









 本文介绍了Focaler-IoU,一种新的边界框回归损失函数,它结合IoU和Focal Loss,动态调整不同难度样本的权重,提高目标检测的定位精度。实验证实在YOLOV8上应用Focaler-IoU后,mAP50和mAP50-95有显著提升。
本文介绍了Focaler-IoU,一种新的边界框回归损失函数,它结合IoU和Focal Loss,动态调整不同难度样本的权重,提高目标检测的定位精度。实验证实在YOLOV8上应用Focaler-IoU后,mAP50和mAP50-95有显著提升。
摘要
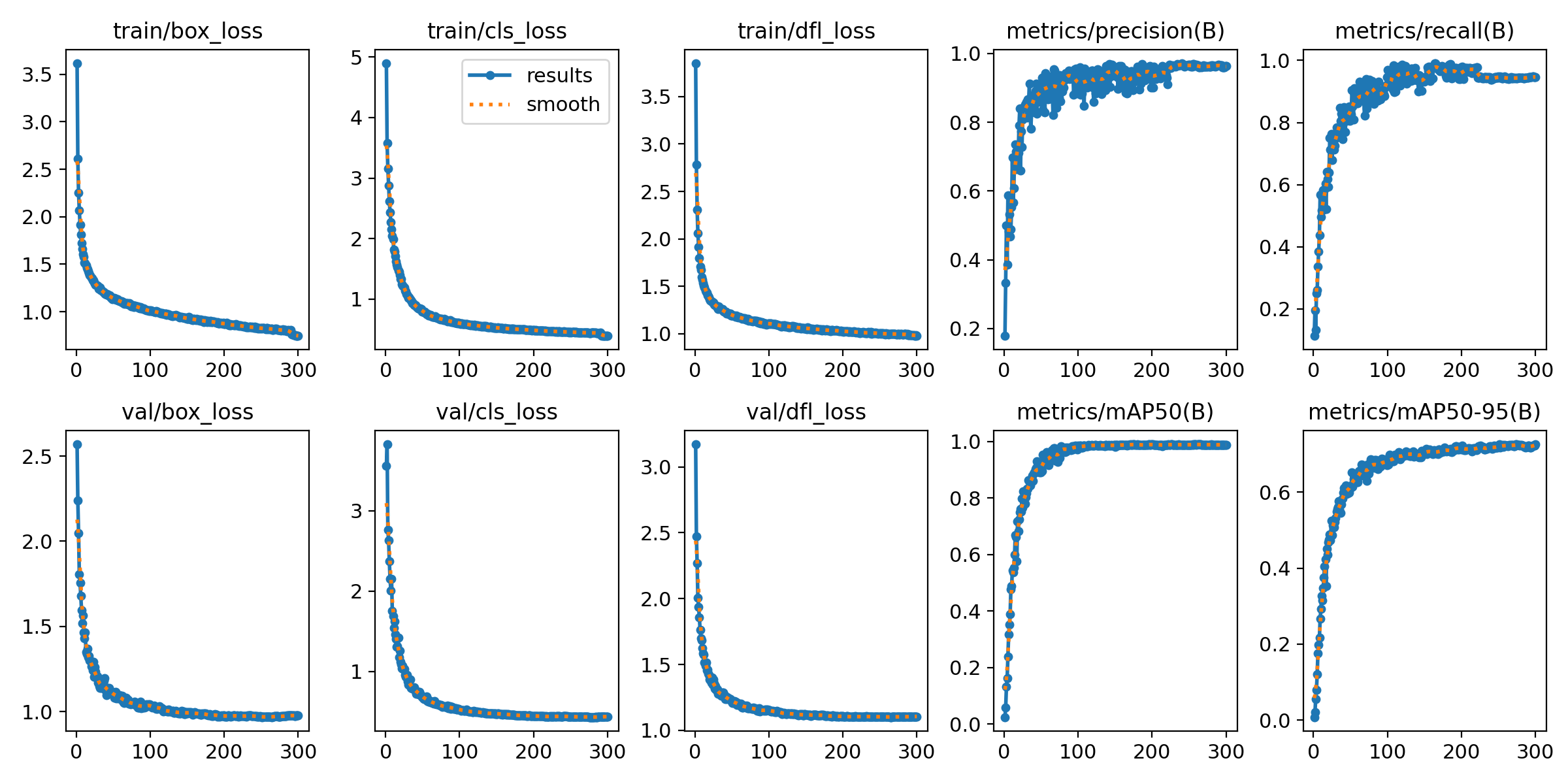
涨点效果:在我自己的数据集上,mAP50 由0.986涨到了0.99,mAP50-95由0.737涨到0.753,涨点明显!
目标检测是计算机视觉的基本任务之一,旨在识别图像中的目标并定位其位置。目标检测算法可分为基于锚点和无锚点的方法。基于锚点的方法包括Faster R-CNN、YOLO系列、SSD和RetinaNet等。无锚点方法包括CornerNet、CenterNet和FCOS等。在这些检测器中,边界框回归损失函数作为定位分支的重要组成部分,起着不可替代的作用。
本文提出了一种新的边界框回归损失函数Focaler-IoU,该函数能够关注不同难度的回归样本,并动态调整样本权重以优化回归性能。Focaler-IoU结合了IoU(Intersection over Union)和Focal Loss的思想,通过引入一个可学习的关注因子来调整不同样本的权重。在训练过程中,关注因子会根据回归结果动态调整,使得回归器更加关注那些对定位精度影响较大的样本。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











