







PCIE 学习笔记
书到用时方恨少啊,一年前学PCIE的笔记,再拿出来瞅瞅。发到博客上,方便看。
PCIE基础
PCIE和PCI的不同
PCIE采用差分信号传输,并且是dual-simplex传输——每条lane上有TX通道和RX通道,所以每条lane上的信号是4条。PCI是同步时钟、并行传输。
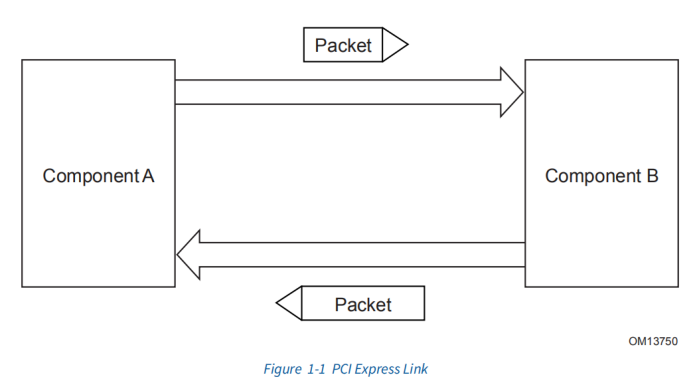
PCIE是端到端的传输,一条链路上只能有两个设备,而PCI是共享总线型的。
PCIE的lane可以扩展成x2, x4, x8, x16, x32.
PCIE没有专门的中断信号,而是通过message报文传输。
PCIE version | Gigabits/second/lane/direction | coding |
V1 | 2.5 | 8/10b |
V2 | 5 | 8/10b |
V3 | 8 | 128/130b |
V4 | 16 | 128/130b |
V5 | 32 | 128/130b |
PCIE 拓扑
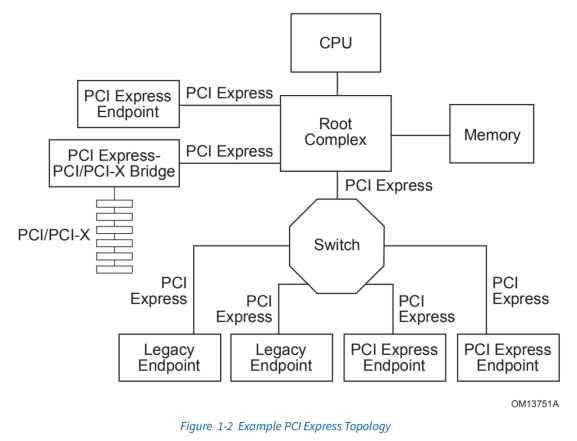
PCIE系统主要包括RC、Switch和EP(pcie设备)。一个PCIE树上最多可以有256个PCIE设备。
组件
RC (ROOT COMPLEX)
RC是PCIE树的根节点,RC可以有一个或者多个PCIE端口(port),它可以根CPU 和memory controller相接,或者说分隔PCIE domain和CPU/MEMORY domain。
类似于PCI 中的HOST主桥。
Switch

Switch有一个上游端口和两个或者两个以上的下游端口。上游端口是RC或者上游Switch的下游端口。
Switch中每个端口都可以看成是一个PCI-to-PCI bridge,这些bridge也都有配置空间,跟PCI中一样,配置空间有IO/Memory 的base address和limit size。
Switch中还有一条虚拟的PCI总线连接Switch内部的各个bridge。
Switch还支持crosslink的连接方式,也就是Switch上游端口可以和其他Switch的上游端口连接;下游端口也可以和其他Switch的下游端口连接。
Ingress和Egress:在一次传输中,Switch中的端口可分为ingress port和egress port,划分跟数据流向有关。Ingress port就是数据进来的端口,egress port就是输出流出的端口。
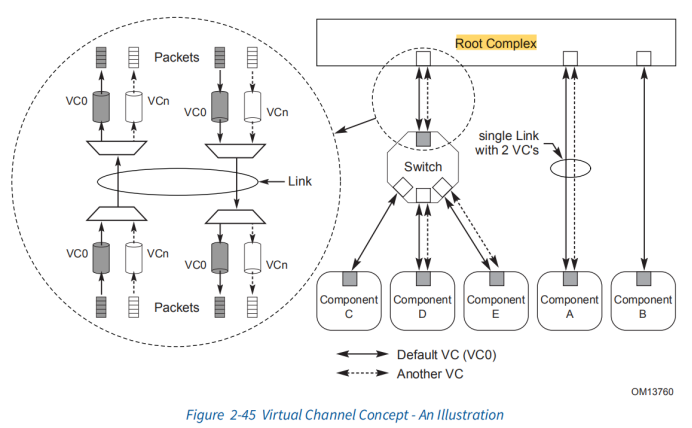
Virtual channel:端口上一般都会采用virtual channel的技术来缓存不同ingress port发来的数据。Virtual channel就是buffer,缓存数据。最多8个VC。
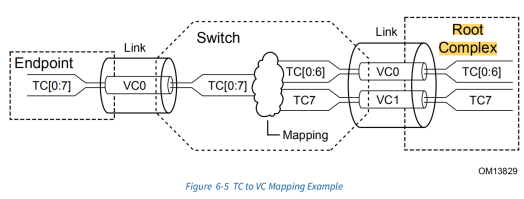
数据在Switch中传输,涉及到VC/TC mapping、端口仲裁、VC仲裁。
EP(endpoint)
EP有三种: legacy EP,PCIE EP,RC integrated EP。
Legacy EP:就是PCI device
PCIE EP:
RC integrated EP:集成在RC内部的EP。
PCIE bridge
PCIE bridge就是PCI-to-PCI/PCI-X bridge
PCIE 层次简介

PCIE协议分为如上三层:transaction layer, data link layer, physical layer。
发送端发送的报文以此经过transaction -> data link layer ->physical,经过物理链路到达接收端,又经过physical layer->data link layer -> transaction layer到达接收端。
不同层次的数据包格式如下,这个简单的格式,实际更复杂:

在transaction layer,TLP由header+data+ECRC,可能也会有TLP Prefix和TLP digest。
Data link layer接受transaction layer的TLP报文,加上sequence number和LCRC;在data link layer还有自己独有的DLLP,DLLP尽在data link layer以下传输,不会传到transaction layer。
transaction layer service
主要是生成和接受TLP,进行基于credit的flow control,power management。
在初始化和配置中,事务层的作用:
保存处理器设置的链路配置信息;
将物理层链路协商的bus width 和frequency保存在link capabilities结构中。
在TLP生成的接收中,事务层的作用:
为device core发出的请求生成TLP。
将接受到的请求转换成device core可识别的Requests(或者说一种格式吧)
从接受到的完成报文提取出data payload和status信息给到device core。
识别出不支持的TLP,并且采用合适的机制进行处理。
如果支持end-to-end 数据完整性,那么生成CRC,并且更新对应的TLP header。
在流控中,事务层的作用:
追踪传输中TLP的flow control credit信息。
将credit status周期性地传递给对端的transaction layer,这是通过data link layer实现的。
根据credit来阻塞TLP传输。
事务层在ordering的作用:
PCI/PCI-X兼容的生产者-消费者ordering model。
Relaxed-ordering
ID-Based ordering
事务层在电源管理的作用:
软件控制的电源管理
硬件自动控制的电源管理。
事务层在VC和TC上的作用:
结合VC和TC机制,来为不同类型的服务和应用提供不同的服务和QoS。
Virtual channel
Traffic class
Data link layer service
初始化和电源管理的作用:
接收来自transaction layer的电源状态请求,并将他们传递给physical layer。
将active/reset/disconnected/power managed state传给transaction layer。
数据保护、错误检查、重试:
CRC生成。
为了重试机制,保存发送的TLP。
错误检查
TLP应答和retry messages。
错误报告和打印。
Physical layer service
接口初始化、maintenance control、状态追踪
复位、热插拔控制和状态
连线的电源管理
协商Width and lane mapping
Lane polarity inversion。
生成Symbol和ordered set
8b/10b 编码、解码。
嵌入式的时钟tuning和对齐。
Symbol传输和对齐
传输电路
接收电路
接收端的弹性缓冲器
接收端的Multi-lane de-skew
DFT feature
PCIE配置空间

0x00- 0x3f这段配置空间是PCI、PCIE设备都要支持的。
0x40-0xff这段空间主要存放于MSI中断和电源管理相关的capabilities。
0x100-0xfff是PCIE所独有的。
Capability
Capability是PCI/PCIE配置结构,一个capability对应一个capability point和一段空间,可以把一个capability看做寄存器set,
多个capability组成capability 链表,上一个capability保存下一个capability的point。当然会有一个其实的capability point register。
每种Capability 结构中的capability ID是唯一的,
PCI Power management capability

PCIE capability

Device capability:max payload等
Link capability:supported link speed/width, current link speed, negotiate link widthdeng 。
PCIE extended capability

包含VC/TC mapping table和端口、VC仲裁策略。
端口仲裁和VC仲裁
VC(virtual channel)
Virtual channel:端口上一般都会采用virtual channel的技术来缓存不同ingress port发来的数据。Virtual channel就是buffer,缓存数据。最多8个VC。
数据在Switch中传输,涉及到VC/TC mapping、端口仲裁、VC仲裁。
TC/VC mapping

Arbitration

端口仲裁:当有多个ingress port的 数据包用同一个VC的时候,决定哪个port使用该VC。
VC仲裁:在egress port上,有多个VC,仲裁决定哪个VC从egress port发出,也就是占用link。
Transaction layer
TLP格式

TLP Header
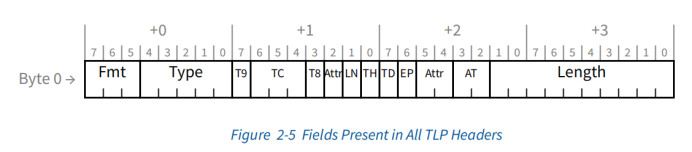
TLP 类型
Fmt和Type两个字段决定TLP类型。
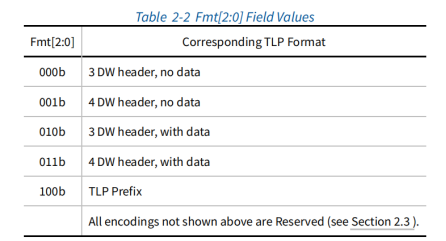
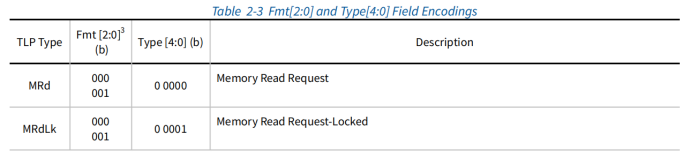
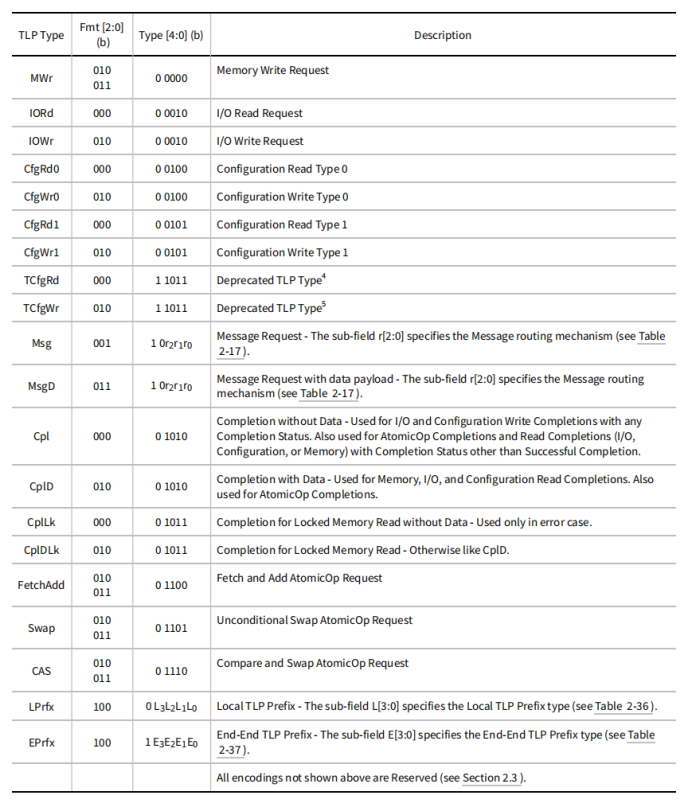
主要有五种访问类型:存储器、I/O、配置、message、原子操作。
存储器、I/O、配置读请求;不带数据
存储器、I/O、配置写请求;带数据
存储器、I/O、配置读完成;带数据
I/O、配置写完成;不带数据
消息请求;带数据或不带数据
原子操作:swap、CAS
三种TLP路由方式
地址路由
通过地址来定位目标设备,用在memory和I/O 请求中。
在Switch的PCI-to-PCI bridge的配置空间中有I/O address、limit和memory address、limit,用来判断地址是否在bridge的访问空间内。
在TLP header中就会有地址字段。

ID路由
通过ID来定位目标设备,用在配置读写请求和完成报文。
ID是由bus number, device number和function number组成的。

PCI-to-PCI bridge的配置空间中会有primary bus number, secondary bus number和subordinate bus number。Primary bus number是bridge上游bus number,secondary bus number是下游第一个PCI bus number,subordinate bus number是下游最后一个bus number。
隐式路由
用在message报文中,要么是发向RC,要么是从RC广播。
Data link layer
data link layer作用
数据交换
接收事务层TLP并转发到物理层;
从物理层接收TLP转发到事务层。
初始化和电源管理的作用:
接收来自transaction layer的电源状态请求,并将他们传递给physical layer。
将active/reset/disconnected/power managed state传给transaction layer。
数据保护、错误检查、重试:
CRC生成。
为了重试机制,保存发送的TLP。
错误检查
TLP应答和retry messages。
错误报告和打印。
组成
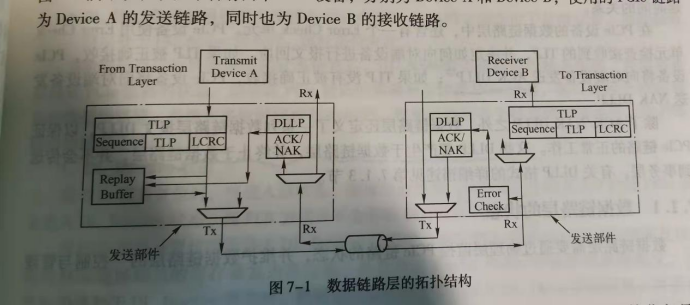
数据链路层通过ACK/NAK协议发送和接受TLP,主要包括发送部件和接收部件。
发送部件包括Replay buffer、ACK/NAK DLLP接收逻辑和TLP发送逻辑。
接收部件包括Error check逻辑、ACK/NAK DLLP发送逻辑和TLP接收逻辑。

链路层状态机
链路层通过data link control and management state machine(DLCMSM)来控制链路状态,并且在事务层和物理层之间传递链路状态。

链路层从物理层获取link上的状态,如下:
DL_Inactive: 物理层向链路层报告当前PCIE链路不可用,对端没有连接人和设备,或者没有检测到对端的设备。
DL_Feature(optional):物理层报告当前链路可用,进行data link feature exchange(这些feature保存在capability结构中。)
DL_Init:物理层通知链路层当前PCIE链路可用,正在对VC0进行流量控制。当前链路层不能接收或者发送TLP和DLLP。
DL_Active:当前PCIE链路处于正常工作状态。
链路层向事务层报告link上的状态,如下:
DL_Down:告知事务层,当前link处于DL_Inactive状态,没有从对端检测到设备。
DL_Up:告知事务层,link上检测到对端设备,正在跟对端的设备进行数据链路层交流。也就是link处于DL_Active状态。
Link状态跳变过程如下:
DL_Incative:当hot, warm, cold reset之后,link进入DL_Inactive状态;当时FLR reset不能。
在这个状态下,所有跟链路层状态机有关的信息都被复位到默认值;retry buffer中的数据丢失。
链路层向事务层报告DL_Down状态,事务层接收到DL_Down之后,会丢弃所有的outstanding transaction,停止发送TLP。
链路层本身会丢弃TLP相关的信息,停止生成和接受DLLP。
DL_Inactive -> DL_Init的情况有两种:
端口不支持DL_Feature特性,软件没有disable当前link,物理层报告LinkUp 状态位为1(表示对端接入设备).
端口支持DL_Feature,但是被软件disable;软件没有disable当前link,物理层报告LinkUp 状态位为1(表示对端接入设备).
DL_Init:改状态分为两个子状态:FC_INIT1和FC_INIT2。在INIT1阶段,向事务层报告DL_Down状态,在FC_INIT2阶段,报告DL_Up状态。
在端口处于DL_Down状态的时候,接收端会丢弃那些接收到的但没有去应答的TLP。
DL_Init ->DL_Active:当流量初始化完成,并且物理层LinkUp为高,进入DL_Active状态。
DLLP报文
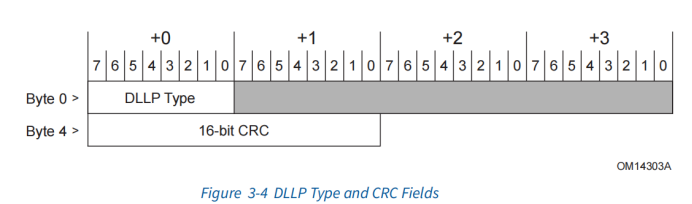
DLLP主要分为:
ACK
NAK
电源管理DLLP
流控DLLP
Vendor-defined DLLP


ACK/NAK应答机制
参考《PCIE体系结构导读》7.2章节。
发送端和接收端通过sequence number来标记报文。
接收端不会为每个报文回复应答。如果发送端发送了3-5 sequence number报文,接收端NAK应答中的AckNak_Seq_Num是4,说明报文3-4已经被成功接受。
链路层发送报文的顺序
TLP、DLLP和物理层报文PLP都会使用同一个物理link发送报文,他们之间的顺序是有要求的,一般发送中的报文优先级最高,越是底层的报文优先级越高。
优先级从高到低如下:
正在传输的TLP和DLLP。
PLP。
NAK DLLP
ACK DLLP
重新发送replay buffer中的TLP
其他在事务层等待的TLP。
其他DLLP。
Physical layer-逻辑子层logical sub-block
4.1 逻辑子层结构图
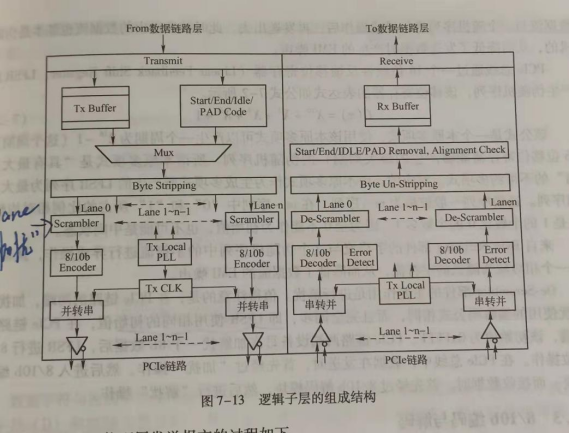
Byte striping/un-striping
将数据分到不同的lane上,或者从多条lane上合并数据。
会进行de-skew操作。
Scrambler、de-scrambler 加扰
加扰:通过线性反馈移位寄存器LSFR产生伪随机序列,数据跟这个伪随机序列进行异或操作。
作用:防止信号有某些固定的重复值,降低EMI干扰
8/10b编码 2.5GT/s 5.0GT/s
8/10b
为了0、1均衡,如果在一个高速链路上有较多连续的“1”,会将AC耦合电容充满,从而影响这些电容正常工作。
连续传输的0或1不会超过5个。
保证每十位中最多有6个0或者6个1.
但是仅仅如此还不够,可能10位中连续是6个0或者1,那么0或1就会聚集。所以有了CRD(current running disparity),每个byte(symbol)的编码都有两个,一个0多,一个1多
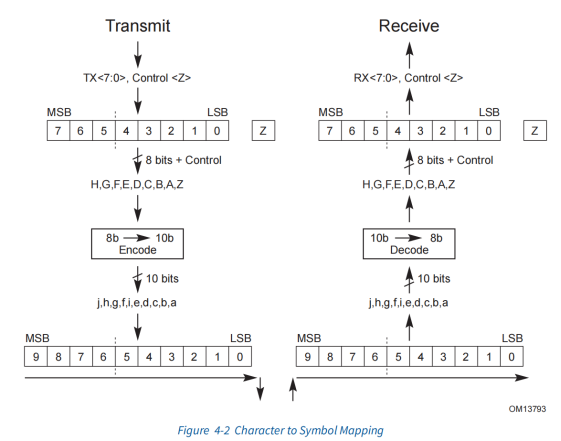
传输
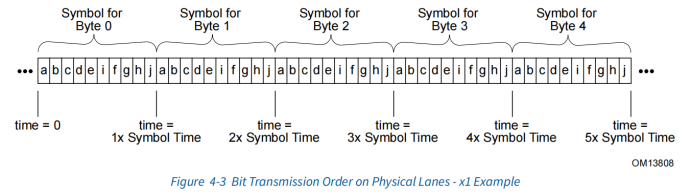
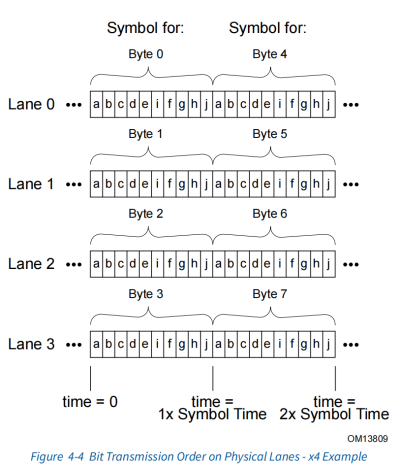
Symbol
编码结果可以通过Dxx.y和Kxx.y表示,前者表示数据字符,后者表示控制字符。
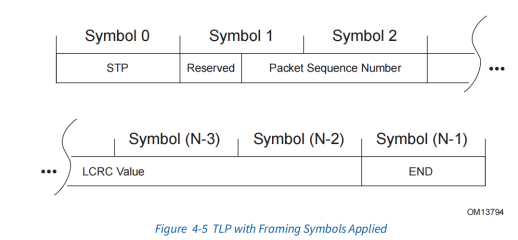
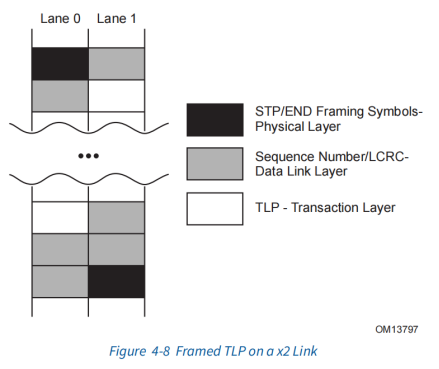
Figure4.5中,在TLP前面加上STP symbol,在TLP后面加上END,分别表示TLP的开始和结束。
在figure 4.6中,在DLLP前面加上SDP,后面加上END。

加上TLP,DLLP的开始符号和结束符号之后再进行byte-striping。
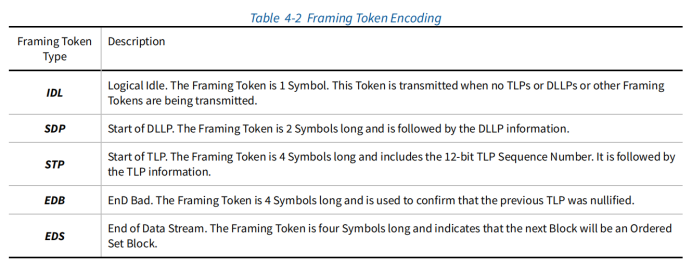
128/130b 编码 8GT/s
每个symbol是8bit。
每条lane上传输sync bit。

两位Sync bit
‘b10代表是data block。
‘h01代表ordered set block
Ordered set block
在所有的lane同时传输相同的ordered set block。
Data block
Data block 包括framing token、DLLP、TLP。
Framing token类似于8/10b编码中的控制符号。

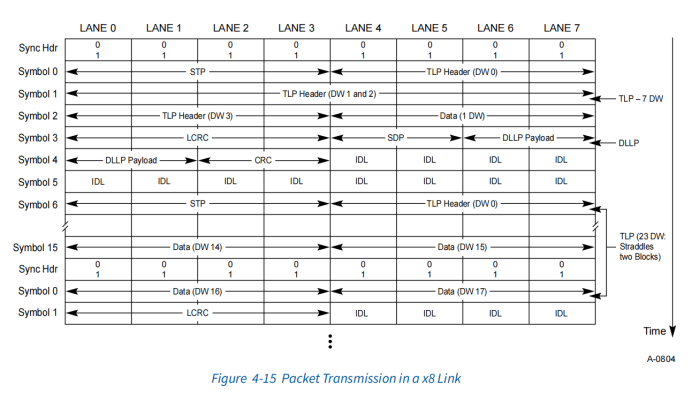
传输
传输TLP和DLLP
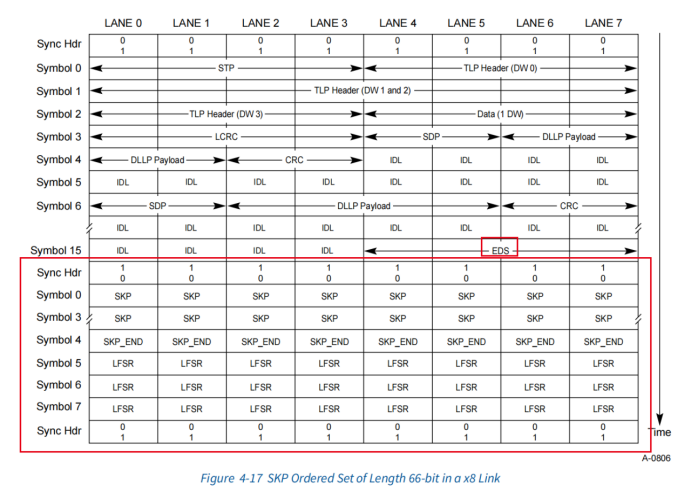
EDS framing token之后代表要传输ordered set block,从下图figure4.17中可以看出,所有lane上传输的ordered set block是相同的。
Physical layer-电气子层electrical sub-block
Power management














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









