









技术综述
-
VISUAL QUESTION ANSWERING: FROM EARLY DEVELOPMENTS TO RECENT ADVANCES - A SURVEY (https://arxiv.org/pdf/2501.03939)

VQA 可以解决广泛的 AI 问题,包括图像分类、目标检测、计数、场景分类、属性分类、活动识别和推理理解。
VQA任务描述:
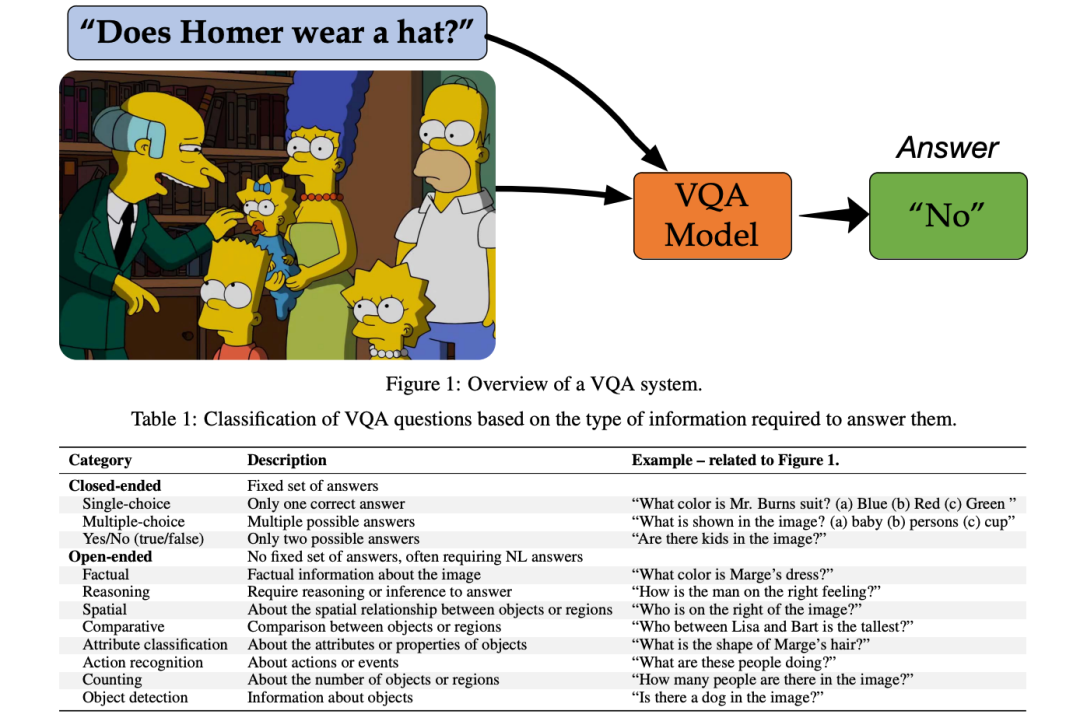
VQA架构:
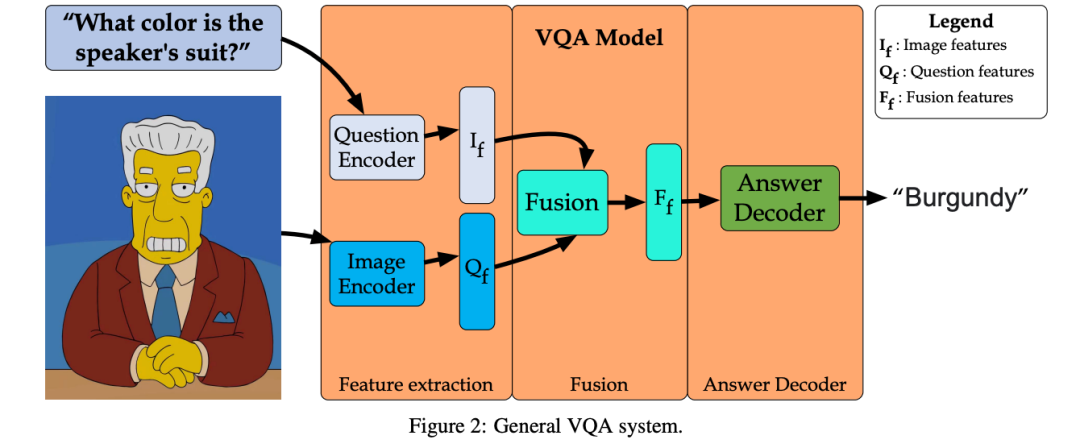
VQA 系统通常由三个阶段组成:特征提取、融合和答案解码器。四个主要组件:视觉编码器、语言编码器、融合机和答案解码器
视觉编码器技术:
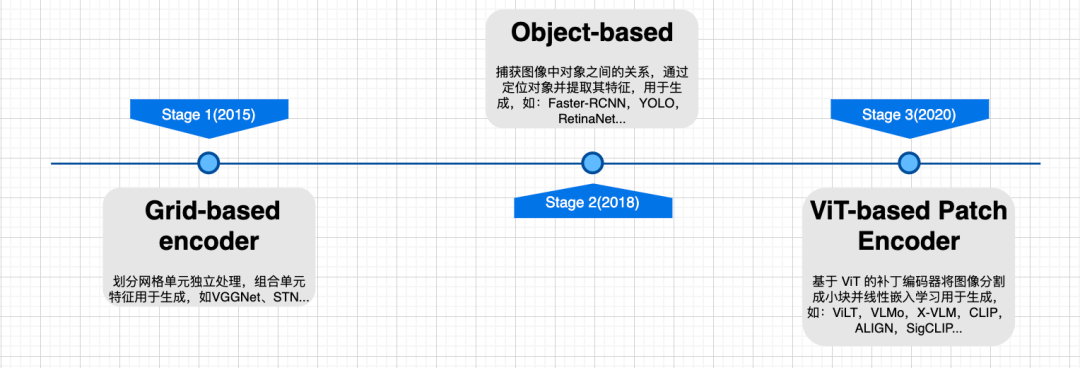
两阶段模型(Stage2):
Faster-RCNN: 基于区域的方法,用于检测输入图像中的重要对象,单次方法在一次神经网络前向传递中完成对象检测和分类。通常使用一组默认的边界框形状(称为锚点)来预测每个锚点的类别和位置偏移。
YOLO: 基于锚点的方法也使用锚点框来预测对象位置和类别,但它们在多个尺度和纵横比上创建锚点框,以更好地处理不同大小和形状的对象。
RetinaNet: 基于锚点的方法,使用骨干 CNN 模型(VGGNet/ResNet)提取检测到的边界框的视觉特征,这些特征有助于识别对象属性、数量和类别以进行准确推断
语言编码器:
语言编码器负责将问题的原始文本转换为数值潜在表示
-
Word BoW
-
RNN
-
CNN
-
Transformer:
-
词嵌入与视觉标记连接送入ViLT, VLMo;
-
直接输入捕获语言特征,然后与视觉特征交互;
-
特征融合(融合机):
将来自视觉编码器的图像表示和来自问题解码器的问题表示作为输入,并提供融合的多模态特征作为输出
-
逐元素乘法、求和或连接进行融合
-
基于Attention的方法:隐式的选择性(需要关注的)的进行融合
-
视觉注意力:如SANs使用 softmax 函数堆叠注意力网络以进行多步推理,根据给定问题选择视觉信息中的狭窄区域。
-
共同注意力:允许模型同时关注视觉和文本输入,使用视觉表示来引导问题注意力,并使用问题表示来引导视觉注意力,如:HieCoAtt,DCN。
-
Transformer:兼顾了共同注意力的优势,同时也考虑了模态内的自注意力能力,如:MCAoAN,DETR。
-
-
神经模块网络(NMNs):VQA 中的输入问题可能需要多步推理才能正确回答,NMNs专门设计用于处理问题的组合结构,如:Stack-NMN。
-
双线性池化方法:输入之间更复杂交互的简单方法
-
关系网络:基于图的方法,利用图神经网络结合抽象图像和问题的图表示。
-
LVLM:视觉语言预训练模型,LVLM 模型分为四种训练方法:对比训练、掩码训练、预训练骨干和生成模型。
模型架构
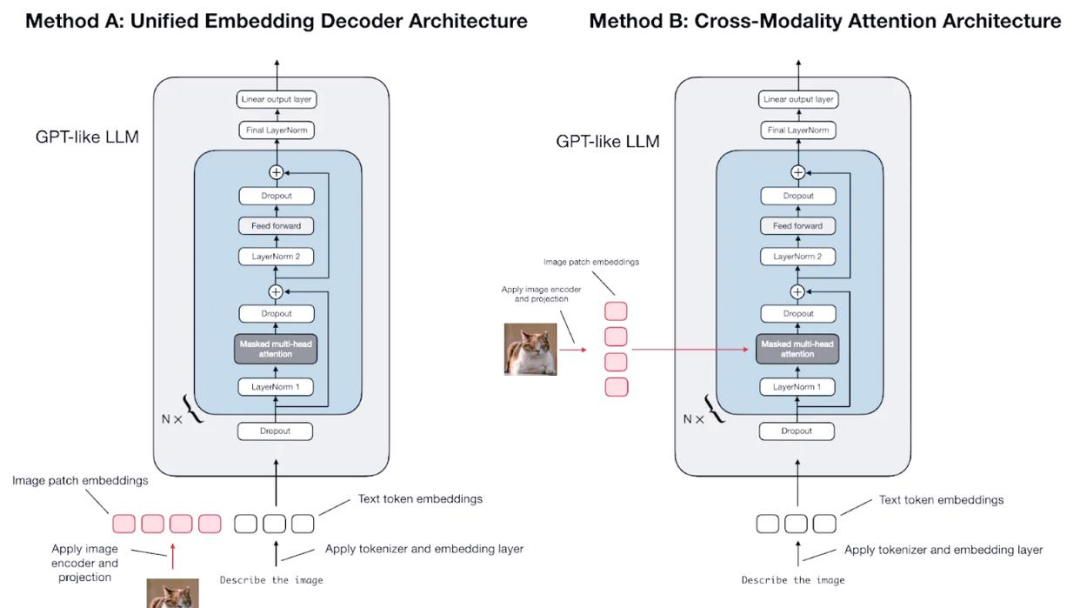
主流模型
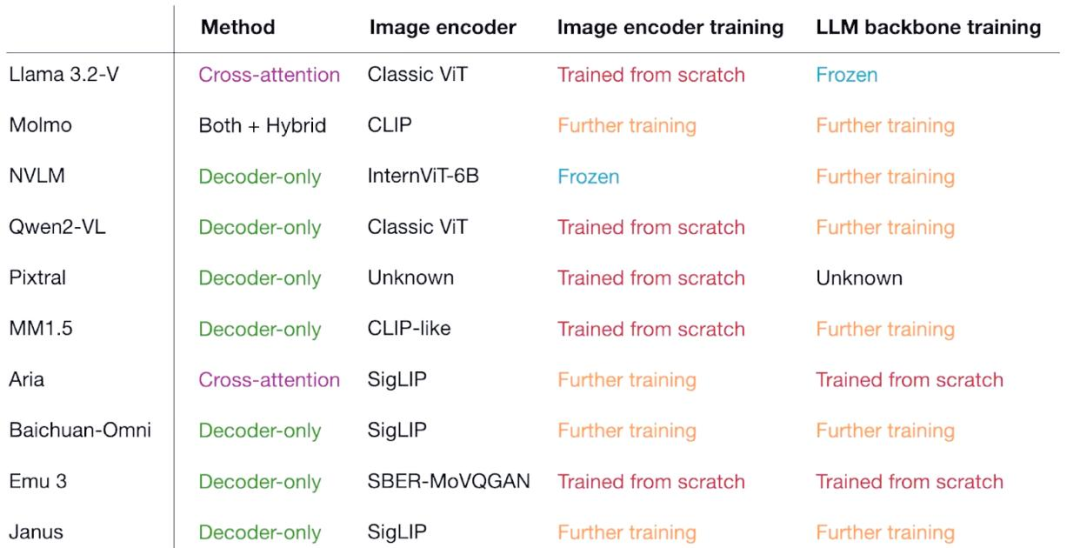
| 训练方式 | 训练方式 | 适用情况 | 数据需求 | 计算资源 |
|---|---|---|---|---|
| Trained from scratch | 直接从随机初始化训练 | 适用于新领域或研究新模型 | 需要大量数据 | 高 |
| Fine-tuning | 在预训练模型基础上继续训练 | 适用于特定任务优化 | 需要较少数据 | 低 |
推荐阅读:
-
https://zhuanlan.zhihu.com/p/684472814
-
https://zhuanlan.zhihu.com/p/706145455
Qwen-VL系列技术详解
Qwen1-VL架构:
-
https://arxiv.org/pdf/2308.12966
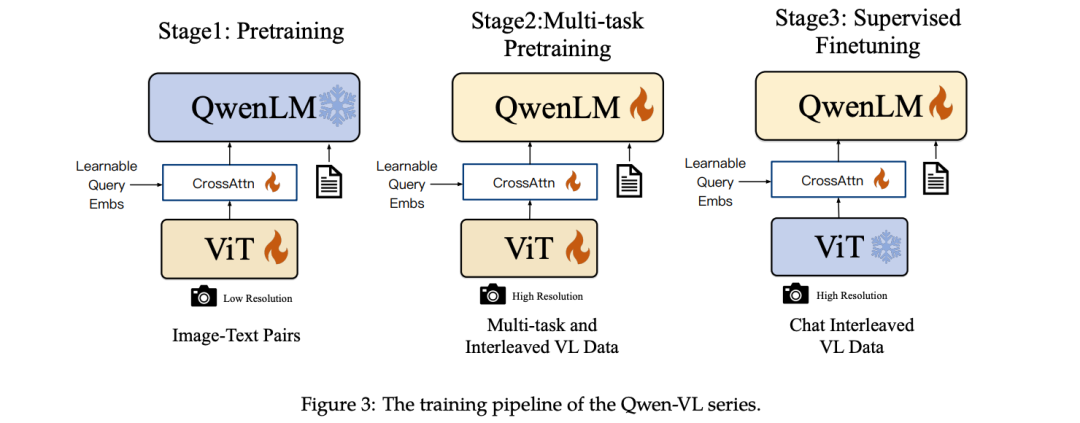
Qwen2-VL架构:
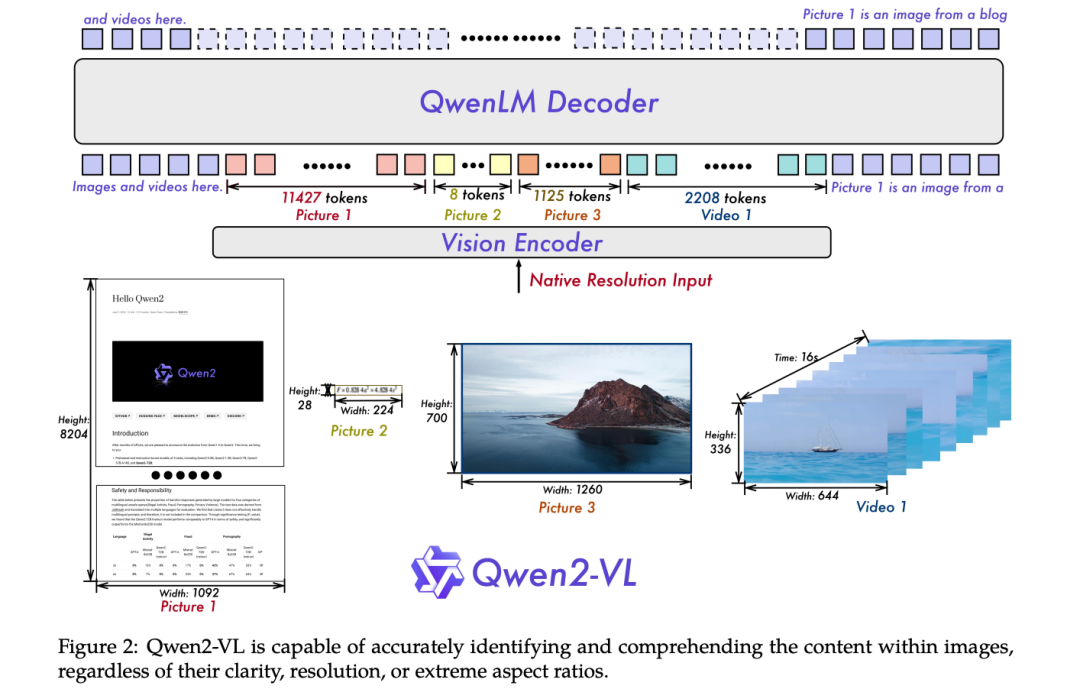
Qwen2-VL位置编码:

Qwen2-VL模型组成:
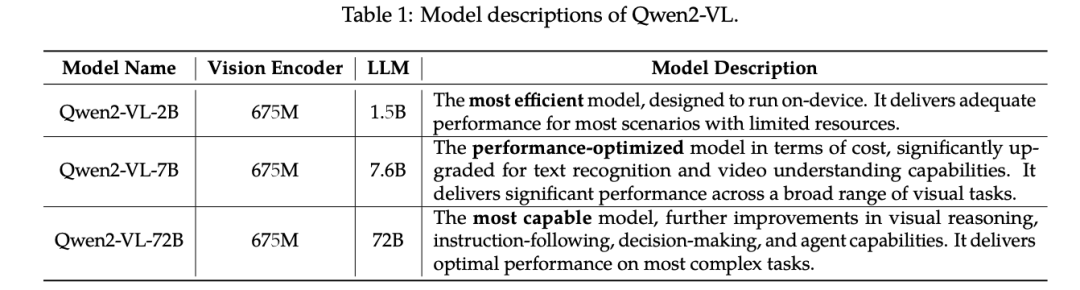
LLM部分是阿里自家的Qwen-XB为基座语言模型,同时引入视觉编码器ViT-Visual Encoder,模型为 Openclip ViT-bigG 编码器,将输入的图像数据编码为文本信息,使得模型具有对视觉信息的理解和处理能力,并通过位置感知的视觉语言适配器Position-aware Vision-Language Adapter,在信息融合的过程中引入单层随机初始化的交叉注意力机制(cross-attention)将视觉信息直接融合到语言模型的解码器层中进行内集连接多模态,使得模型支持视觉与文本多种信号输入。
-
https://zhuanlan.zhihu.com/p/690365919
-
https://zhuanlan.zhihu.com/p/698509663
Qwen-VL技术概要
Qwen-VL架构三个核心组件:
-
大型语言模型(LLM)
-
视觉编码器(Visual Encoder)
-
位置感知适配器(Position-aware Vision-Language Adapter):
Qwen-VL的训练流程:
-
预训练阶段:使用大规模图像-文本对数据集进行预训练,冻结LLM参数,优化Vision Encoder和VL Adapter,目标是对齐视觉和语言特征。
数据类型:大规模图文对数据 -
多任务预训练阶段:使用高质量细粒度VL标注数据,同时训练多个任务,提升模型的多模态能力,输入分辨率提升至448x448,不冻结任何模块。
数据类型:混合图文内容、视觉问答数据集、多任务数据集、纯文本数据 -
监督微调阶段:冻结Vision Encoder,优化LLM和VL Adapter参数,使用对话交互数据进行提示调优,得到交互式Qwen-VL-Chat模型。
数据类型:纯文本对话、多模态会话数据、图像问答、文档解析、多图比较、视频理解、视频流对话、基于代理的交互
数据预处理:文本和图像数据分别通过各自的编码器进行预处理。文本数据由大型语言模型编码,而图像数据则通过视觉编码器处理。特征融合:不同模态的数据在模型内部被有效融合,采用紧密融合的方式,使得不同模态之间的信息能够更好地协调和互动,从而提升跨模态任务的表现。任务执行:融合后的特征被用于执行各种多模态任务,如图文匹配、视觉问答、文档问答、图像描述等。Qwen VL在这些任务中表现出色,尤其在细粒度的文字识别和检测框标注方面具有显著优势
输入(image,text)随机初始化一组可学习的Query和image做CrossAttention,学习图像中的信息,然后和文本一起拼接后送入LLM ,模型输出预测的文本向量,和原本输入的文本向量计算CE Loss
S1: 预训练,VIT训练
LM预训练本质上就是训练一个Decoder,next token预测的方式,所以目标函数就是交叉熵。
数据类型:大规模图文对数据
数据质量的清洗策略:
-
Removing pairs with too large aspect ratio of the image
-
Removing pairs with too small image
-
Removing pairs with a harsh CLIP score (dataset-specific)
-
Removing pairs with text containing non-English or non-Chinese characters
-
Removing pairs with text containing emoji characters
-
Removing pairs with text length too short or too long
-
Cleaning the text’s HTML-tagged part
-
Cleaning the text with certain unregular patterns
输入和输出:
-
图像输入: 图像通过视觉编码器和适配器处理,生成固定长度的图像特征序列。为了区分图像特征输入和文本特征输入,两个特殊标记(和)分别附加在图像特征序列的开头和结尾,表示图像内容的开始和结束。
-
边界框输入和输出: 为了增强模型对细粒度视觉理解和定位的能力,Qwen-VL的训练涉及区域描述、问题和检测形式的数据。与涉及图像文本描述或问题的传统任务不同,此任务需要模型准确理解和生成指定格式的区域描述。对于任何给定的边界框,应用归一化过程(范围为[0, 1000))并转换为指定字符串格式:“(X_topleft,Y_topleft),(X_bottomright,Y_bottomright)”。该字符串被标记化为文本,不需要额外的位置词汇表。为了区分检测字符串和常规文本字符串,在边界框字符串的开头和结尾添加两个特殊标记(和)。此外,为了适当关联边界框与其相应的描述性词语或句子,引入另一组特殊标记(和),标记边界框引用的内容。
第一阶段预训练中,模型使用AdamW优化器进行训练,β1=0.9,β2=0.98,eps=1e-6。我们使用余弦学习率计划,最大学习率为2e-4,最小为1e-6,线性预热500步。我们使用0.05的权重衰减和1.0的梯度裁剪。对于ViT图像编码器,我们应用层级学习率衰减策略,衰减因子为0.95。训练过程使用30720的图像文本对批次大小,整个第一阶段预训练持续50,000步,消耗大约15亿个图像文本样本和5000亿个图像文本标记。
S2: 多任务预训练
包含7个任务的数据:黑色文本为无损失的前缀序列,蓝色文本为带损失的地面真值标签。
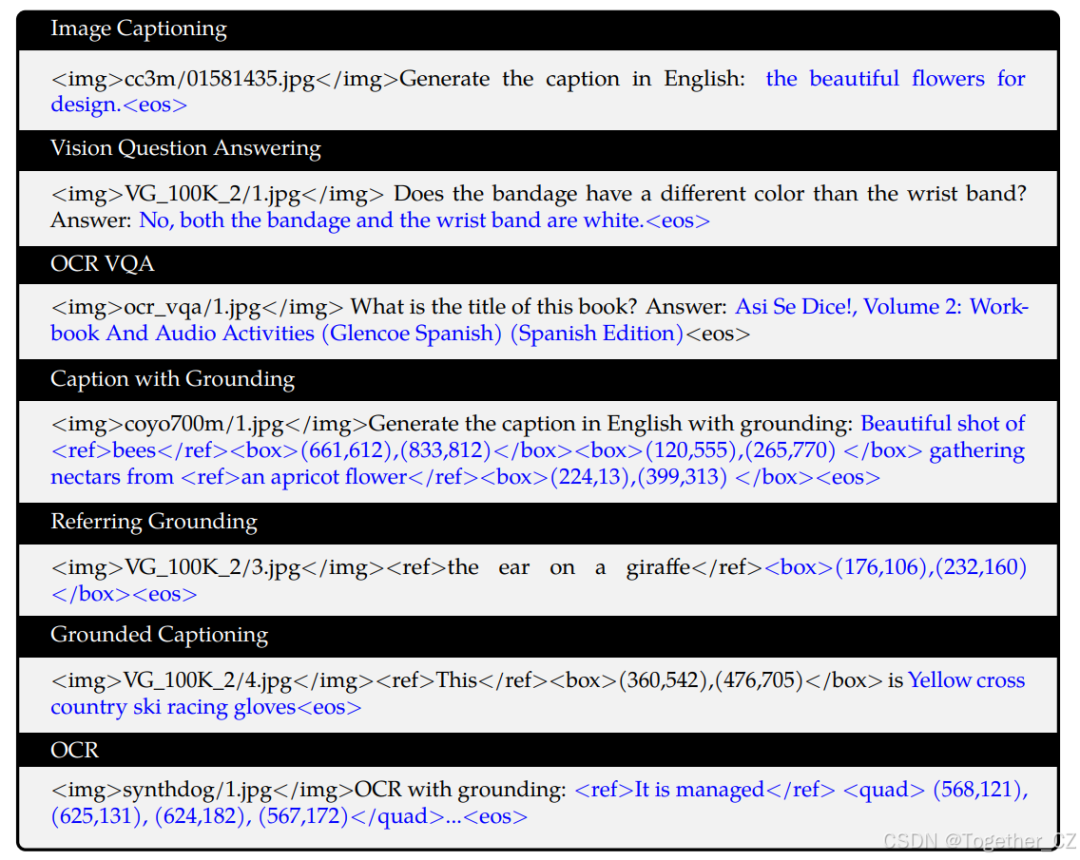
第二阶段多任务训练中,我们将视觉编码器的输入分辨率从224×224增加到448×448,减少了图像下采样引起的信息损失。我们解锁了大型语言模型并训练整个模型。训练目标与预训练阶段相同。我们使用AdamW优化器,β1=0.9,β2=0.98,eps=1e-6。我们训练了19000步,预热400步,余弦学习率计划。具体来说,使用模型并行技术进行ViT和LLM。
S3: 指令微调
LLamaFactory最新已支持Qwen-VL的训练推理。
数据格式:ChatML格式

为了更好地适应多图像对话和多图像输入,我们在不同图像前添加字符串“Picture id:”,其中_id_对应图像输入对话的顺序。在对话格式方面,我们使用ChatML(Openai)格式构建指令微调数据集,其中每个交互的陈述用两个特殊标记(<im_start>和<im_end>)标记,以方便对话终止。
在训练过程中,我们通过仅监督答案和特殊标记(示例中的蓝色部分),而不监督角色名称或问题提示,确保预测和训练分布的一致性。
VLM技术:文生图、图生图
技术综述
-
Controllable Generation with Text-to-Image Diffusion Models: A Survey T2I模型综述
-
https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
-
https://arxiv.org/abs/2403.04279
-
-
A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models,基于文生图(Text-to-Image,T2I)大模型的图像编辑算法进行了总结和回顾。
-
https://github.com/xinchengshuai/Awesome-Image-Editing
-
https://arxiv.org/abs/2406.14555
-
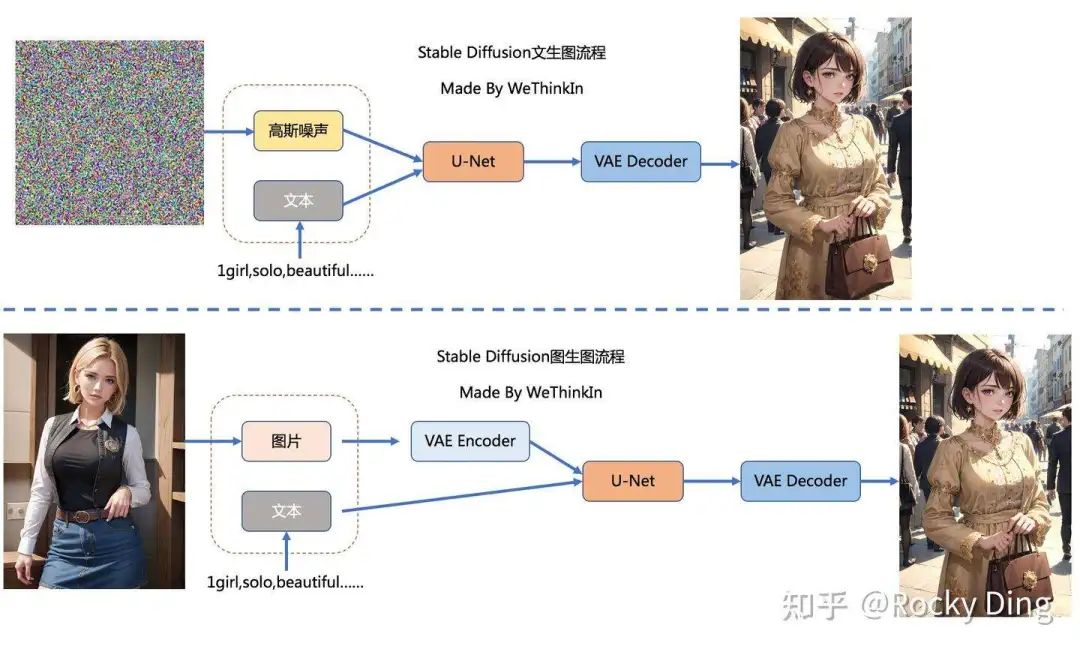
文生图任务: 只需要输入文本信息,再用random函数生成一个高斯噪声矩阵作为Latent Feature的“替代”输入到SD模型的“图像优化模块”中,经过一定的迭代次数输出一张符合输入文本描述的图片。
图生图任务: 在输入本文的基础上,再输入一张图片,将原图片通过图像编码器(VAE Encoder)生成Latent Feature(隐空间特征)作为输入。
文生图模型:Stable Diffusion技术详解
SD是CompVis、Stability AI和LAION等公司研发的一个开源文生图模型,它的模型、代码、训练数据LAION-5B都是开源的。SD的主要应用,这包括文生图,图生图以及图像inpainting。
Stable Diffusion原来的名字叫“Latent Diffusion Model”(LDM):扩散过程发生隐空间中(latent space),其实就是对图片做了压缩,这也是Stable Diffusion比Diffusion速度快的原因。Stable Diffusion其实是Diffusion的改进版本,主要是为了解决Diffusion的速度问题。Stable Diffusion XL系列模型(简称SDXL)是Stable Diffusion的最新优化版本。
-
参考: https://zhuanlan.zhihu.com/p/643420260
SD是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。
-
SD 1.4官方项目:CompVis/stable-diffusion
-
SD 1.5官方项目:runwayml/stable-diffusion
-
SD 2.x官方项目:Stability-AI/stablediffusion
-
diffusers库中的SD代码pipelines:diffusers/pipelines/stable_diffusion
-
核心论文:High-Resolution Image Synthesis with Latent Diffusion Models
-
SD Turbo技术报告:adversarial_diffusion_distillation
SD模型变迁
| SD模型版本 | 模型架构组成 | 训练策略 | 模型参数 |
|---|---|---|---|
| Stable Diffusion 1.x-2.x | U-Net+VAE+CLIP Text Encoder | -- | -- |
| Stable Diffusion XL 0.9 | 新增基于Latent的Refiner模型 | 图像尺寸条件化策略、图像裁剪参数条件化策略以及多尺度训练策略等。 | Base模型35亿+Refiner模型31亿 |
| Stable Diffusion XL 1.0 | 同0.9 | +更多训练集+RLHF | -- |
-
SDXL Base模型构成:U-Net、VAE以及CLIP Text Encoder(两个),在FP16精度下Base模型大小6.94G(FP32:13.88G),其中U-Net占5.14G、VAE模型占167M以及两个CLIP Text Encoder一大一小(OpenCLIP ViT-bigG和OpenAI CLIP ViT-L)分别是1.39G和246M。
-
SDXL Refiner模型构成:U-Net、VAE和CLIP Text Encoder(一个),在FP16精度下Refiner模型大小6.08G,其中U-Net占4.52G、VAE模型占167M(与Base模型共用)以及CLIP Text Encoder模型(OpenCLIP ViT-bigG)大小1.39G(与Base模型共用)。
-
SDXL VAE模型有:sdxl_vae.safetensors、lastpiecexlVAE_baseonA0897.safetensors、fixFP16ErrorsSDXLLowerMemoryUse_v10.safetensors、xlVAEC_f1.safetensors、flatpiecexlVAE_baseonA1579.safetensors等。

重要Paper:
-
Denoising Diffusion Probabilistic Models : DDPM,这个是必看的,推推公式
-
Denoising Diffusion Implicit Models :DDIM,对 DDPM 的改进
-
Pseudo Numerical Methods for Diffusion Models on Manifolds :PNMD/PLMS,对 DDPM 的改进
-
High-Resolution Image Synthesis with Latent Diffusion Models :Latent-Diffusion
-
Neural Discrete Representation Learning : VQVAE
推荐阅读:
-
深入浅出扩散模型(Diffusion Model)系列:基石DDPM(模型架构篇),最详细的DDPM架构图解:https://zhuanlan.zhihu.com/p/637815071
-
深入浅出扩散模型(Diffusion Model)系列:基石DDPM(源码解读篇):https://zhuanlan.zhihu.com/p/655568910
-
深入浅出扩散模型(Diffusion Model)系列:基石DDPM(人人都能看懂的数学原理篇):https://zhuanlan.zhihu.com/p/650394311
-
https://www.zhihu.com/collection/942080780?page=2
-
https://www.zhihu.com/question/577079491/answer/2954363993
SD训练推理架构: SD模型整体上是一个End-to-End模型,主要由三部分构成:
-
CLIP Text Encoder: 提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition
-
VAE(变分自编码器,Variational Auto-Encoder): 图像压缩和图像重建
-
U-Net: 扩散模型的主体,用来实现文本引导下的latent生成
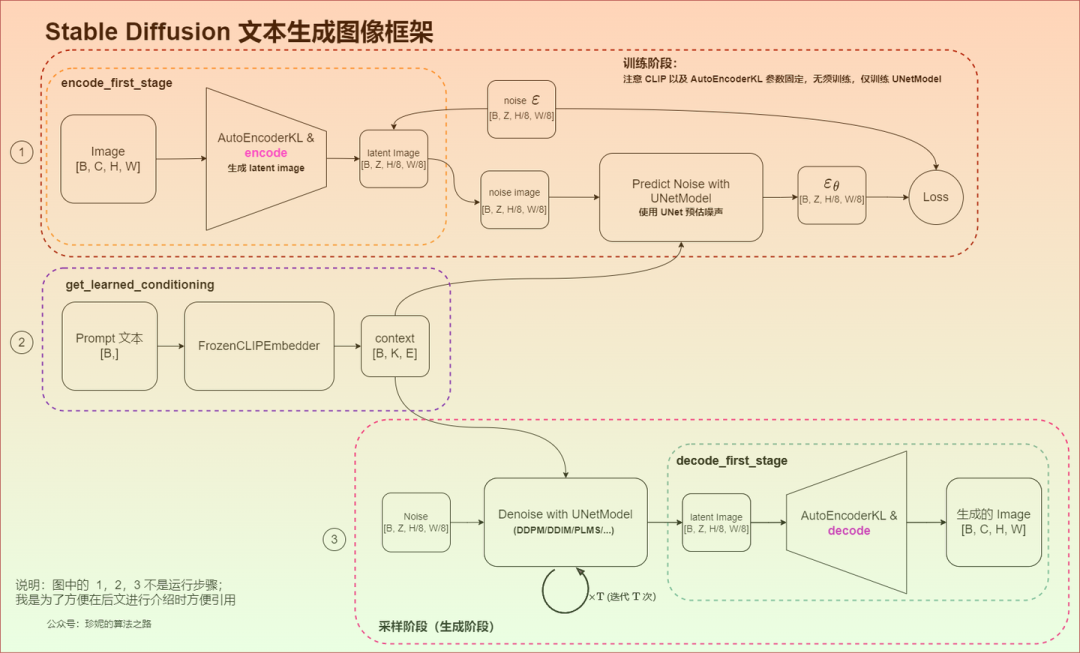
“图像优化模块”是由一个U-Net网络和一个Schedule算法共同组成,U-Net网络负责预测噪声,不断优化生成过程,在预测噪声的同时不断注入文本语义信息。而schedule算法对每次U-Net预测的噪声进行优化处理(动态调整预测的噪声,控制U-Net预测噪声的强度),从而统筹生成过程的进度。在SD中,U-Net的迭代优化步数(Timesteps)大概是50或者100次,在这个过程中Latent Feature的质量不断的变好(纯噪声减少,图像语义信息增加,文本语义信息增加)。U-Net网络和Schedule算法的工作完成以后,SD模型会将优化迭代后的Latent Feature输入到图像解码器(VAE Decoder)中,将Latent Feature重建成像素级图像。
扩散过程本质是一个参数化的马尔可夫链(Markov chain),扩散模型的反向扩散过程和前向扩散过程正好相反:
-
前向扩散过程(Forward Diffusion Process): 图片中持续添加噪声。对于初始数据,设置扩散步数为K步,每一步增加一定的噪声,如果我们设置的K足够大,那么就能够将初始数据转化成随机噪声矩阵。
-
反向扩散过程(Reverse Diffusion Process): 持续去除图片中的噪声
训练目标:将扩散模型每次预测出的噪声和每次实际加入的噪声做回归,让扩散模型能够准确的预测出每次实际加入的真实噪声。
SD训练逻辑:
1). 从数据集中随机选择一个训练样本
2). 从K个噪声量级随机抽样一个timestep
3). 将timestep t 对应的高斯噪声添加到图片中
4). 将加噪图片输入U-Net中预测噪声
5). 计算真实噪声和预测噪声的L2损失
6). 计算梯度并更新SD模型参数
在SD模型的训练中,每个训练样本都会对应一个文本描述的标签,我们将对应标签通过CLIP Text Encoder输出Text Embeddings,并将Text Embeddings以Cross Attention的形式与U-Net结构耦合并注入,使得每次输入的图片信息与文本信息进行融合训练
SD文生图模型结构详解
SD模型主要有四个模块:
-
autoencoder:encoder将图像压缩到latent空间,而decoder将latent解码为图像;
-
CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition;
-
UNetModel: 扩散模型的主体,用来实现文本引导下的latent生成。
-
ResBlock:
-
timestep_embedding:
-
SpatialTransformer:
SD的扩散模型是一个860M的UNet,其主要结构如下图所示(这里以输入的latent为64x64x4维度为例),其中encoder部分包括3个CrossAttnDownBlock2D模块和1个DownBlock2D模块,而decoder部分包括1个UpBlock2D模块和3个CrossAttnUpBlock2D模块,中间还有一个UNetMidBlock2DCrossAttn模块。encoder和decoder两个部分是完全对应的,中间存在skip connection。注意3个CrossAttnDownBlock2D模块最后均有一个2x的downsample操作,而DownBlock2D模块是不包含下采样的。
评价指标:
对于文生图模型,目前常采用的定量指标是FID(Fréchet inception distance)和CLIP score,其中FID可以衡量生成图像的逼真度(image fidelity),而CLIP score评测的是生成的图像与输入文本的一致性,其中FID越低越好,而CLIP score是越大越好。
谷歌的Imagen引入了人工评价,先建立一个评测数据集DrawBench(包含200个不同类型的text),然后用不同的模型来生成图像,让人去评价同一个text下不同模型生成的图像
VLM技术:VLA
推荐阅读:
-
机器人操作VLA模型论文整理: https://zhuanlan.zhihu.com/p/7371838810
基础模型介绍
变分自编码器:VAE
推荐阅读:
-
https://zhuanlan.zhihu.com/p/2433292582(一文详解 codebook 技术史(从 VAE 到 VQ/RQ-VAE 到 FSQ))
-
https://zhuanlan.zhihu.com/p/698502893(重新发现VAE(Variational Autoencoders))
-
https://kexue.fm/archives/5253
原理介绍
VAE的核心思想是把隐向量看作是一个概率分布。具体: 编码器(encoder)不直接输出一个隐向量,而是输出一个均值向量和一个方差向量,它们刻画了隐变量的高斯分布,这样我们就可以从这个分布中随机采样隐向量,再用解码器(decoder)生成新图片了。

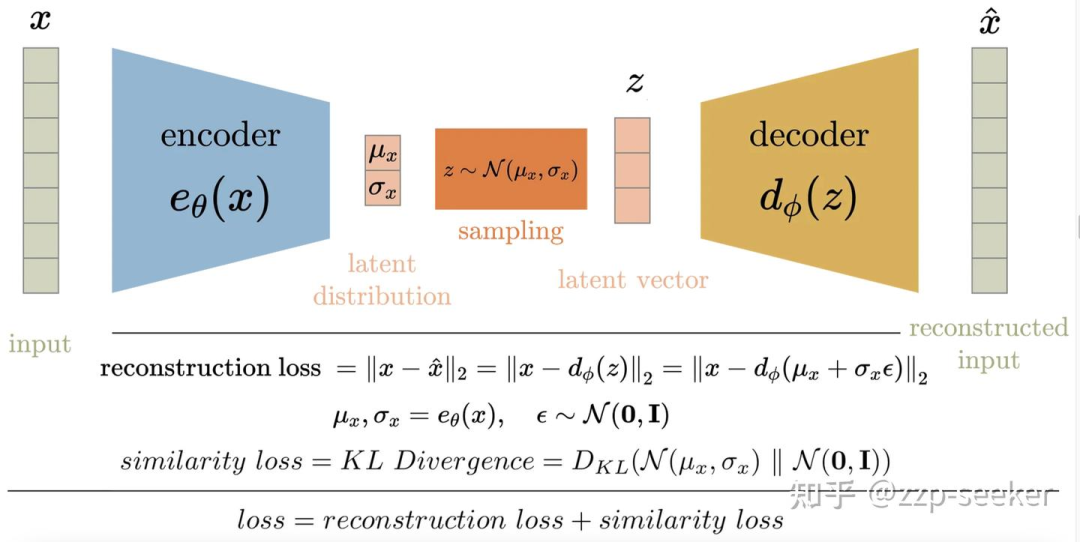
ELBO:
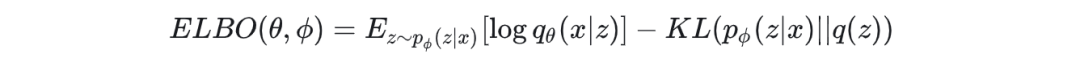
注:ELBO,即evidence low bound,evidence指的就是 x,而 ELBO 表示 evidence 的最小期望。我们要让这个 lower bound 尽可能变大,得到的模型就会更可能产生我们期望看到的 x 。
降维-升维
降维目的: 找到最佳编码器/解码器对(encoder/decoder pair)
-
VQ-VAE的流程:encoder将图片编码,同时通过最邻近搜索将编码得到的特征对codebook进行映射,得到离散的latent feature,最后latent feature送入decoder重建得到RGB图片。VQ-VAE相当于维护了一个codebook,而并非直接对连续的latent feature做重构。
视觉语言预训练:CLIP
其他系列类似技术: ALBEF
CLIP其实并没有太大的创新,本质是将ConVIRT方法进行简化,并采用更大规模的文本-图像对数据集来训练。
推荐阅读:
-
https://zhuanlan.zhihu.com/p/493489688
-
https://zhuanlan.zhihu.com/p/486857682(CLIP系列Paper解读)
原理介绍
CLIP模型是一个双骨架结构,包括一个文本编码器Text Encoder和一个图像编码器Image Encoder。训练数据集的形式为(image, text),对于每个正确匹配的image和text,text是对image的一句正确描述。CLIP模型需要对(image, text)的数据对进行预测,即(image, text)匹配的为1,不匹配的为0。
-
Text Encoder: 对每个Text编码成一个隐向量维度[1,512], N个Text即[N,512]
-
Image Encoder: 对于每张 Image编码成一个隐向量维度[1,512], N张图即[N,512]
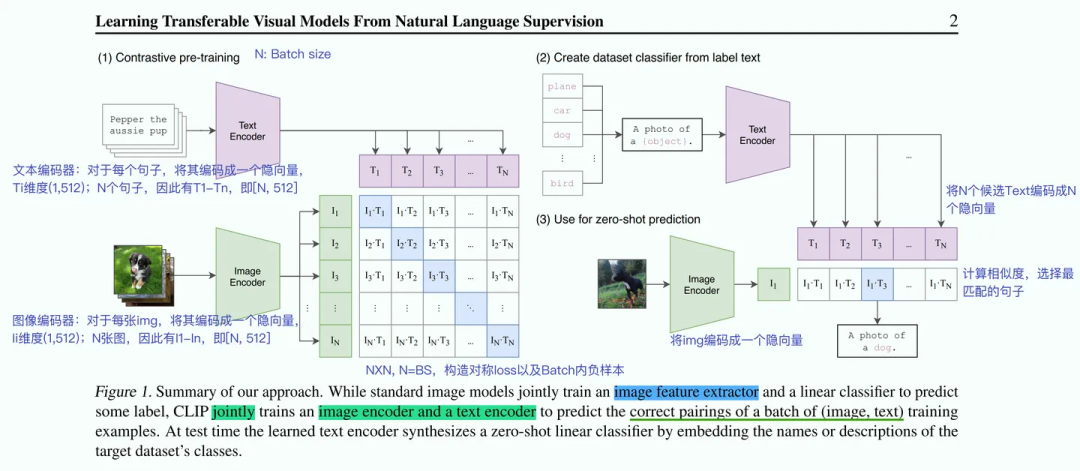
公开数据集:MS-COCO、Visual Genome & YFCC100M
github:https://github.com/OpenAI/CLIP
paper:Learning Transferable Visual Models From Natural Language Supervision
CLIP采用对称损失函数,简单来说,就是对相似度矩阵,分别从行方向和列方向计算loss,最后取两者的平均。 给定批量中有N个图像和文本对, 损失函数由两部分交叉嫡组成:
其中是图像和文本的特征向量的点积,是超参温度系数,对应伪代码里面的,控制softmax输出的锐度/平滑度。
CLIP 经过预训练,可以预测图像和文本片段在其数据集中是否配对在一起。对于每个数据集,CLIP 采用数据集中所有类的名称作为潜在的文本配对集,并根据CLIP 预测最可能的 (image, text) 配对。更详细的说,就是首先通过各自的编码器计算图像的特征嵌入 和 可能文本集的特征嵌入,然后计算这些嵌入的余弦相似度,用温度参数 t 进行缩放,并通过 softmax 归一化为概率分类。该预测层是一个多项式逻辑回归分类器,具有L2归一化输入、L2归一化权重、无偏差和温度缩放,当以这种方式解释时,图像编码器是计算图像特征表示的计算机视觉骨干,文本编码器是一个超网络,文本编码器根据指定类所表示的视觉概念的文本生成线程分类器的权重。
CLIP 在一些细分类的数据集上的效果也并不好,并且无法处理特别抽象的概念,eg计算图中有多少物体。因此,CLIP 在检索任务上的表现非常优秀,但是在 VQA(Visual Question Answering, 视觉问答) 等一些需要逻辑推理的任务上能力稍显不足。
虽然 CLIP 的泛化性能很好,但是如果测试数据集完全偏离训练数据集,那么 CLIP 的表现依旧较差。分析 CLIP 的训练数据集可以发现,其训练数据集中虽然有 4亿个 “图像-文本” 对,但是极个别方向相关的图片数量十分稀少,所以在此方向的数据 对CLIP而言就是处于特征分布外的数据。
下游应用
-
zero-shot分类
对比自监督的方法(无需构建数据),如:基于对比学习的方法如MoCo和SimCLR,和基于图像掩码的方法如MAE和BeiT,但迁移下游需要微调;
ViLD(https://arxiv.org/abs/2104.13921): 基于CLIP实现了开放词汇的物体检测;
Detic(https://arxiv.org/abs/2201.02605): 利用CLIP实现2000个类;
-
图像检索
基于文本搜索图像:CLIP作为DALL-E的排序模型,即从生成的图像中选择和文本相关性较高的。
-
视频理解
VideoCLIP(https://arxiv.org/abs/2109.14084): CLIP应用在视频领域来实现zero-shot视频理解任务。
-
图像编辑
指导图像编辑任务: HairCLIP(https://arxiv.org/abs/2112.05142),用CLIP来定制化修改发型。
-
图像生成
StyleCLIP(https://arxiv.org/abs/2103.17249): 用CLIP实现了文本引导的StyleGAN;
CLIP-GEN(https://arxiv.org/abs/2203.00386): 基于CLIP来训练文本生成图像模型,训练无需直接采用任何文本数据;
-
视觉自监督学习
MVP: (Multimodality-guided Visual Pre-training: https://arxiv.org/abs/2203.05175)
-
VL任务:
用在用图像-文本多模态任务,如图像描述(image caption)和视觉问答(Visual Question Answering),https://arxiv.org/abs/2107.06383
推荐阅读:
-
https://zhuanlan.zhihu.com/p/486857682(【CLIP系列Paper解读】CLIP: Learning Transferable Visual Models From Natural Language Supervision)
-
https://zhuanlan.zhihu.com/p/493489688
VIT模型
推荐阅读:
-
https://www.zhihu.com/question/538049269/answer/2532582294(ViT(Vision Transformer)的改进算法?)
-
https://zhuanlan.zhihu.com/p/356155277(VIT paper)
-
https://blog.csdn.net/m0_37605642/article/details/133821025
原理介绍
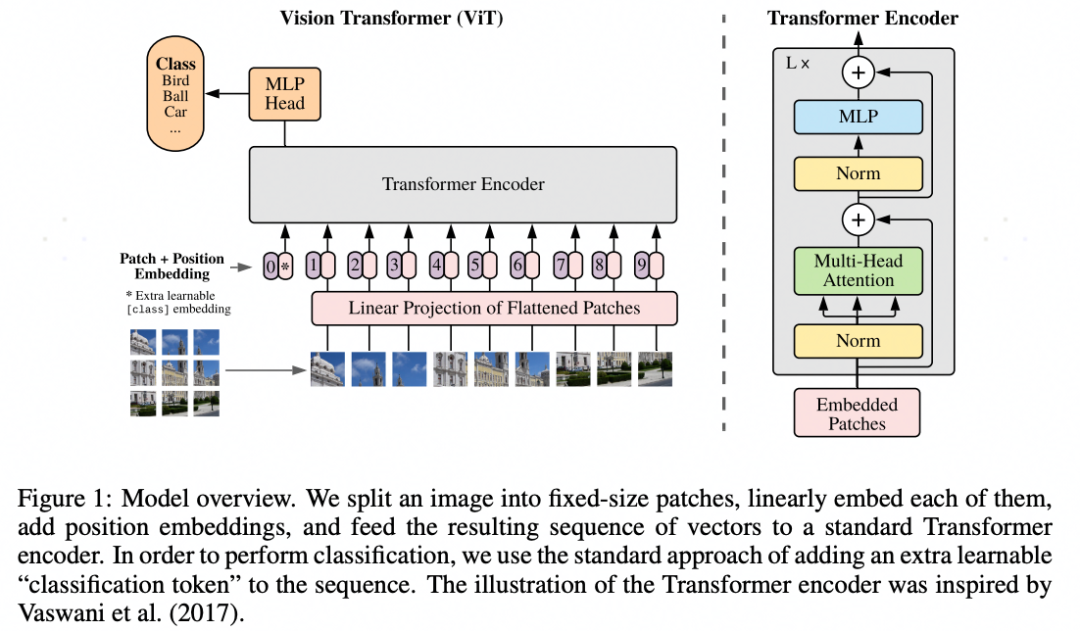
ViT 全称 Vision Transformer,基于transformer的Encoder来提取特征。思路:把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding
ViT是基于多个transformer encoder模块串联起来,由多个inception模块串联起来,基本结构由patch_embeding + n transformer layer + head(分类网络中就是FC)构成。
An image is worth 16x16 words: Transformers for image recognition at scale
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
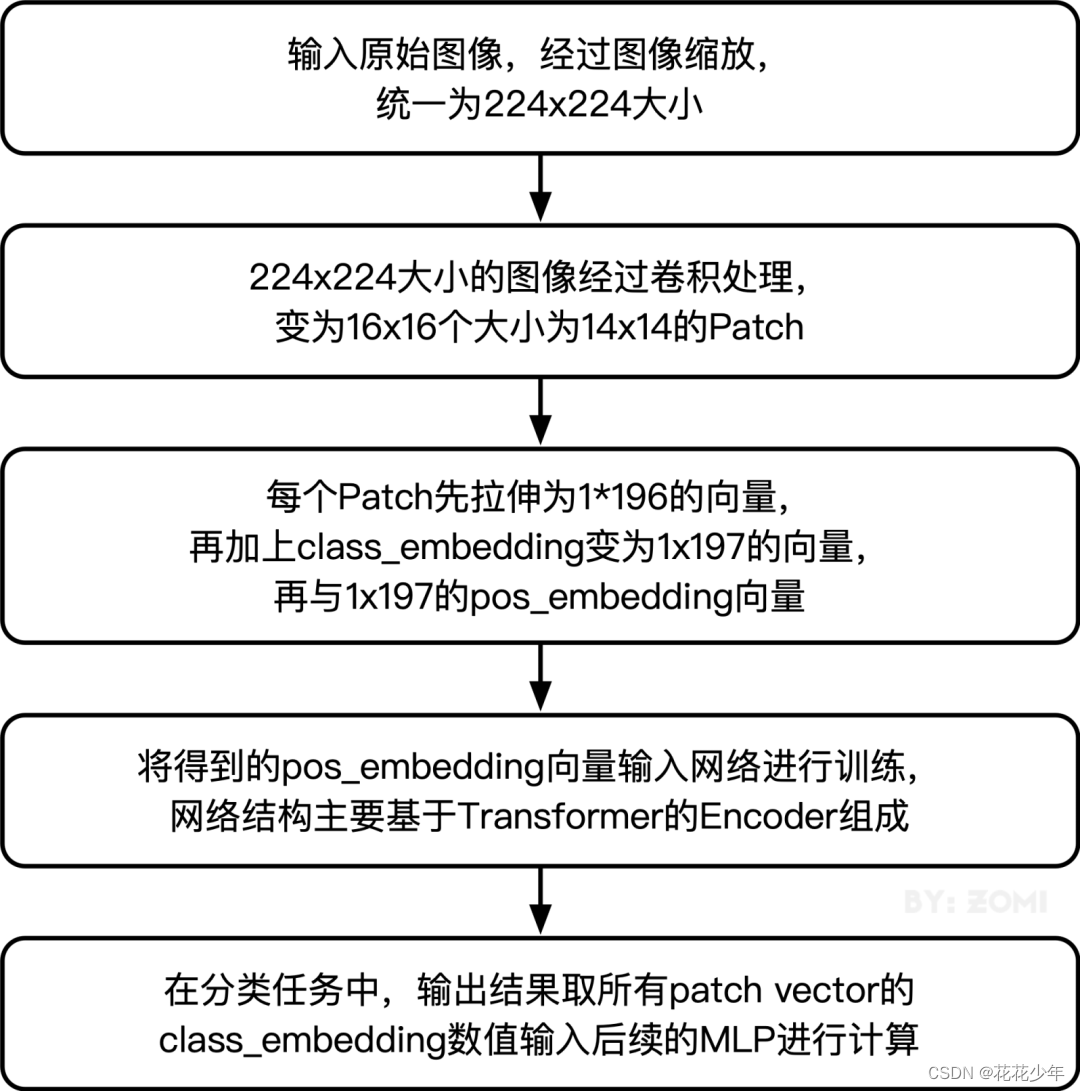
ViT模型输入:Patch Embedding+Class Embedding+Position Embedding。VIT模型的数据流转流程图:
当数据集较小时,VIT表现明显弱于卷积网络。但当数据量级大于21k时,VIT的能力就上来了。
| NLP Transformer | ViT |
|---|---|
| 句子 | 图像 |
| words | patchs |
| word embedding | patch embedding |
BLIP模型
BLIP(Bootstrapping Language-Image Pretraining)是salesforce在2022年提出的多模态框架,是理解和生成的统一,引入了跨模态的编码器和解码器,实现了跨模态信息流动,在多项视觉和语言任务取得SOTA。
推荐阅读:
-
https://zhuanlan.zhihu.com/p/640887802
前沿技术阅读材料(持续更新)
𓀀 [Paper]: Democratizing Contrastive Language-Image Pre-training: A CLIP Benchmark of Data, Model, and Supervision
Abstract: CLIP的一些改进工作
𓀀 [Paper]: InternVL-1.5: How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Abstract: InternVL-1.5综合性能更强,且支持推理时高达4K的分辨率。
𓀀 [Paper]: InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Abstract: nternVL的三阶段渐进式训练策略,训练数据质量逐渐提高,最开始使用大规模有噪的图文对进行对比预训练 (类似CLIP),接着加入冻结参数的QLLaMA连接件,只学习cross-attention,使用图文匹配/对比/生成loss (类似BLIP),最后引入LLM进行监督微调,赋予多模态对话和问答能力。
𓀀 [Paper]: LLaVA-NeXT: A Strong Zero-shot Video Understanding Model
Abstract: 24年4月,LLaVA-NeXT-Video发布,展现出强大的zero-shot视频理解能力。LLaVA-NeXT中的高分辨率图像动态划分可以很自然地迁移到视频模态用来表示视频的多帧,使得只在图文模态上训练的LLaVA-NeXT能在视频任务上泛化。此外,推理时的长度泛化用于有效处理超出LLM最大长度的长视频输入。基于LLaVA-NeXT-Image模型,作者发布了在视频数据上监督微调的LLaVA-NeXT-Video,以及在AI反馈的监督下使用DPO偏好对齐的LLaVA-NeXT-Video-DPO。使用SGLang部署和推理,支持可扩展的大规模视频推理。可以想到,这有助于海量视频的高效文本标注,催生了未来更强大视频生成模型。
𓀀 [Paper]: LLaVA-NeXT: Improved reasoning, OCR, and world knowledge
Abstract: LLaVA-NeXT(1.6)在1.5的基础上保持了精简的设计和数据高效性,支持更高的分辨率、更强的视觉推理和OCR能力、更广泛场景的视觉对话。模型分为两阶段训练:阶段1预训练只训练连接层,阶段2指令微调训练整个模型。
𓀀 [Paper]: LLaVA-1.5: Improved Baselines with Visual Instruction Tuning
Abstract: LLaVA-1.5通过在视觉和语言模态间添加简单的MLP层实现了训练样本高效性,为多模态大模型在低数据业务场景的落地提供了可能。
𓀀 [Paper]: Controllable Generation with Text-to-Image Diffusion Models: A Survey
Abstract: T2I模型综述
-
https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
-
https://arxiv.org/abs/2403.04279
𓀀 [Paper]: A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Abstract: 基于文生图(Text-to-Image,T2I)大模型的图像编辑算法进行了总结和回顾。
-
https://github.com/xinchengshuai/Awesome-Image-Editing
-
https://arxiv.org/abs/2406.14555
𓀀 [Blog]: 为什么vae效果不好,但vae+diffusion效果就好了?
https://www.zhihu.com/question/649097976/answer/3453419858
-
VQ-VAE的流程:encoder将图片编码,同时通过最邻近搜索将编码得到的特征对codebook进行映射,得到离散的latent feature,最后latent feature送入decoder重建得到RGB图片。VQ-VAE相当于维护了一个codebook,而并非直接对连续的latent feature做重构。
Stable Diffusion的思路则是“既然通过一个压缩后的latent feature能够表征好一张图,那就索性在latent feature的隐空间上做扩散”,因此Stable Diffusion本质上是一个latent diffusion model。
用diffusion model去拟合的隐空间分布,能够逼近VAE或者VQ-VAE用encoder编码RGB图片得到的latent feature分布。
𓀀 [Paper]: 利用潜在扩散模型进行高分辨率图像合成
High-Resolution Image Synthesis With Latent Diffusion Models Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
𓀀 [Paper]: AI图片编辑模型:Text2Place
Abstract: Text2Place 是一项强大的技术,能够将任何人或物体逼真地放置在不同的背景中。它通过给定的一张背景图像和文本提示,预测出合理的语义区域,以放置人类或其他物体。
𓀀 [Paper]: 多模态大模型幻觉雪崩的缓解之道:Investigating and Mitigating the Multimodal Hallucination Snowballing in Large Vision-Language Models
Abstract: 多模态大模型的视觉感知容易受到文本部分噪声的影响,对幻觉雪崩的评测:作者造了个名为MMHalSnowball的评测框架,发现文本部分的噪声会让LLaVa、BLIP-2等开源MLLM的accuracy掉20-50个点,GPT4-V也会掉将近10个点。
提出了视觉残差解码(Residual Visual Decoding),即利用 去掉文本context的图形+文本query对应的干净输出分布,将原始输出分布(对应图形+可能有噪声的文本context+文本query)和干净输出分布集成后作为最终输出。
𓀀 [Paper]:FFF: Fixing Flawed Foundations in contrastive pre-training results in very strong Vision-Language models
Abstract: 重新审视CLIP预训练目标的文章: CLIP的图文对比学习预训练目标中,取in-batch负例的做法可能是有bug的,忽视了可能的假负例。对一段文本来说,来自batch内其他图文对的图片也有可能在语义上和它很相似,实际上是正例,但CLIP的InfoNCE loss直接把batch内其他图文对中的文本视为负例。
-
引入了假负例纠正机制,当两个样本满足图-文相似度>p1或图-图相似度>p2或 (文-文相似度>p3且图-文相似度>p1')时,就视为假负例,将标签纠正为正。
-
引入了一个caption模型给图片生成文本正例
𓀀 [Paper]: DeepSeek-VL
Abstract: DeepSeek-VL具有通用的多模态理解能力,能够处理逻辑图表、网页、公式识别、科学文献、自然图像等。模型设计主要是采用了交叉视觉特征,考虑到clip的特征分辨率较低,结合目前比较火的sam的视觉特征,由于sam提取了更多的语义细节,将clip和sam-b的特征进行融合(融合细节参考论文),增强了对图像的表达能力,最后经过2层mlp,将视觉特征送入到llm模型。经过3个阶段的训练及微调,结果表现还不错。比如能提取到图像中的小目标,甚至对截图的代码进行解释(训练利用了ocr数据集)。目前已经开放了1.3b和7b的模型。
https://arxiv.org/pdf/2403.05525
𓀀 [Paper]: Learn to explain: Multimodal reasoning via thought chains for science question answering
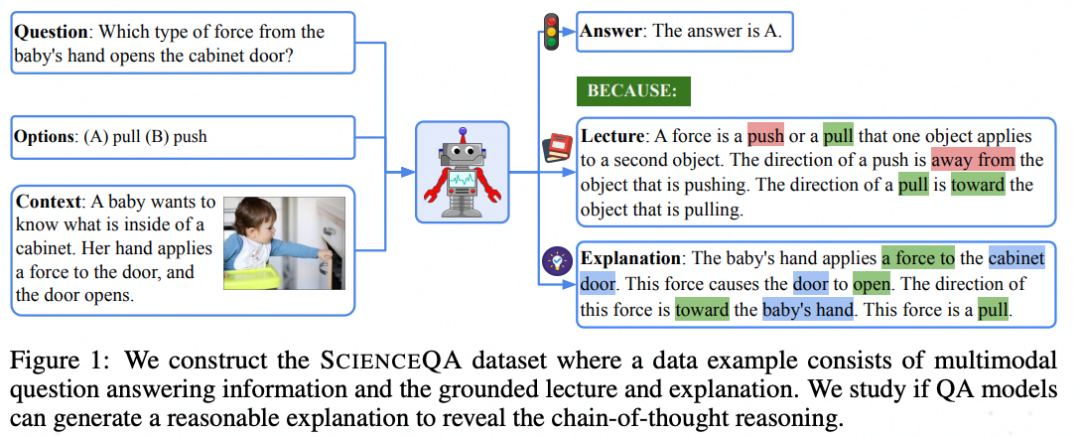
Abstract: 提出一个多模态的ScienceQA数据集,证明CoT生成Explanation对多模态问答的有效性。核心思路是通过链式思维(CoT)提示构建了一个Few-shot的GPT-3模型推理范式,以同时生成答案、讲解和解释。

https://www.zhihu.com/collection/942080780?page=2
𓀀 [Paper]: LLaVA: Large Language and Vision Assistant Visual Instruction Tuning
https://zhuanlan.zhihu.com/p/625723805https://zhuanlan.zhihu.com/p/660132053
𓀀 [Paper]: Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
https://zhuanlan.zhihu.com/p/657385270
𓀀 [Paper]: COGVLM: VISUAL EXPERT FOR LARGE LANGUAGE MODELS
https://zhuanlan.zhihu.com/p/662011803
𓀀 [Paper]: CogAgent: A Visual Language Model for GUI Agents
https://www.sohu.com/a/748524268_121119001


















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









