),这条轨迹在脉冲到达时为 a + ( x j ) a_+(x_j) a+(xj),在没有脉冲时按指数衰减。变量y为突触后脉冲时刻到达峰值 a − ( y ) a_-(y) a−(y)。轨迹可能的解释是正在反向传播的动作电位引起的突触的电压,或者是反向传播的动作电位引起的钙进入。
τ
+
d
x
j
d
t
=
−
x
+
a
+
(
x
)
∑
j
δ
(
t
−
t
j
f
)
τ
−
d
y
d
t
=
−
y
+
a
−
(
y
)
∑
n
δ
(
t
−
t
n
)
\tau_{+} \frac{d x_{j}}{d t}=-x+a_{+}(x) \sum_{j} \delta\left(t-t_{j}^{f}\right)\\ \tau_{-} \frac{d y}{d t}=-y+a_{-}(y) \sum_{n} \delta\left(t-t^{n}\right)
τ+dtdxj=−x+a+(x)j∑δ(t−tjf)τ−dtdy=−y+a−(y)n∑δ(t−tn)
然后权重的变化是
d
w
j
d
t
=
A
+
(
w
j
)
x
(
t
)
∑
n
δ
(
t
−
t
n
)
−
A
−
(
w
j
)
y
(
t
)
∑
f
δ
(
t
−
t
j
f
)
\frac{d w_{j}}{d t}=A_{+}\left(w_{j}\right) x(t) \sum_{n} \delta\left(t-t^{n}\right)-A_{-}\left(w_{j}\right) y(t) \sum_{f} \delta\left(t-t_{j}^{f}\right)
dtdwj=A+(wj)x(t)n∑δ(t−tn)−A−(wj)y(t)f∑δ(t−tjf)
因此,在突触后发射脉冲时权重增加,这个量取决于突触前脉冲留下的轨迹。同样的,权重在突触前脉冲时减少,这个量取决于先前突触后脉冲留下的轨迹。
该方法与经典的STDP在更新上略有区别,经典的STDP每当脉冲到来时计算其影响,online方式通过使用迹的方式,将脉冲到来看作是一个开关,之前的脉冲的影响全在迹中保存。
2、依赖权重的硬边界与软边界
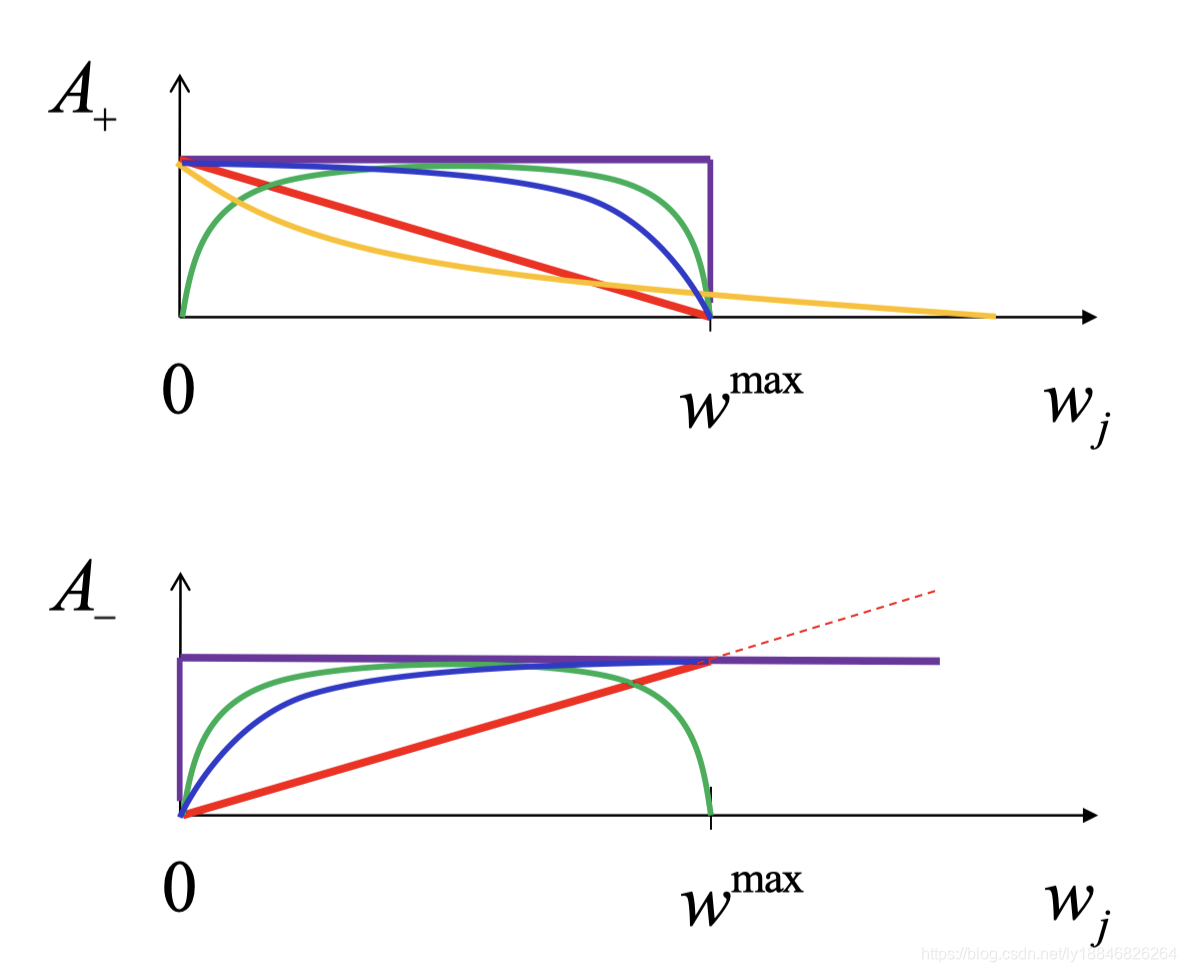
由于生物原因,最好将突触权重保持在一个范围内:
ω
min
<
ω
j
<
ω
max
\omega^{\min }<\omega_{j}<\omega^{\max }
ωmin<ωj<ωmax
通过适当的选择函数
A
+
(
ω
j
)
A_+(\omega_j)
A+(ωj)和
A
−
(
ω
j
)
A_-(\omega_j)
A−(ωj)可以实现上述目标。即软边界如下
A
+
(
w
j
)
=
(
w
max
−
w
j
)
η
+
A
−
(
w
j
)
=
(
w
j
−
w
min
)
η
−
A_{+}\left(w_{j}\right)=\left(w^{\max }-w_{j}\right) \eta_{+}\\ A_{-}\left(w_{j}\right)=\left(w_{j}-w^{\min}\right) \eta_{-}
A+(wj)=(wmax−wj)η+A−(wj)=(wj−wmin)η−
另外还有选择被称为硬边界:
A
+
(
w
j
)
=
Θ
(
w
m
a
x
−
w
j
)
η
+
A
−
(
w
j
)
=
Θ
(
w
j
−
w
min
)
η
−
A_{+}\left(w_{j}\right)=\Theta\left(w^{m a x}-w_{j}\right) \eta_{+}\\ A_{-}\left(w_{j}\right)=\Theta\left(w_{j}-w^{\min}\right) \eta_{-}
A+(wj)=Θ(wmax−wj)η+A−(wj)=Θ(wj−wmin)η−
这里的
Θ
(
x
)
\Theta(x)
Θ(x)表示Heaviside阶跃函数。
在实际中,硬边界意味着按照固定参数 η + , η − \eta_+,\eta_- η+,η−更新规则,直到到达边界为止;软边界意味着,对于大权重,突触的抑制大于增强;对于小权重,突触的增强大于抑制。
3、all-to-all & Nearest Neighbor
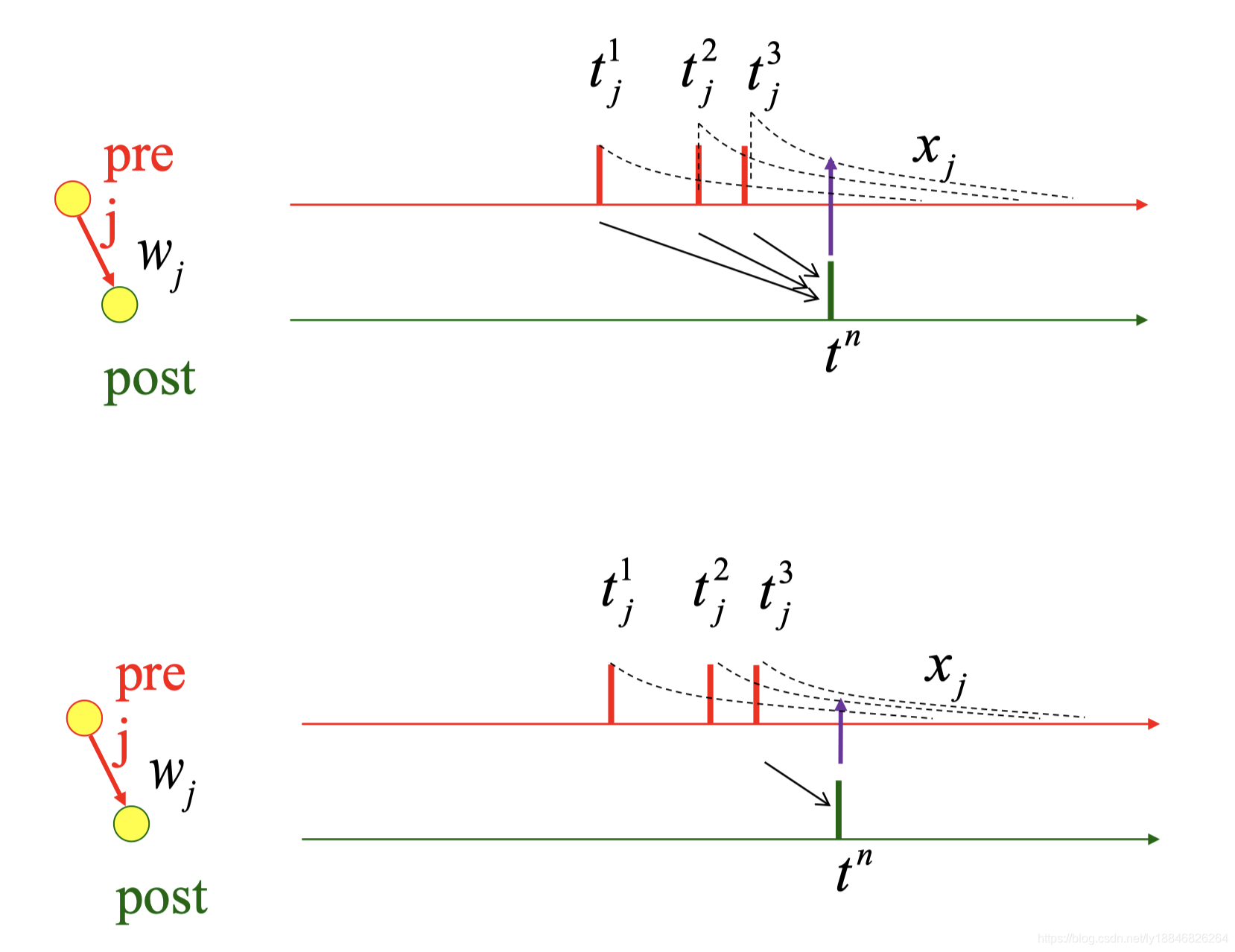
一般STDP模型的窗函数W的和遍历了所有的突触前脉冲和所有的突触后脉冲,所有的脉冲对的贡献相等,这样的情况被称为all-to-all。
也有可能限制相互作用因此只有最近邻的脉冲作用。突触后脉冲的增强也可能仅依赖于最近的突触前脉冲时间。为了实现这一点,假设轨迹变量x在突触前脉冲的时刻增加到一定量 a + ( x ) = 1 − x − a_{+}(x)=1-x_{-} a+(x)=1−x−, x − x_- x−表示更新前变量x的值。换句话说,x的更新不是积累的,而是总是固定的值1,因此以前脉冲的影响将被忽略。
当然也可以考虑加一个时间窗,或者使用k近邻。
4、Triplet-STDP
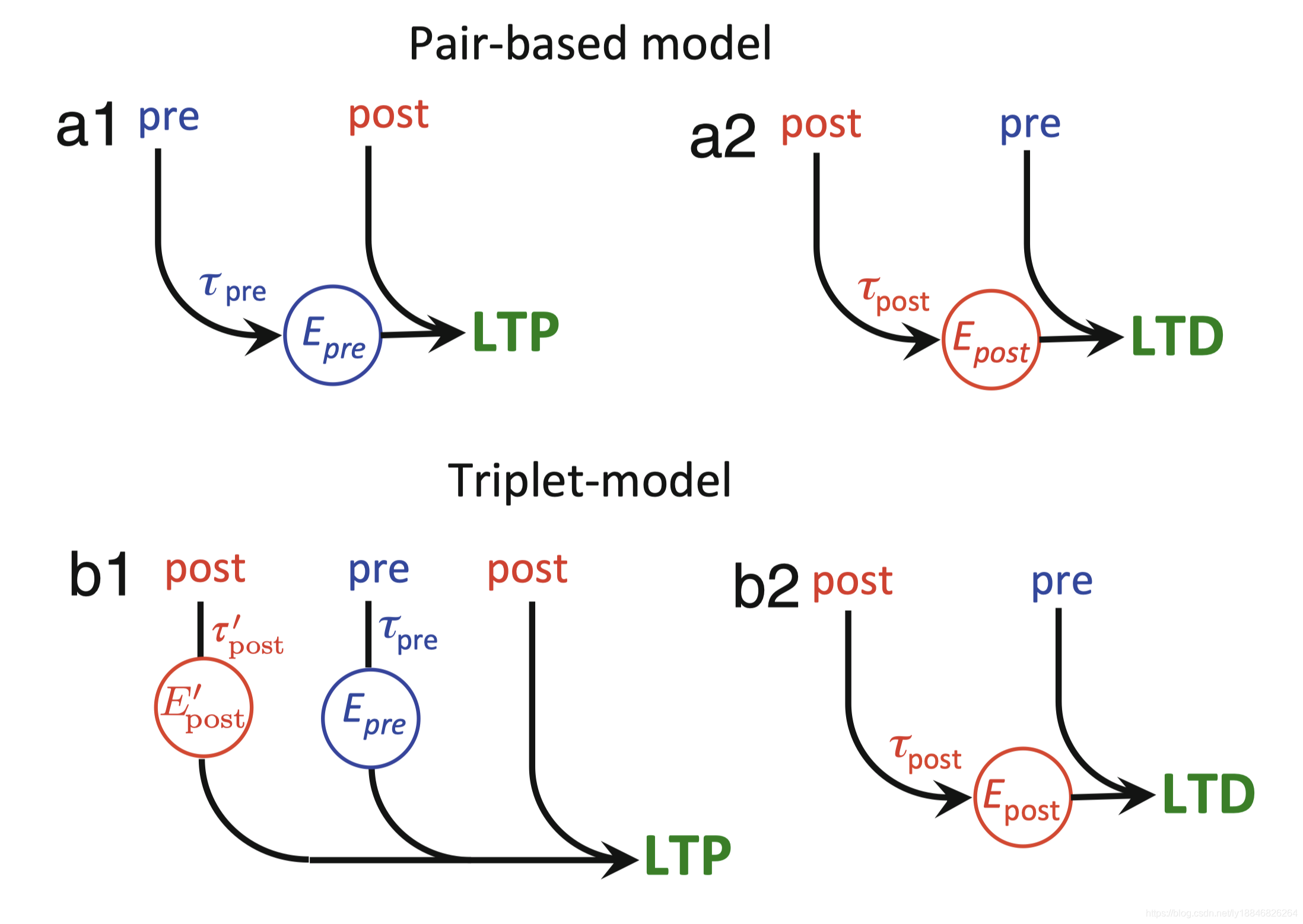
如果假设STDP实验中的基本的增强不是成对的相互作用,而是两个突触后脉冲和一个突触前脉冲的三重态相互作用,那么STDP实验中的频率依赖性就可以被解释。如果其中一个与两个突触后轨迹与y1和y2按两个不同的时间常数一起工作,而不是单一的轨迹,这样的三重态相互作用可以在模型中实现。这样的模型也与三重态实验兼容,但是基于成对的模型是不行的。
5、自平衡项
除了上面提到的基于paired和triplet-STDP外,人们还可以考虑一种STDP模型,一个孤立的突触前或突触后脉冲即使不和另一个脉冲成对也会导致突触权重的微小变化,该方法在模型中用于产生突触后神经元的总输入的稳态控制。
另一种对STDP模型实现稳态控制的可能是通过设置STDP的窗函数依赖于按秒作为时间尺度运行的平均激发率。
6、电压依赖性
脉冲时序依赖可塑性的实验和模型表明突触权重的变化是由突触前后脉冲的紧密的时间相关性引起的。然而其他的实验协议表明突触后脉冲对产生突触的长时程增强和抑制不是必要的,这些实验中突触前脉冲和固定的突触后神经元的去极化相配对。而且,即使脉冲的时序是固定的,在动作电位产生之前突触后神经元的电压会影响突触的变化方向,这表明突触后电压比脉冲时序更加重要。
STDP的现象学模型
除了突触延迟以外,所有的突触权重变化都可以由突触前后神经元脉冲来描述。突触前、突触后、目标脉冲序列分别表示为 S i ( t ) , S o ( t ) , S d ( t ) S_i(t),S_o(t),S_d(t) Si(t),So(t),Sd(t),每个序列都是单个脉冲的叠加 S ( t ) = ∑ f δ ( t − t f ) S(t) = \sum _f \delta(t-t_f) S(t)=∑fδ(t−tf)。
突触权重的改变包括三部分:当不考虑 a a a和Non-Hebbian时,同经典STDP。
- 无脉冲时的自衰减 a a a
- 突触前脉冲带来的影响
- Non-Hebbian:无突触后脉冲时的自影响
- 突触前后脉冲时序的影响
- 突触后脉冲带来的影响
- Non-Hebbian:无突触前脉冲时的自影响
- 突触前后脉冲时序的影响
突触权重的更新如下:
d
ω
(
t
)
d
t
=
a
+
S
i
(
t
)
[
a
i
+
∫
0
∞
a
i
d
(
s
)
S
d
(
t
−
s
)
d
s
]
+
S
d
(
t
)
[
a
d
+
∫
0
∞
a
d
i
(
s
)
S
i
(
t
−
s
)
d
s
]
\frac{d \omega(t)}{d t}=a+S_{i}(t)\left[a_{i}+\int_{0}^{\infty} a_{i d}(s) S_{d}(t-s) d s\right]+S_{d}(t)\left[a_{d}+\int_{0}^{\infty} a_{d i}(s) S_{i}(t-s) d s\right]
dtdω(t)=a+Si(t)[ai+∫0∞aid(s)Sd(t−s)ds]+Sd(t)[ad+∫0∞adi(s)Si(t−s)ds]
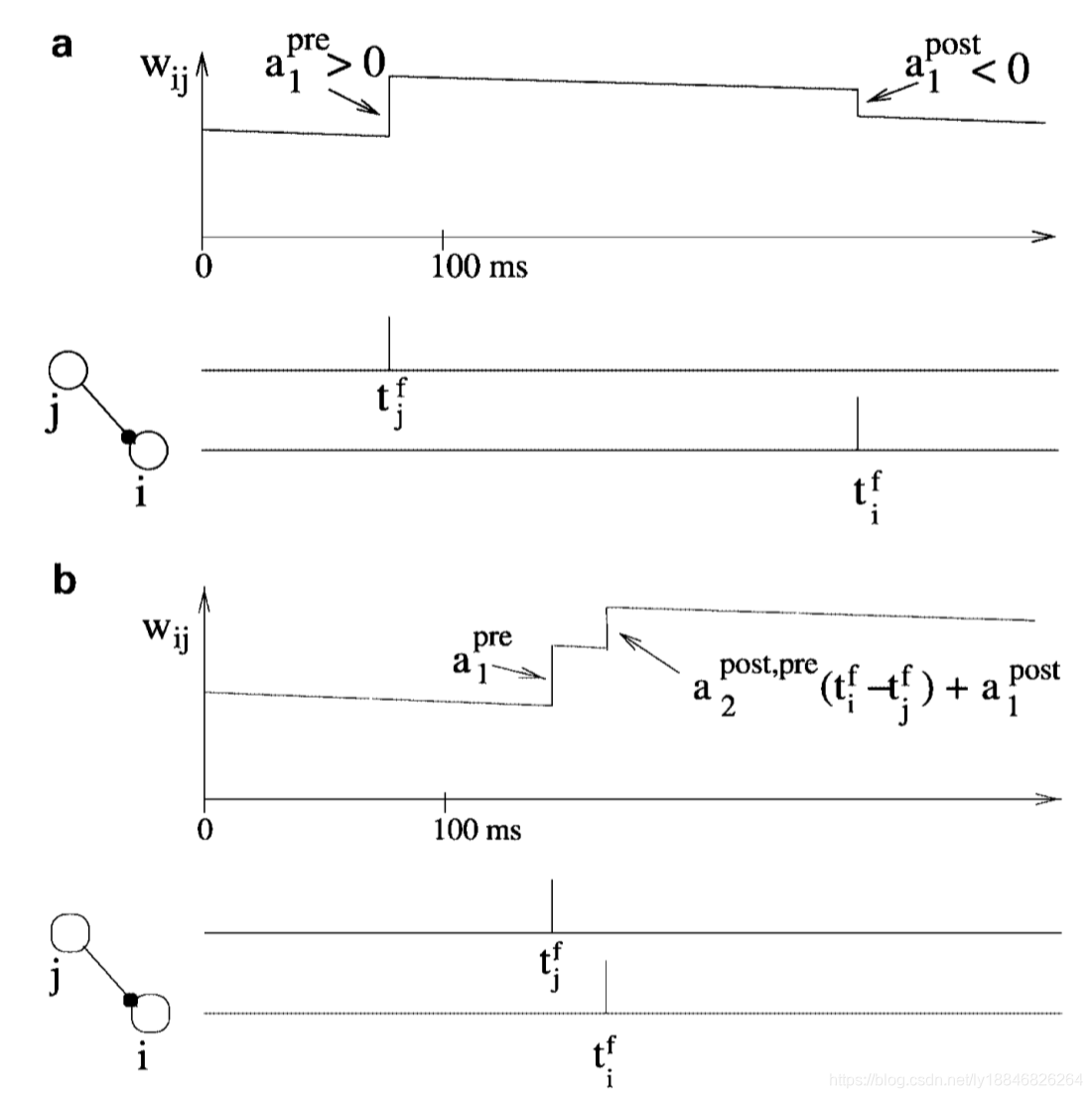
注意积分时从0开始的,也就是说当突触前脉冲到来的时候,只看在此之前的突触后脉冲,按照经典STDP,此时应该是抑制作用;反之为增强作用。对于突触前后脉冲时序
s
=
t
i
f
−
t
d
f
s=t_i^f -t_d^f
s=tif−tdf的影响,
a
i
d
,
a
d
i
a_{id},a_{di}
aid,adi定义窗口函数如下:
W
(
s
)
=
{
A
+
exp
[
s
/
τ
+
]
for
s
<
0
A
−
exp
[
−
s
/
τ
−
]
for
s
>
0
W(s)=\left\{\begin{array}{cl} A_{+} \exp \left[s / \tau_{+}\right] & \text {for } s<0 \\ A_{-} \exp \left[-s / \tau_{-}\right] & \text {for } s>0 \end{array}\right.
W(s)={A+exp[s/τ+]A−exp[−s/τ−]for s<0for s>0
即
a
i
d
(
s
)
a_{id}(s)
aid(s)对应
s
>
0
s>0
s>0,
a
d
i
(
s
)
a_{di}(s)
adi(s)对应
s
<
0
s<0
s<0。
STDP和其他学习规则的关系
STDP与Hebb
STDP可以看做是Hebb学习规则的基于脉冲的形式。Hebb提出如果突触前神经元重复或者持续的参与激发突触后神经元那么应该加强突触。这要求突触前神经元要在突触后神经元之前不久激发。事实上,在关于神经元突触的标准STDP实验中,突触的增强发生在之前在之后之前的时序上,这与Hebb的假设一致。但是,Hebb没有假设减弱的存在。在典型的STDP学习规则上存在一个减弱连接强度的时间窗,在某种意义上,这是对Hebbian假设的扩展。
然而,突触减弱的存在早在STDP的发现之前就被提出了。Stent在1973年就已经认为,来自突触前神经元的与突触后神经元不协同活动的输入应该被减弱。与STDP相比的一个重要区别是,Stentian对Hebb假设的扩展不强调时间上的对比,只是持续缺乏巧合。
STDP与基于速率的学习规则
在突触前神经元和突触后神经元的脉冲发放活动相互独立的假设下,STDP模型可以映射到基于速率的学习规则。
Δ
w
i
j
=
α
f
i
(
t
)
f
j
(
t
)
\Delta w_{i j}=\alpha f_{i}(t) f_{j}(t)
Δwij=αfi(t)fj(t)
其中,
α
=
∫
W
(
s
)
d
s
\alpha=\int W(s)ds
α=∫W(s)ds,后面两项表示一段时间上突触前后神经元的脉冲发放率。
经典STDP代码 【Matlab】
% Excitatory neurons Inhibitory neurons
Ne=800; Ni=200;
n=Ne+Ni;
re=rand(Ne,1); ri=rand(Ni,1);
a=[0.02*ones(Ne,1); 0.1*ones(Ni,1)];
b=[0.2*ones(Ne,1); 0.2*ones(Ni,1)];
c=[-65*ones(Ne,1); -65*ones(Ni,1)];
d=[8*ones(Ne,1); 2*ones(Ni,1)];
S=[0.5*rand(Ne+Ni,Ne), -rand(Ne+Ni,Ni)];
p=0.7; % 30% of zero-weight synapses when p=0.7
totzeros=0; % Count of zero-weight synapses
plasticity=20; % Plastic changes happen after the first 20 ms of runtime
runtime=1000; % Runtime in ms
v=-65*ones(Ne+Ni,1); % Initial values of v
u=b.*v; % Initial values of u
firings=[]; % spike timings
LFP=zeros(runtime,3);
ADJ=zeros(runtime,n);
count=0;
count2=0;
%MAKE THE NETWORK SPARSELY CONNECTED
M=rand(n,n);
for i=1:n
for jjj=1:n
if M(i,jjj)>p
S(i,jjj)=0;
totzeros=totzeros+1;
end
if i==jjj
S(i,jjj)=0; %no self connections
totzeros=totzeros+1;
end
end
end
SPARSE=S;
for t=1:runtime % simulation of runtime ms
I=[5*randn(Ne,1);2*randn(Ni,1)]; % thalamic input
fired=find(v>=30); % indices of spikes
for jj=1:numel(fired)
ADJ(t,fired(jj))=1; % RECORD WHICH NEURONS FIRE AT EACH MS
end
if t>plasticity %t>20 for STDP on, t>runtime for STDP off
for j=1:n
count2=count2+1;
if ADJ(t,j)==1 %neuron j fired at time t
count=count+1;
for x=1:20 %range of ms over which synaptic strengthening and weakening occur
for k=1:n
if ADJ(t-x,k)==1 % find out which neurons fired in the previous 20 ms
% synaptic weight of pair undergoes larger increment if dT is smaller and negative
S(j,k)=S(j,k).*(1+(0.9*exp(x/20.0)));
% synaptic weight of pair undergoes larger decrement is dT is smaller and positive
S(k,j)=S(k,j).*(1+(-0.925*exp(-x/20.0)));
% set a maximum value for synaptic weights
if S(j,k)>2.0
S(j,k)=2.0;
end
if S(j,k)<-2.0
S(j,k)=-2.0;
end
if S(k,j)>2.0
S(k,j)=2.0;
end
if S(k,j)<-2.0
S(k,j)=-2.0;
end
end
end
end
end
end
end
firings=[firings; t+0*fired,fired]; % left column is time, right is index of neuron firing out of 1000.
v(fired)=c(fired);
u(fired)=u(fired)+d(fired);
I=I+sum(S(:,fired),2);
v=v+0.5*(0.04*v.^2+5*v+140-u+I); % step 0.5 ms
v=v+0.5*(0.04*v.^2+5*v+140-u+I); % for numerical stability
u=u+a.*(b.*v-u); % update u
LFP(t,1)=sum(v(1:Ne,1)); % sum of voltages of excitatory per ms
LFP(t,2)=sum(v((Ne+1):n,1)); % sum of voltages of inhibitory per ms
LFP(t,3) = sum(v(:)); % sum of all voltages for each ms
end
参考
[1] Scholarpedia
[2] Spike-timing dependent synaptic plasticity: a phenomenological framework

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









