







本文由MIT学者发表
-
论文简介
本文主要讨论了自动驾驶车辆与人类司机的互动。算法大框架是博弈论,用迭代最优响应求解。创新点在于引入了社会价值取向,其目的是模仿人类驾驶汽车与自动驾驶车辆的互动,结果或者说算法优越性体现在同等时间内prosocial版本的行驶距离比egoistic的距离更长。
本文将控制问题描述成一个带约束的优化问题,博弈论本身不处理约束,于是在迭代最优响应的每一步迭代用分布式MPC来求解,则求得的均衡值必定满足约束。此时博弈问题的动作是一个加速度和转向角的序列。
这里我的理解是,这个解并不一定是原博弈的全局最优解,甚至不一定是原来的局部最优解,但是是一个能满足约束,同时避免一人撞毁一人高速通行这样的状况的,比较好的解。
本文不考虑通信,对每一辆车而言,别的车的状态直接从底层代码储存区获取。
-
结果分析
文中没有详细阐述支撑该算法的收敛性的理论(引用文献里有),于是用结果证明两轮迭代后基本收敛。
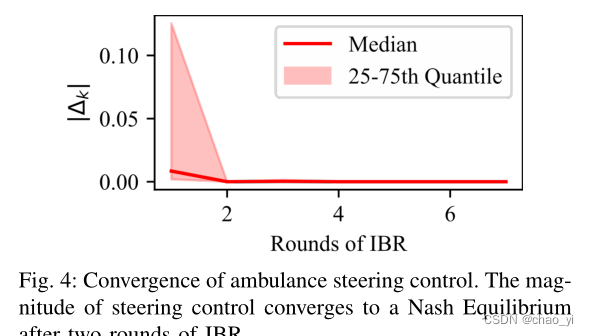
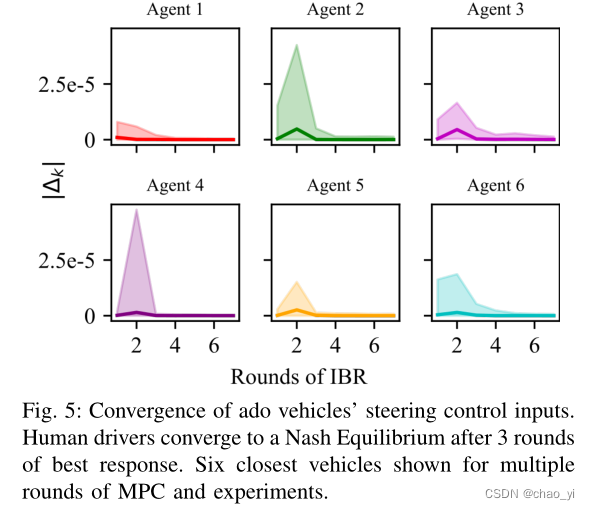
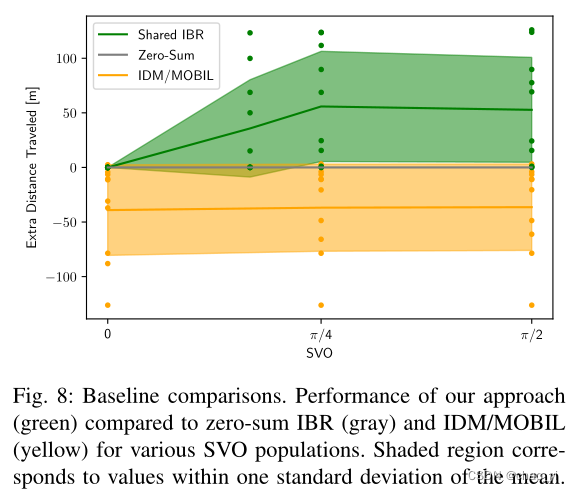
与baseline相比如下图。其中MOBIL中的礼貌因子对应不同的SVO,MOBIL的转向由MPC解决。由图可以看出 1.社会价值取向能够增大相同时间内的行驶距离。 2. 优越性:Shared IBR > 零和博弈 > IDM/MOBIL
车辆浓度对该实验的影响:

原文源码链接















 1862
1862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









